Hey Oscar,
Thanks for the info. I had another look with the nthreads option. I kept the memory allocation fixed at 64G. There seems to be a bit of an effect on processing speed for 4 vs 8 threads. But overall I think 1h is the lowest this thing goes in my case:
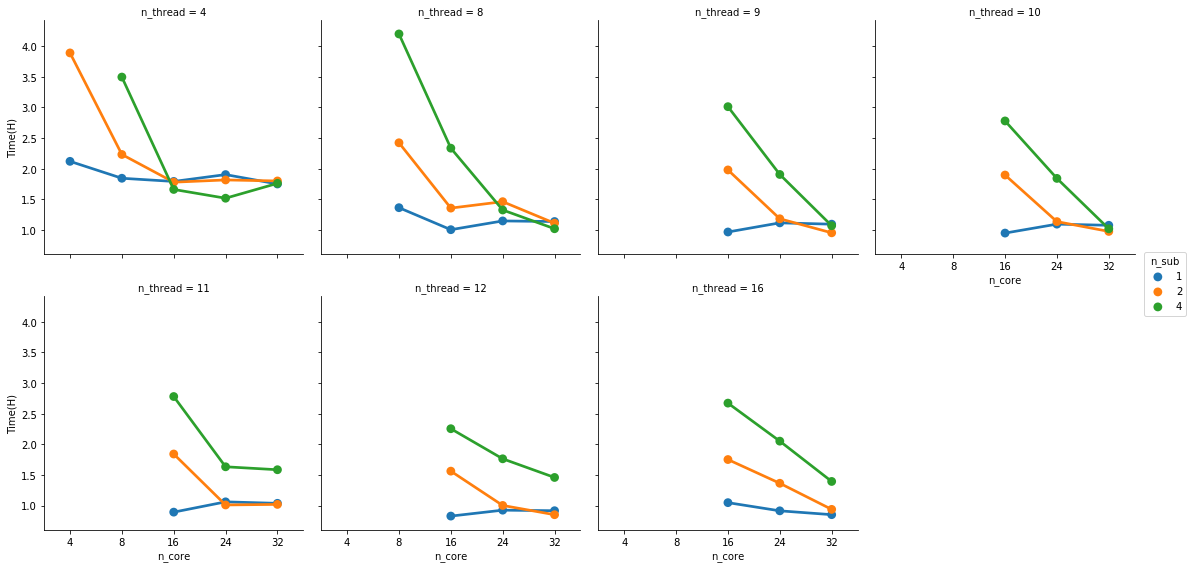
Not sure how stable the numbers for
nthreads > 8 are. They may well look the same if I kept running this again. But if not, something strange does indeed seem to happen around nthreads >= 10. For the 4 sample run, the runtime seems to converge towards 1.5 hours as opposed to 1h for the smaller samples. What is the default if nthreds is not set?
I had a look at the reported resource footprint. It seems that VMem scales more with the number of cores than the threads:
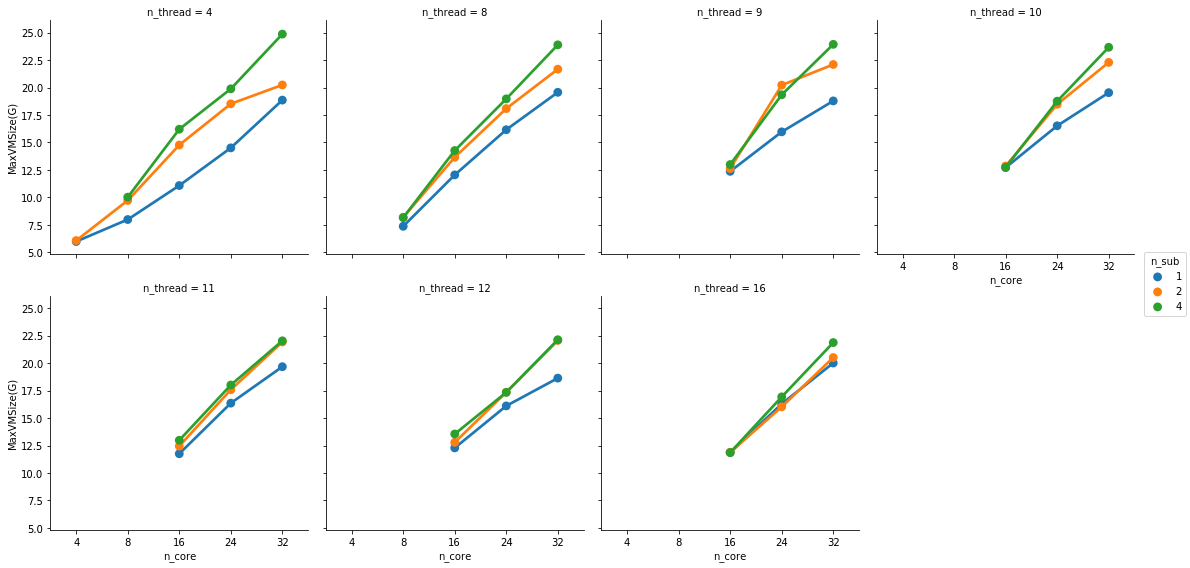
