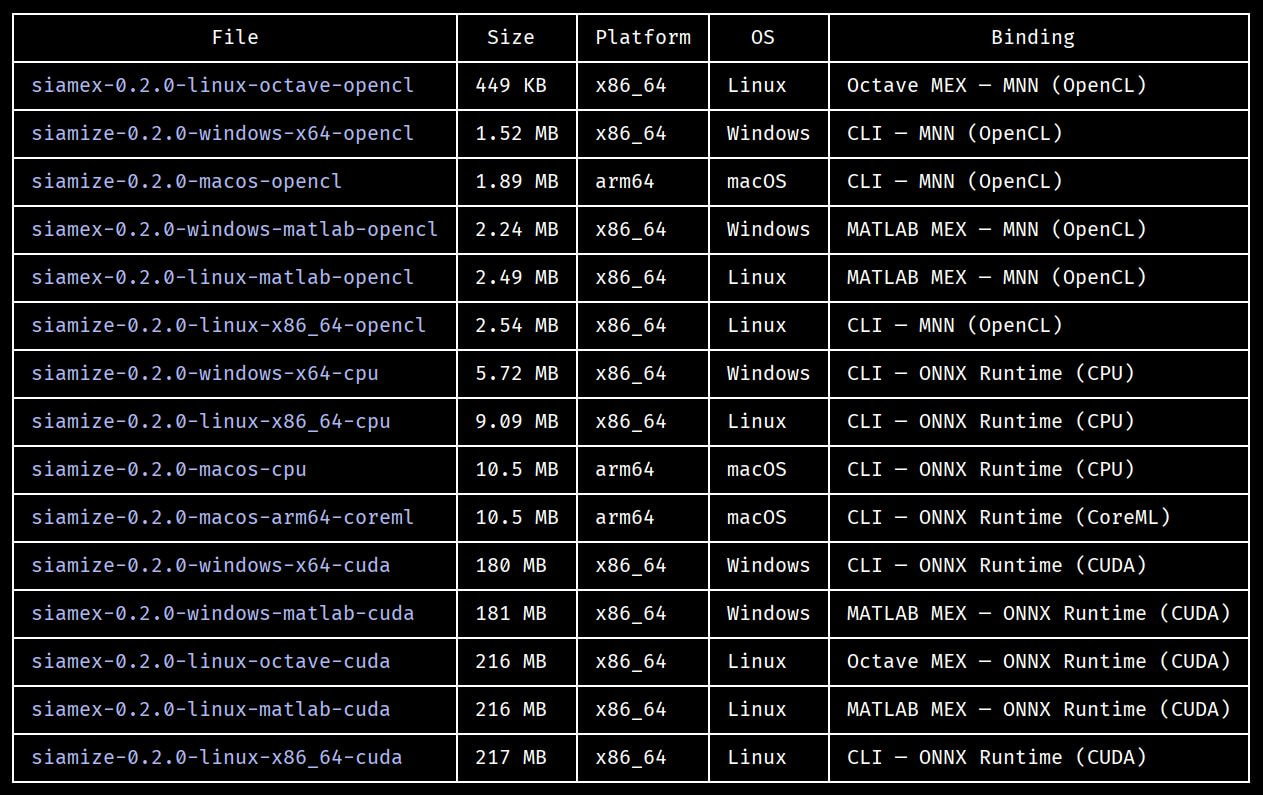
siamize ( GitHub - NeuroJSON/siamize: Native C++/ONNX port of SIAM v0.3 brain segmentation · GitHub ) is a recently developed native C++ port of SIAM - Segment It All Model ( GitHub - romainVala/SIAM: Full head segmentation · GitHub ).
It provides fast inference with GPU acceleration, supporting diverse hardware (CPUs, cross-vendor GPUs). It also contains a MATLAB/Octave interface for integration with MATLAB tools. Compared to the SIAM Python inference model, siamize also exposed the internal high-res 0.75mm segmentation and TPM maps.
