Hi Visakh,
Would you prefer using something like FastAPI or Flask to create a backend for the chatbot? Or would you be interested in bundling the entire functionality with the streamlit or gradio code? I have experience with building an end-to-end RAG based chatbot with langchain and I think I can contribute in building the chatbot. Thanks in advance!
I’m Abhishek, currently pursuing my Master’s in Computer Engineeringwith a focus onMachine Learning at Virginia Tech. Before starting grad school, I worked as a Software Engineer at an ML-focused firm for two years. My experience includes building APIs and developing user interfaces, particularly for chatbot applications.
I came across the Build an AI Agent for KnowledgeSpace using RAG project and found it closely aligned with my interests and experience. I’m currently involved in a research project focused on developing a reasoning model using Retrieval-Augmented Generation (RAG), and I believe I could meaningfully contribute to this initiative.
I’ve attached my resume and portfolio for your reference.
My name is Mohamed Awad, a fourth-year undergraduate student at CUNY Queens College studying computer science in New York City. I have a strong interest in LLM, machine learning, and NLP. I have demonstrated proficiency in Python with hands-on experience in ML, RAG, and other Python libraries, such as Numpy, Pandas, and Pytorch. Recently, I have done ML research where I analyzed thousands of images to classify signs of skin cancer. My skill set also includes web development from tools like JS, React, Node.js, Git, APIs, AWS, and Firebase.
I came across this project “Build an AI Agent for KnowledgeSpace using RAG” and I found it interesting that in a world of LLMs, the models themselves need to be accurate, fast, and up-to-date with the relevant context. With my knowledge in RAG, NLP, and LLMs, I believe I can make meaningful contributions for this project and feel that neuroscience data would be structured and accessible to community members.
I am dedicated to commit at least 350 hours to this project given my background in AI and web development. I have developed a strong ability to learn quickly and adapt to technologies, allowing myself to make contributions that benefit the entire KnowledgeSpace community. I’m wondering if you could guide me with any resources to get started before getting into the nitty-gritty of this project.
I’m currently a third-year computer science PhD at UMass Boston, researching bias mitigation and fairness enhancement in Recommender Systems (RS). In my research, I’m also experimenting with LLMs to uncover the black box nature of RS. I wanted to utilize my summer learning and contribute meaningfully and I found the “Build an AI Agent for KnowledgeSpace using RAG” project interesting and close to my research and interests.
I’ve worked with RAG and chatbots in past academic projects and also got to explore AI agents through hackathons at the MIT/Harvard club. Through these hackathons, I came across a tool called Maestro by AI21 Labs. I believe the problem of creating an AI agent for KnowledgeSpace would need a similar approach where the Agent dynamically plans the task based on the user query and makes an execution plan to retrieve correct data effectively.
Additionally, I read that you are looking for someone to build the chat interface with conversational memory. For that, I’ve had some experience in the past where I’ve worked in Web Development and can create a chat interface similar to ChatGPT, Deepseek, etc. Also, as part of the academic project where I worked on a RAG-based chatbot, we worked on a Conversational pipeline to save and tailor the LLM response based on the conversation history.
I would love to get this conversation going and am looking forward to your response.
PS: attaching my resume for you to get a better understanding of my skills. Resume
I’m Rishika, a third-year CSE undergrad with a strong interest in AI and backend development. I recently built a WhatsApp chatbot for the 2025 Indian elections as part of a government-backed project, handling large-scale queries on AWS with NLP-based retrieval and optimization techniques. Through that, I worked on efficient retrieval methods, prompt engineering for factual accuracy, and scalable caching strategies—which directly align with the challenges in this project.
I know I’m joining the discussion a bit late, but the work you’re doing with RAG and conversational memory in KnowledgeSpace is incredibly exciting! I had a quick question regarding the retrieval pipeline:
Are we looking at a hybrid memory approach, combining vector search (FAISS/Qdrant) with structured storage for long-term context, or are we optimizing more for short-term recall with token-window-based solutions? Also, given the neuroscience domain, what trade-offs are we considering in retrieval—speed, storage constraints, or something else?
Really looking forward to your insights and excited to contribute.
Datasets are metadata from large neuroscience data repos together with curated ontologies in NIFSTD.
The agent can provide concept definitions and provide results on relevant datasets. The metadata schema for each datasets/sources in not standardised, but the llm can be quite useful to retrieve relevant information there.
I hope you’re doing well. I’m writing to express my strong interest in the GSoC 2025 project: “Build an AI Agent for KnowledgeSpace using RAG.”