In fact, if you plot the the memory footprint over the number of parallel samples, it becomes clearer:
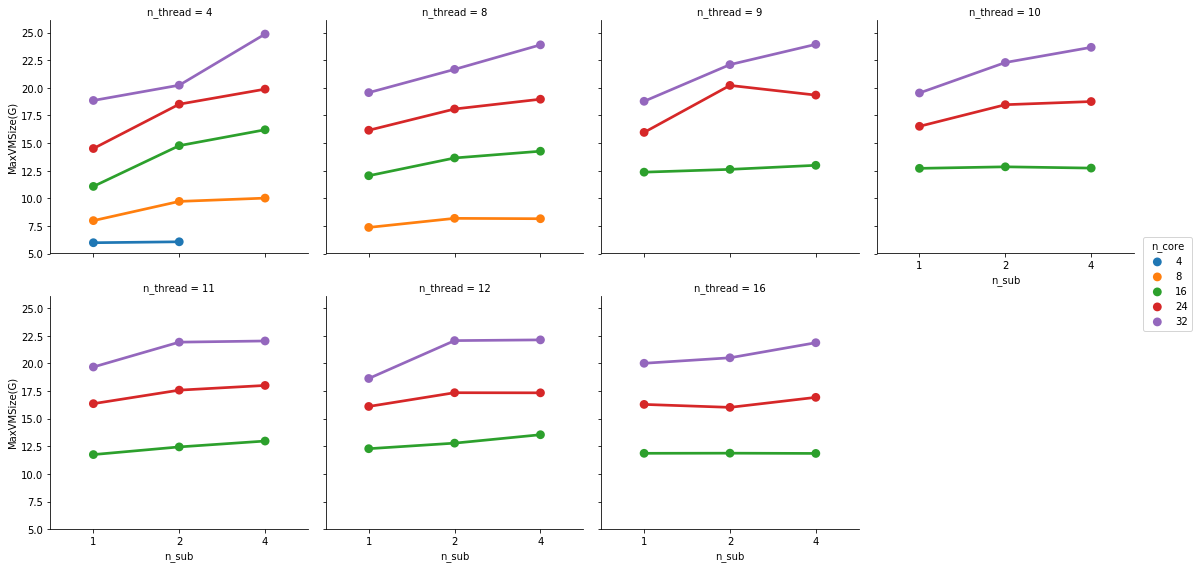
Not sure why that is. But it seems pretty stable. This is not (as much?) the case for physical memory footprint:
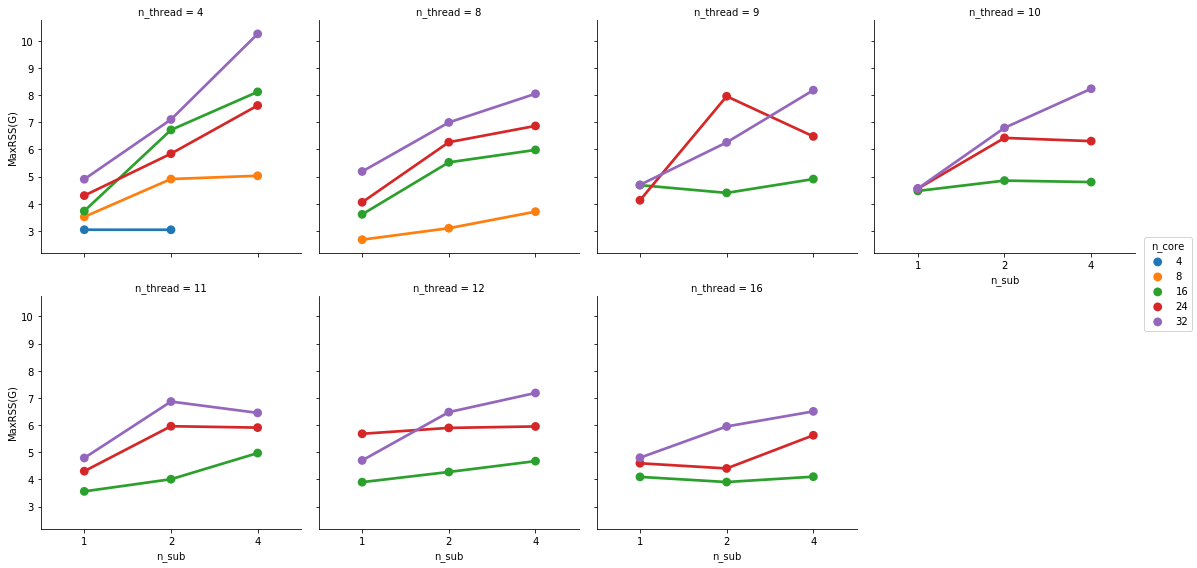
So I think what this tells me is that I am probably best off running one instance per subject and requesting 8 cores with 8 threads max and 10+safety G of memory. My compute nodes have 32 cores and 128G, so I can run 4 instances on one. While that’s probably a bit slower than running 4 subjects in parallel in one instance, I will get scheduled faster and I believe that the resource bill is also lower.
I uploaded the Benchmark data if you want to play around with it. Let me know if you want me to dump the full scheduler output for you somewhere.
Best,
Seb