Feature summaries and demos of the initial release (v0.2) can be found here
Docker image is also available at openjdata/siamize - Docker Image
docker pull openjdata/siamize:v2026.6
# NVIDIA GPU, ONNX Runtime / CUDA -- 5-fold ensemble (default entrypoint)
docker run --rm --gpus all -v "$PWD":/data -v siamize-cache:/cache \
openjdata/siamize:v2026.6 \
-i /data/in.nii.gz -o /data/labels.nii.gz -M 0,1,2,3,4 -c cuda
# Vendor-neutral GPU via MNN / OpenCL (NVIDIA / AMD / Intel)
docker run --rm --gpus all -v "$PWD":/data -v siamize-cache:/cache \
--entrypoint siamize-opencl openjdata/siamize:v2026.6 \
-i /data/in.nii.gz -o /data/labels.nii.gz -M 0 -c opencl
Running on the ONNX-CUDA backend, siamize can segment a full head scan (18 tissue types, 5-fold) for about 20 seconds on a 5090 GPU; it took about 1 min using an older Turning GPU (2080S).
the ONNX backend supports CUDA, TensorRT (2x faster than CUDA but initial run needs about 10 min), and CoreML on Apple silicon.
to simplify deployment, siamize also has an OpenCL backend, supporting nearly all OpenCL compatible CPUs and GPUs. The siamize-opencl binary can be as small as 1.5MB needing only OpenCL.dll/libOpenCL.so provided by the graphics driver. siamize-opencl gives full-speed on AMD/Intel GPUs, but it is about 2x slower on NVIDIA GPUs as nvidia OpenCL runtime does not support fp16 natively as the CUDA driver.
here are some screencasts showing siamize segmentation session
command line interface:
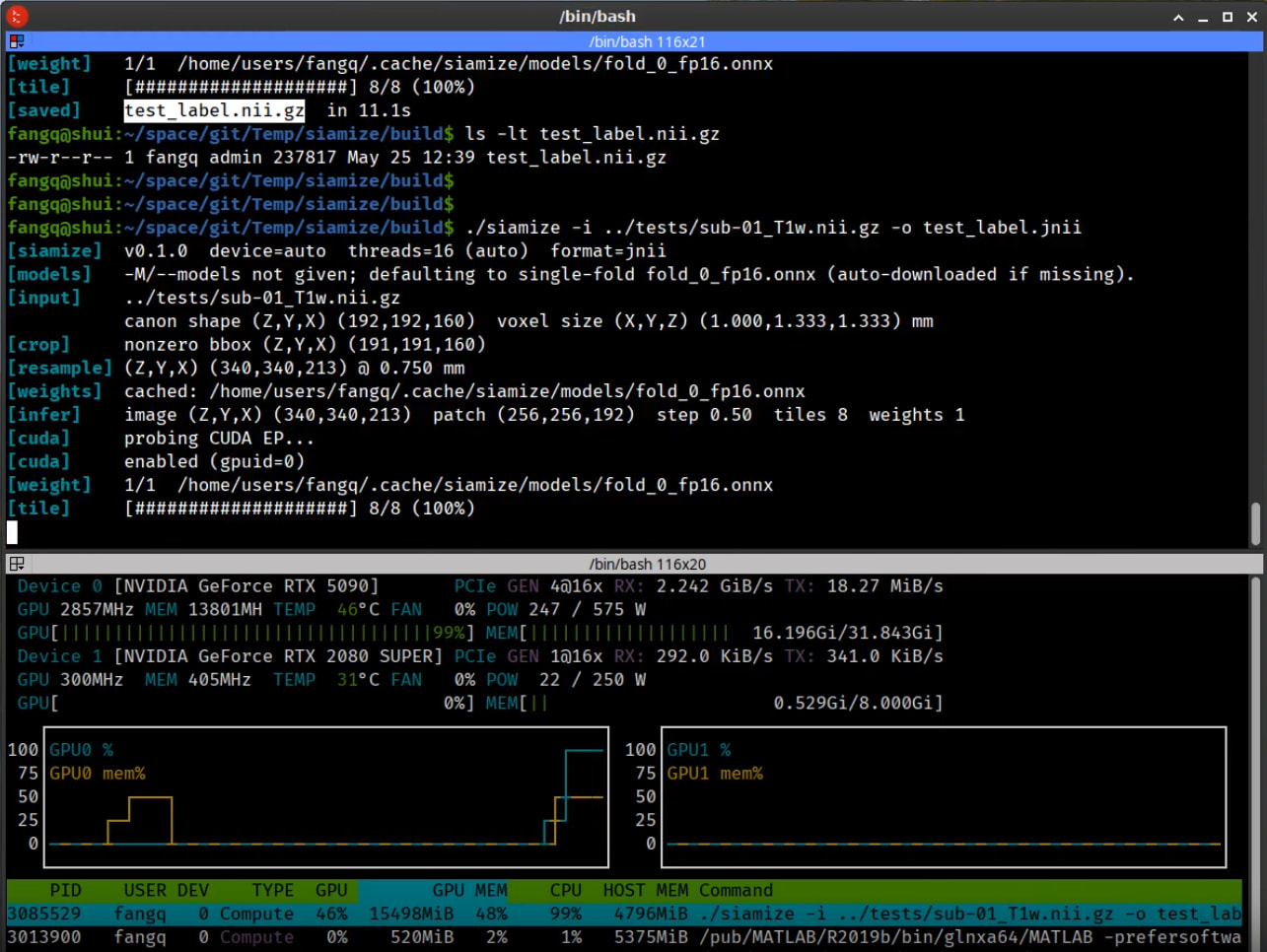
MATLAB interface
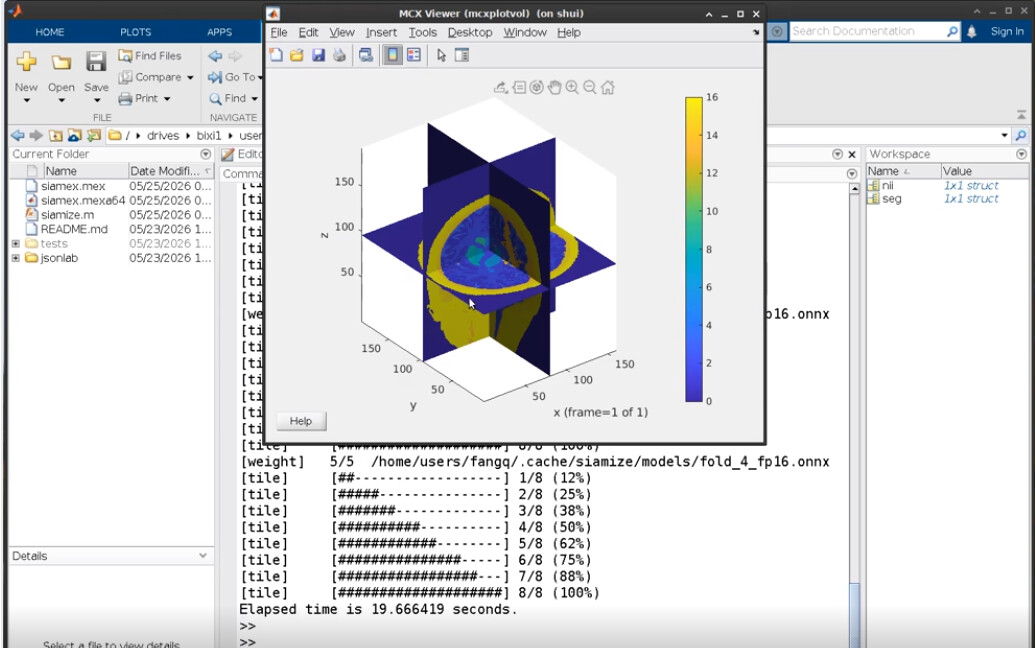
brain mesh generation from the internal high-res TPM using iso2mesh
here is a comparison of binary sizes between different backends