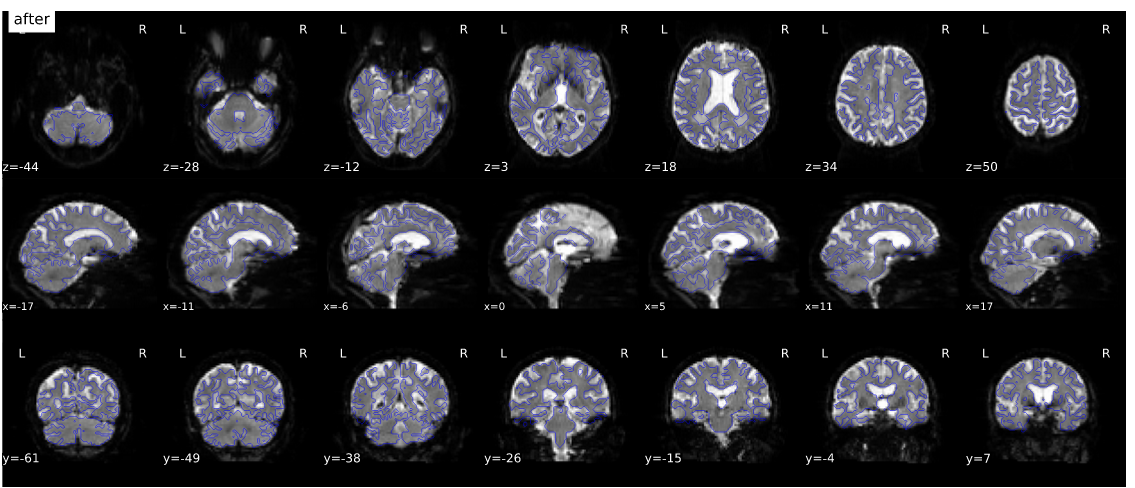
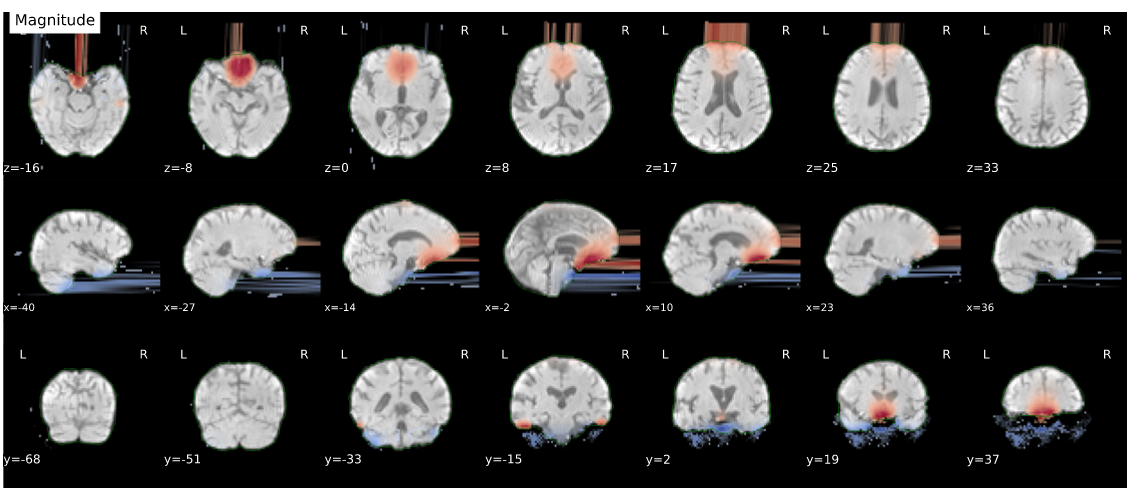
I can confirm that there was a major regression in the SDC processing for (in my case) the phase difference field map method. The good news is rolling back to 20.2.7 as suggested worked well for me. I ran with 20.2.7, 22.0.2, 22.1.1. There was a small improvement from 22.0.2 to 