Thank you for the recent update clarifying that the RAG backend is already underway. I’m genuinely excited to hear that! Based on your guidance, I’ve begun exploring the development of a chat interface with conversational memory, which will integrate with the existing RAG system and enhance KnowledgeSpace’s usability.
Over the past few days, I’ve:
Researched and experimented with frontend chat UIs using React
Explored how conversational memory can be built using LangChain concepts (e.g., buffer memory and context windows)
Studied how vector stores and graph databases like Neo4j might support long-term memory or structured metadata retrieval
I understand that metadata across datasets is not standardized, and I see the huge potential of using LLMs to bridge this gap by providing accurate, contextual answers through a conversational experience. I’m also beginning to experiment with model deployment on Vertex AI, as mentioned in the project scope.
Attached is a mockup that showcases my early thoughts and interface concept. I’d love your feedback and would be happy to iterate or prototype further based on your suggestions.
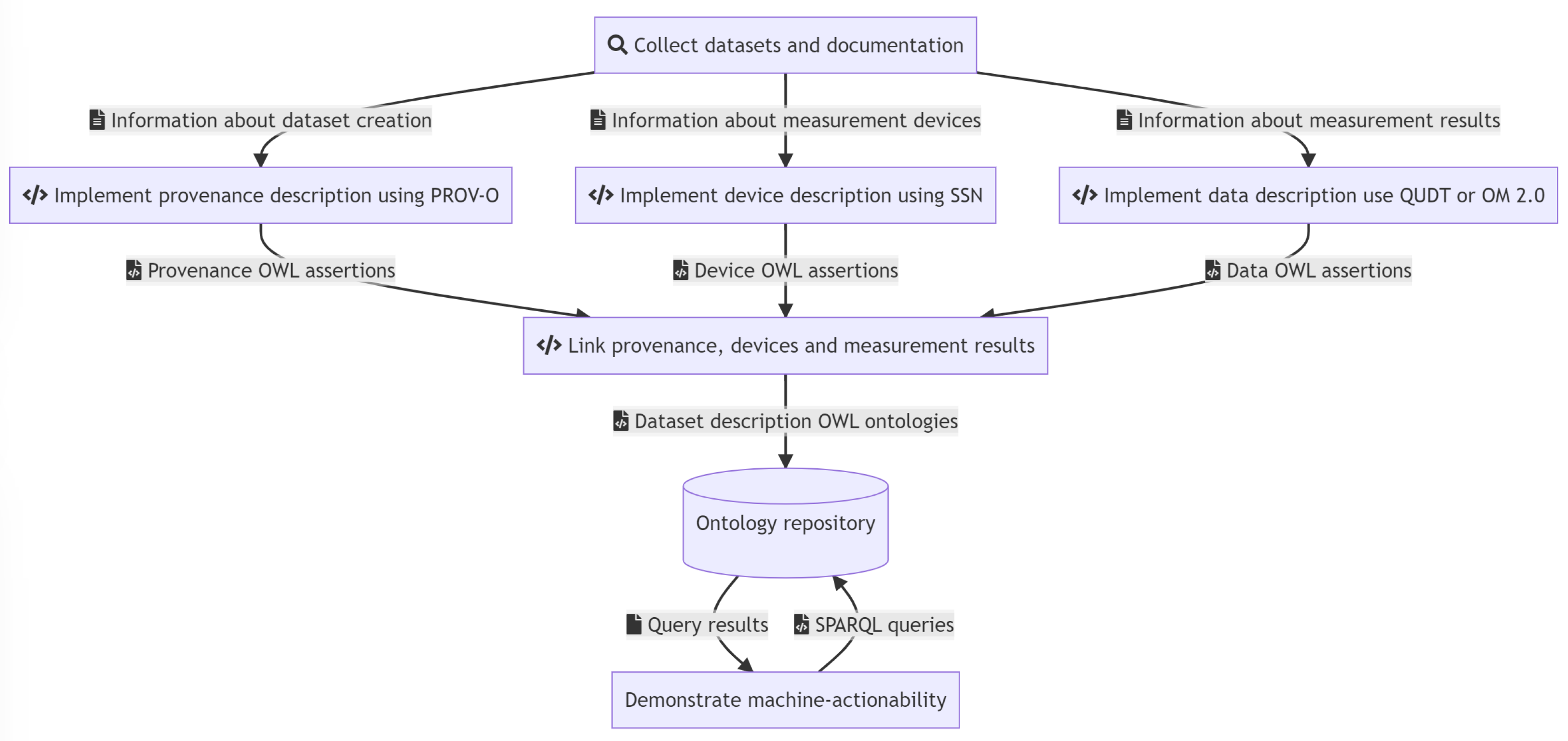
Understanding Metadata Structure in KnowledgeSpace To effectively enable contextual responses and relevant dataset retrieval in the AI agent, I studied the existing metadata structuring pipeline. The diagram below outlines how dataset provenance, measurement device data, and results are formalized using OWL ontologies and stored in an ontology repository. My proposed conversational UI will interface with this layer to provide accurate, ontology-powered search and interaction.
I’m currently drafting my full GSoC proposal and would be honored to collaborate on this project under your mentorship.
I am Tao He, currently an MSCS Align student at Northeastern University(Boston). I’m credibly excited about the KnowledgeSpace RAG project and would love to contribute as a GSoC contributor…
What draws me to this project is its rare intersection of AI, knowledge retrieval, and neuroscience—areas I’m now deeply passionate about. I’ve worked on multiple end-to-end NLP and ML projects, including:
A comparative time-series modeling research (ARIMA vs SVR) published with Taylor & Francis
A document-level sentiment classification project using an improved BiLSTM with attention (accepted at ICDSE 2024)
A solo-built full-stack prompt-sharing platform Promptllery using React + Supabase, demonstrating my frontend/backend + user-centric design skills
UI/UX for querying and interacting with neuroscience data
Fine-tuning LLM outputs for clarity and domain relevance in the RAG pipeline
As someone transitioning from economics and public policy into CS and AI, I bring not only technical curiosity but also a deep respect for the complexity of domain knowledge—especially in fields like neuroscience.
I’d love the opportunity to dive deeper into the problem scope and propose a concrete implementation plan if selected. Thank you for considering my interest!
Hello @visakh
I’m Rishee, a Computer Science undergrad with a strong interest in LLMs, multi-agent systems, and Retrieval-Augmented Generation (RAG). I’ve worked on projects using Gemini, Pinecone, LangGraph, and built custom logic with LangChain and HuggingFace. I’m comfortable with Python and have experience in prompt engineering, RAG evaluation, and LLM observability.
Recently, I built a RAG pipeline without using any orchestration tools, implementing everything from scratch chunking, embedding, vector search, and response generation. I’ve documented the process in this blog post. I also created a context aware medical chatbot using Gemini and Pinecone, with a full-stack deployment via Flask. link here
I would love to contribute to issues and do tasks to get more familiar with the project. It would be really helpful if you guide me.
I know im a bit late to join the party, but im willing to give my best in this project.
My name is Navanish Pandey, and I’m interested in contributing to the KnowledgeSpace Chat Agent project under INCF.
I have already set up the full project locally (backend + frontend + API integration), and I want to start improving it by fixing issues and adding useful features.
Before I begin, I wanted to ask:
Who is the current mentor or maintainer for this project?
Is there a preferred way to reach out to them for discussing ideas, issues, or improvements?
Is the project still active and open for contributions outside the GSoC period?
I’m genuinely interested in contributing to this project long-term and preparing myself for GSoC 2026 with INCF.
Any guidance from your side will really help me get started in the right direction.
My name is 𝐑𝐮𝐝𝐫𝐚. I am a Full-Stack AI Developer specializing in the 𝐅𝐚𝐬𝐭𝐀𝐏𝐈 + 𝐑𝐞𝐚𝐜𝐭 + 𝐋𝐚𝐧𝐠𝐂𝐡𝐚𝐢𝐧 stack.
I am highly interested in 𝐏𝐫𝐨𝐣𝐞𝐜𝐭 #𝟐𝟎 (𝐁𝐮𝐢𝐥𝐝𝐢𝐧𝐠 𝐚𝐧 𝐀𝐈 𝐀𝐠𝐞𝐧𝐭). I have my End-Semester exams until 𝐃𝐞𝐜 𝟏𝟔, but I wanted to share a quick proof-of-concept I built today to test the data retrieval architecture.
𝗛𝘆𝗯𝗿𝗶𝗱 𝗦𝘁𝗮𝗰𝗸: A React frontend connected to a Python/FastAPI backend (simulated).
𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗖𝗵𝘂𝗻𝗸𝗶𝗻𝗴: Instead of naive character splitting, I wrote a custom ingestion pipeline that detects scientific headers (e.g., “Pathophysiology”, “Methods”) and uses “sticky metadata” to ensure every chunk retains its context.
𝗖𝗶𝘁𝗮𝘁𝗶𝗼𝗻-𝗥𝗲𝗮𝗱𝘆: The system retrieves specific page numbers and section names to prevent hallucinations.
I will be fully available to start contributing code and discussing the 𝐍𝐞𝐨𝟒𝐣 + 𝐋𝐚𝐧𝐠𝐆𝐫𝐚𝐩𝐡 integration starting 𝐃𝐞𝐜 𝟏𝟕
Best regards, Rudra
My name is Pratik Dhaktode, a second-year Computer Engineering student at PICT, Pune. I have a strong background in Deep Learning, Applied Maths, and LLM Agents, primarily working with Python and C++.
I am writing to express my strong interest in contributing to the KnowledgeSpace AI Agent. I have significant experience building RAG systems and recently won the Smart India Hackathon (SIH) solving a problem statement for ISRO, which gave me rigorous experience in delivering scalable AI solutions.
My Relevant Experience:
OceanGPT: Built a RAG + LLM chatbot with conversational memory (similar to the goals of Project #20).
Agentic AI: Developed a high-scale fraud detection system using Agentic workflows and Python microservices.
Tech Stack: PyTorch, LangChain, FAISS, and Vector Databases.
I have set up the repository locally and analyzed the ksdata_scraping.py workflow. I attempted to run the ingestion locally to understand the data chunking strategy, though I am currently blocked by the lack of access to the source Elasticsearch instance.
I noticed the current implementation relies heavily on vector search. Based on my experience with OceanGPT, I believe implementing a Hybrid Search (Vector + Keyword/BM25) approach could significantly reduce hallucinations when retrieving specific dataset names or technical terms.
I would love to work on this or any other priority tasks. Is there a specific branch or issue you recommend I tackle for my first PR?
Subject: Introduction: Contributor for KnowledgeSpace AI Agent (PR #5)
Hi mentors,
My name is Ravi Ranjan. I am a 1st-year Computer Science student with a strong interest in AI and open science. I am actively involved in the NASA OSDR and Cohere for AI communities, where I’ve been building my skills in data handling and LLMs.
I have been exploring the knowledge-space-agent repository to understand the backend architecture. I noticed a few discrepancies in the setup documentation (specifically regarding Windows activation paths and frontend port consistency), so I submitted PR #5 to fix these for future contributors.
I have also successfully set up the Gemini API in a local Python environment and am now reading through backend/main.py to understand how the agent handles context retrieval.
I’m Samridhi Raj Sinha, a final-year Computer Engineering student. I have experience in agentic RAG systems, LLM evaluation, and medical AI, gained through research internships at IIT Gandhinagar, Jio Platforms, and Nanavati Hospital.
I’ve successfully set up the agent locally and submitted PR #7, which fixes missing environment configuration that was blocking local setup for new contributors.
Proposal to unblock local development
Currently, backend/retrieval.py disables vector search when GCP credentials are missing, making it hard to test agent reasoning locally. I propose adding a lightweight MockRetriever that returns synthetic RetrievedItems, enabling local testing without private Vertex AI or BigQuery access.
I’m actively exploring the backend to implement this and plan to open additional PRs soon, including improvements to the search system such as enhancing fuzzy matching and filter-based search.
I’d also love to know if there are other areas where contributions would be most valuable right now.
Hi @sam22ridhi,
welcome to the project! Impressive background.
Your observation about retrieval.py blocking local development is spot on. I’ve been digging into the retrieval logic myself recently, and a MockRetriever would be incredibly useful for testing the agent’s reasoning without needing live Vertex AI credentials every time.
Looking forward to reviewing your PR #7. This will definitely help unblock the search improvements we need to make.
I’ve opened PR #10, which significantly upgrades the search pipeline by improving how we handle fuzzy matching and metadata. I am working on poc MockRetriever
Key Changes:
Switched to RapidFuzz: I replaced difflib with RapidFuzz. It’s significantly faster and handles token reordering (e.g., “human brain” vs “brain human”) much better than the standard library.
Structured Filter Extraction: Added a logic step where the LLM extracts specific filters from natural language queries (e.g., mapping EEG data to technique=EEG) rather than just treating everything as a keyword.
Bug Fix: Patched an edge case in KSSearchAgent where search variables could potentially remain uninitialized.
For testing, I ran local queries such as “EEG data”. The filters were correctly inferred, and relevant EEG datasets from EBRAINS and OpenNeuro were ranked higher, with end-to-end response times under ~4 seconds.
Hey @sam22ridhi
Great work on the RapidFuzz integration and structured filter extraction, this looks really solid
Quick context on the offline testing angle I mentioned earlier: while exploring the retrieval pipeline, I ended up implementing a Local Hybrid Search (BM25-based) in PR #6 that allows fully offline, deterministic retrieval over real data (no Vertex AI required).
The idea was to create a lightweight local fallback that mirrors real retrieval behavior, mainly to unblock local development and testing. I think this could pair nicely with your fuzzy matching + metadata logic on top.
Happy to sync or adapt things so they work well together if that’s useful