I might need some clarification on 3dTproject as a lowpass filter :
I am running a MBME sequence with 4 echos and a TR of 4s.
The sequence runs label and control TRs for ASL.
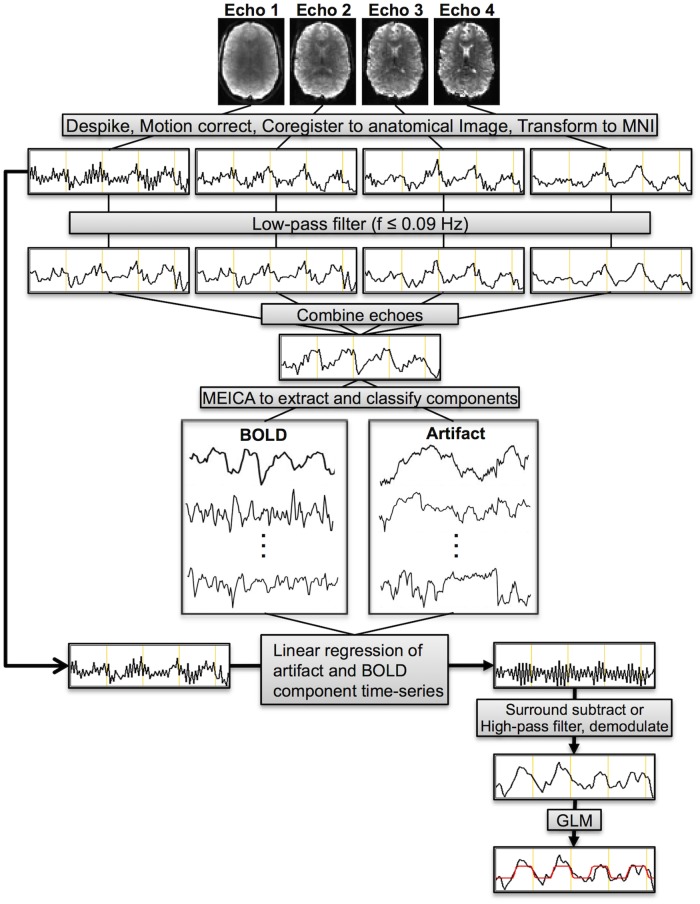
As proposed in this article, we are trying to filtre ASl from BOLD signal through lowpass filtering the BOLD signal (with 3dTproject -stopband 0.09 9999), combining with tedana, and substracting BOLD and artefacts components from the unfiltered data. see image below to better understand data processing
We are calibrating the sequence with a breathhold sequence (regression goes well on this run), then we are doing a task (hick’s task) but the tedana runs into errors :
"INFO pca:tedpca:228 Computing PCA of optimally combined multi-echo data with selection criteria: mdl
/home/mococo/anaconda3/lib/python3.8/site-packages/tedana/decomposition/pca.py:233: RuntimeWarning: invalid value encountered in true_divide
data_z = ((data.T - data.T.mean(axis=0)) / data.T.std(axis=0)).T # var normalize ts
INFO collect:generate_metrics:123 Calculating weight maps
/home/mococo/anaconda3/lib/python3.8/site-packages/scipy/stats/stats.py:2500: RuntimeWarning: invalid value encountered in true_divide
return (a - mns) / sstd
Intel MKL ERROR: Parameter 6 was incorrect on entry to DGELSD."
When I add the option -polort -1 to 3dTproject, it runs well.
Data will be run through 3dDeconvolve following these steps.
I don’t really know if it is advised when I only wish to lowpass the data to use polort -1 option on breathhold task as well as hicks.
Shall I carry on with -polort -1 option ?
Thanks for any help or advise regarding this prolem.
It is critical that the data passed to tedana still has the mean intensity in it, in other words, it should look like an EPI image of a brain, even if you have projected out the noise, bandpassed etc. Normally I would say the less you touch the data, the better, and that would mean: no MNI transformation, no low pass filter…but it may be an important step in this combined ASL approach, so lets continue.
If I understand correctly, polort -1 just means no polynomials are included - so is it correct to say that when you do the stopband you mention, and polort -1 you get out data that looks identical to the input data, except that it has been low pass filtered (so the timeseries looks different)?
If that is true, then it seems reasonable to proceed like that - but you would probably want to match what you are doing on the breathhold task. It is also not clear why it would work in one case but not the other.
The two most important thing is that the data that goes into tedana has not had any intensity change from echo to echo and that each echo has identical transformations applied to them. The first point requires that the mean of each echo isn’t removed, or that there isn’t any scaling done to the data.
Maybe someone else can chime in here with a little more knowledge about this ASL/BOLD approach or you could reach out to the original authors to see what they did?
We will run data through tedana to extract BOLD signal anyhow, so yes, untouched intensity signals are the best candidates.
The question was for a better way to extract ASL.
So I guess the less I touch it, the better. Indeed, if I don’t regress the polort out, the images look more like EPI images.
So I have applied the solution you proposed, and tedana seems to work fine.
The trouble now is that for both tasks, I cannot regress the
desc-optcomRejected_bold.nii.gz
and desc-optcomAccepted_bold.nii.gz from the original signal
from the command line :
3dTproject -input echo1 -dsort desc-optcomRejected_bold.nii.gz -dsort desc-optcomAccepted_bold.nii.gz -mask brain_mask.nii
I still get an output timeserie filtered dataset, which is weird.
If I want to regress the BOLD and artefcts signals out of my original signal I indeed have to regress Rejected and Accepted results from tedana right ?
edit : if I run every -dsort seperatly, it works, but not if both are done at the same time.
Is it a degree of freedom problem ?
From what I can tell, it seems to be because with multiple -dsort terms, svd is used to compute a pseudo-inverse of the projection matrix (if there is just one -dsort, this is not done). And the svd operations “fails” when one of the -dsort time series is identically zero. That might take some pondering…
Thanks for your reply.
Your analysis looks correct, but I have difficulties understanding the consequencies.
If I run the -dsort independantly, will it be a hazardous move ?
Could it be because the volumes are not square ?
In such case, should I be padding with zeros ?