22.1.1, but both still had gross errors, while 20.2.7 gave very clean results. I’ve included examples from 20.2.7 and 22.1.1
First version 22.1.1 showing gross distortions:
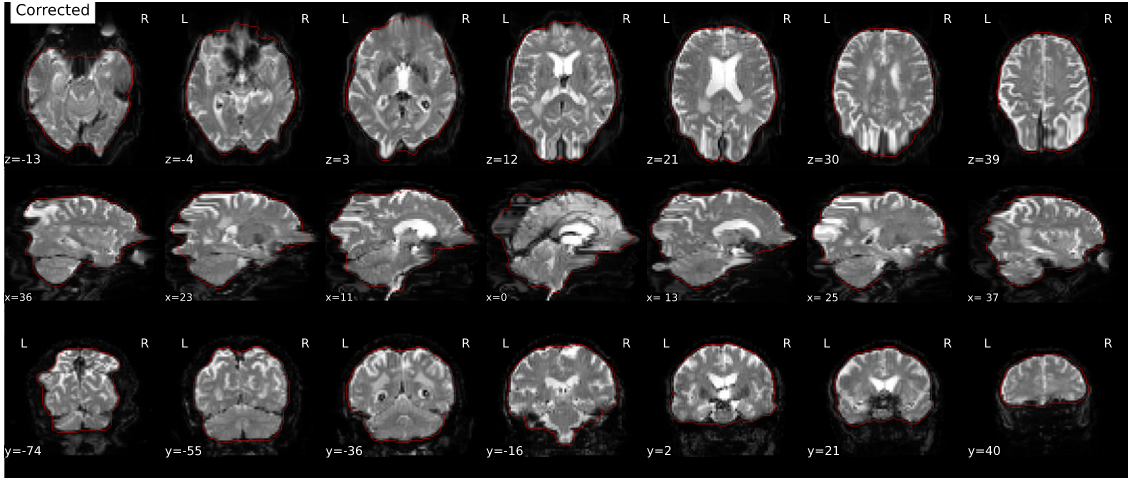
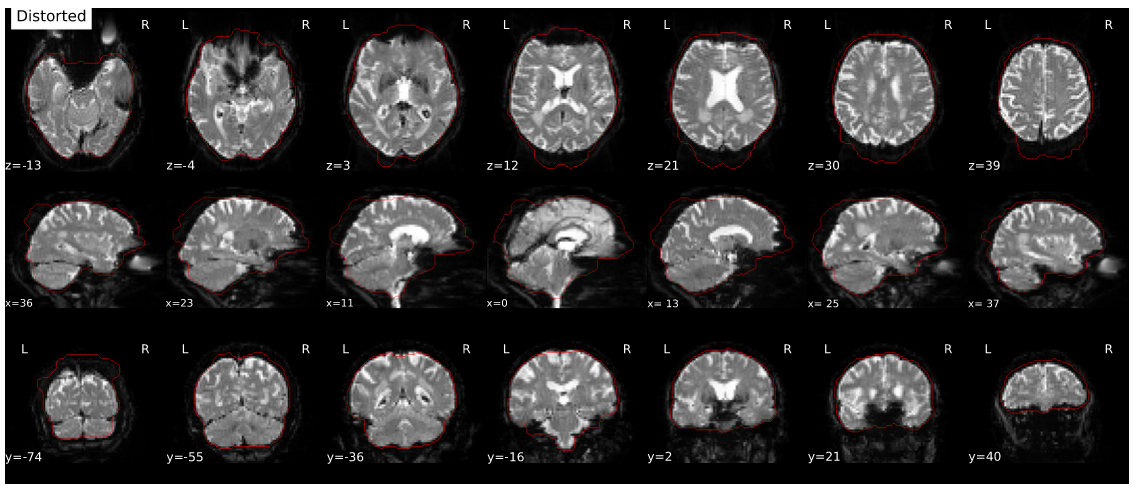
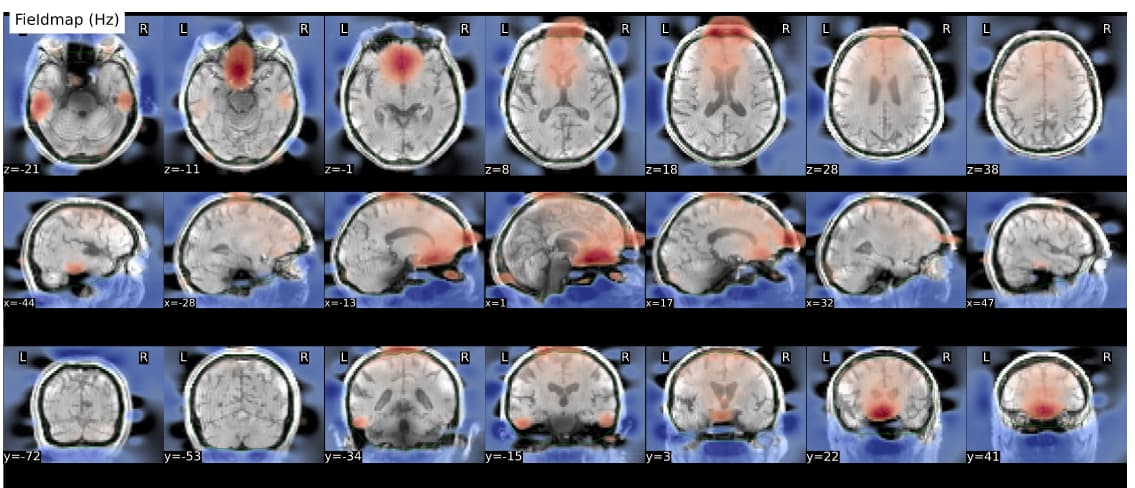
Second version 20.2.7 of the exact same data showing normal results: