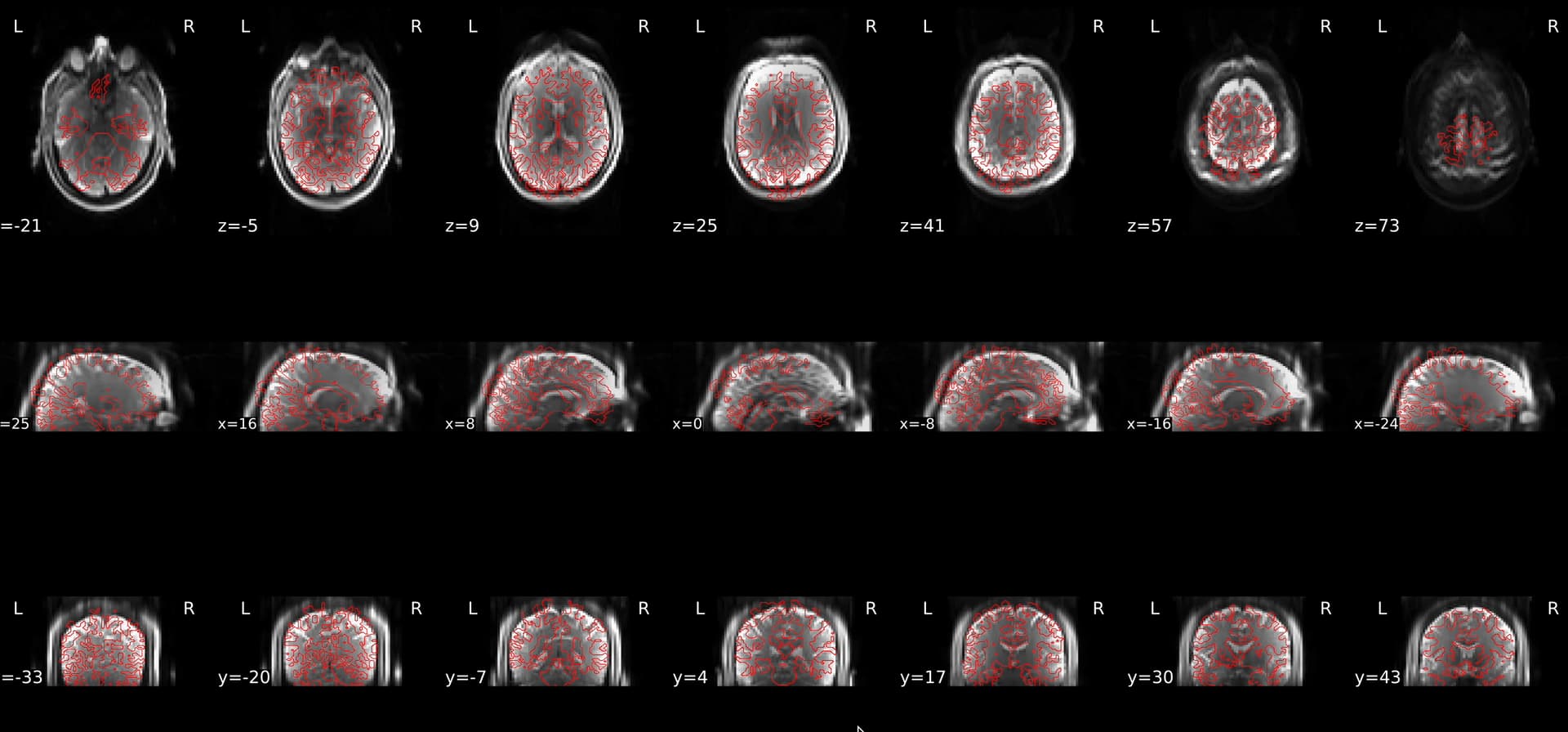
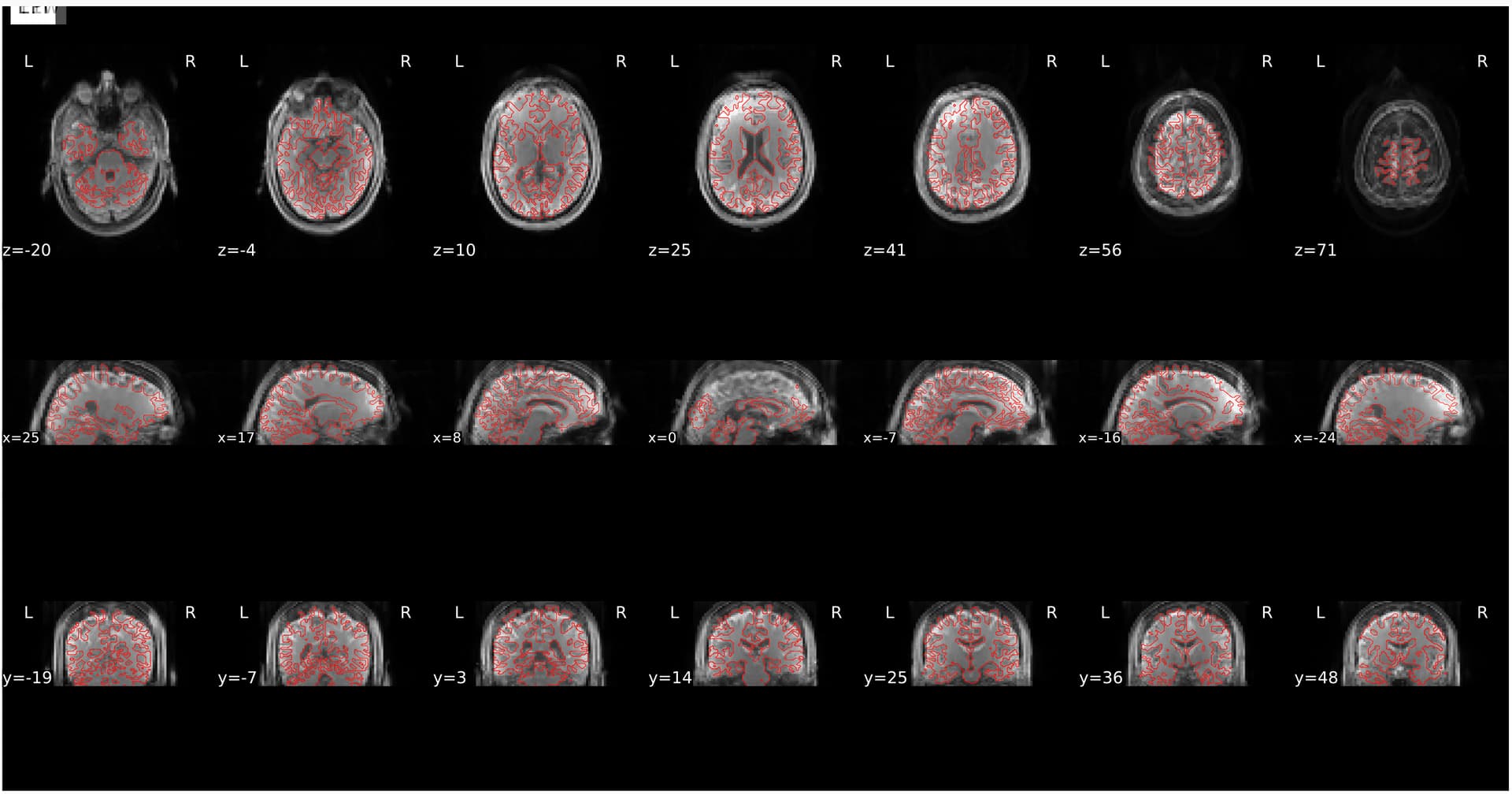
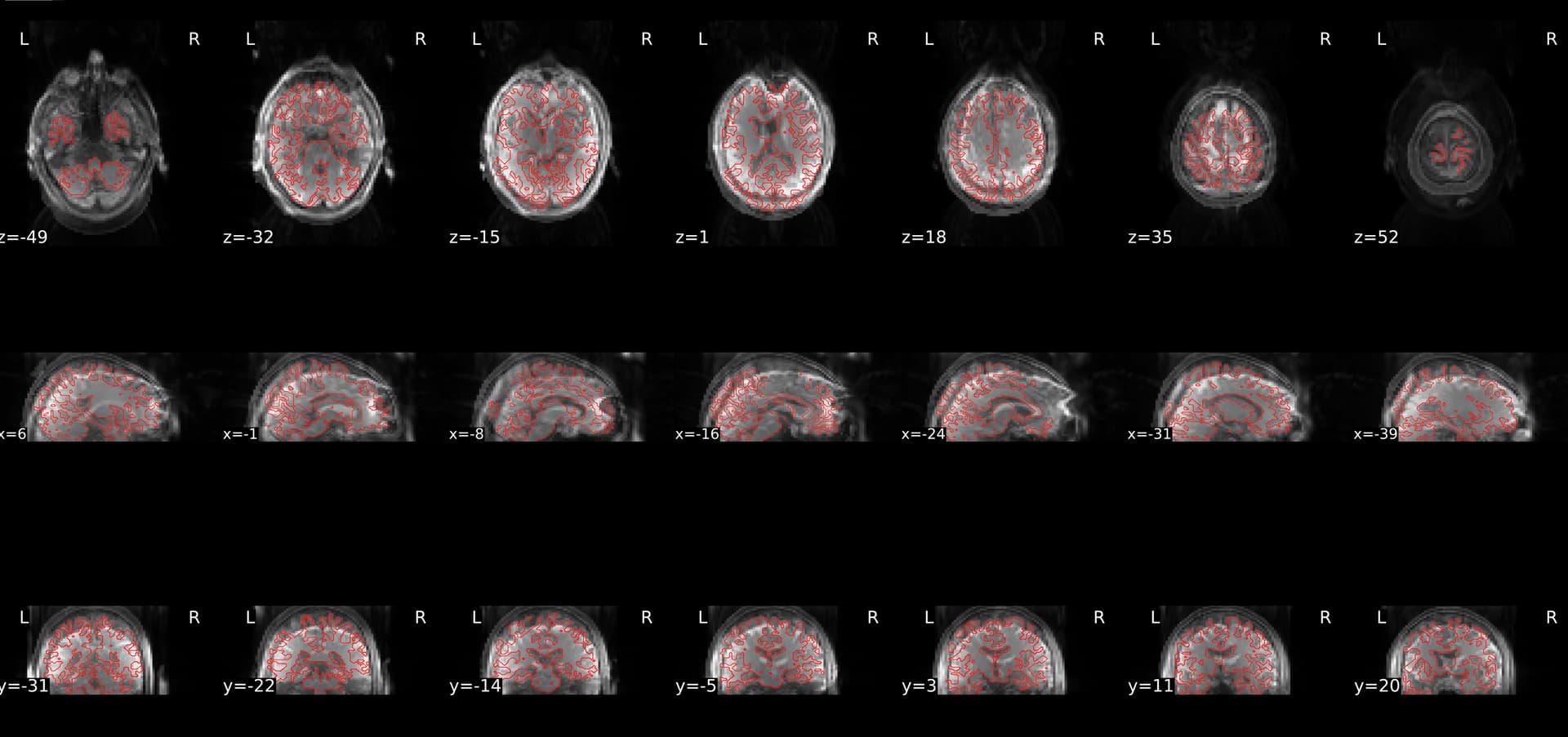
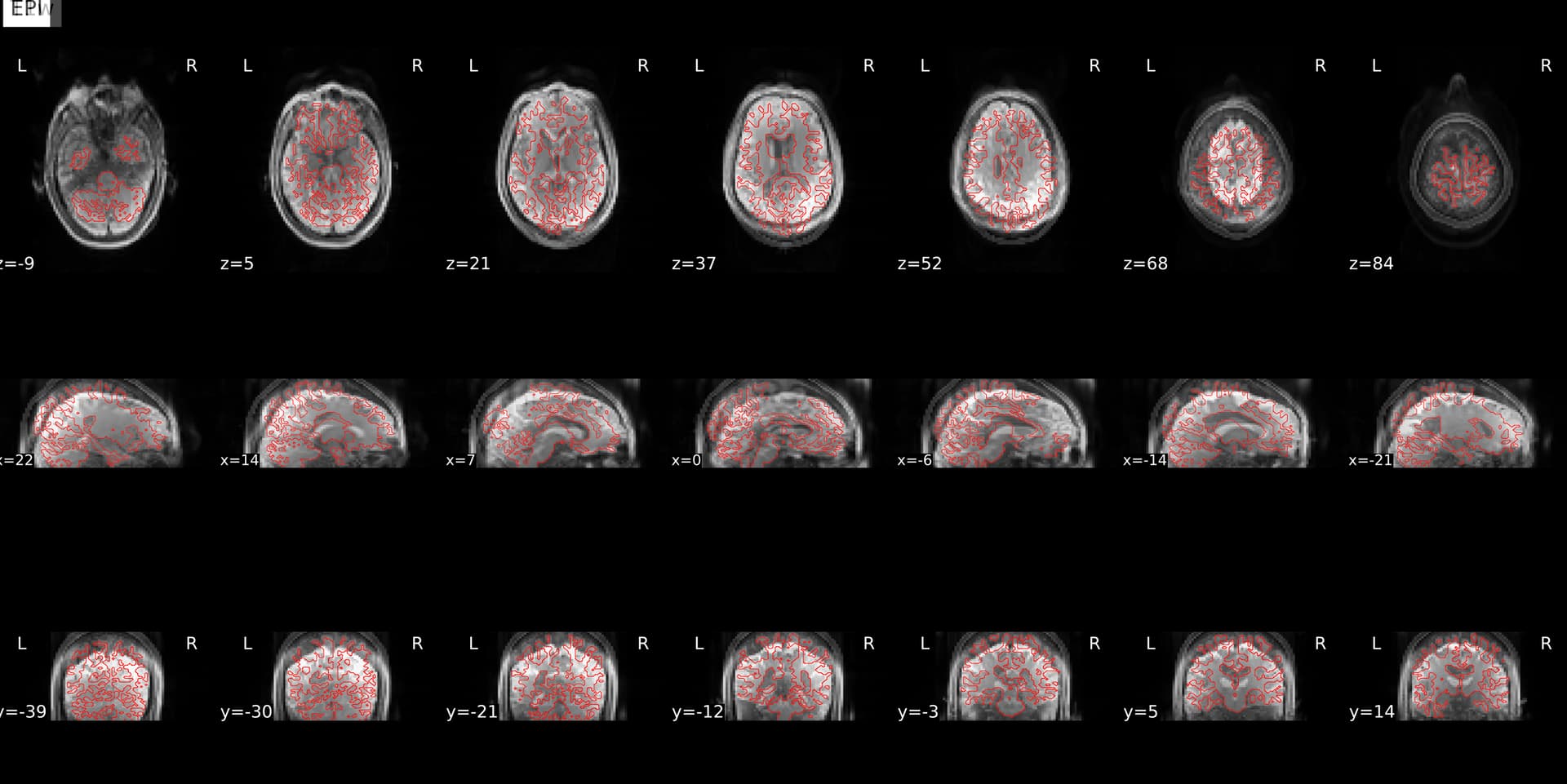
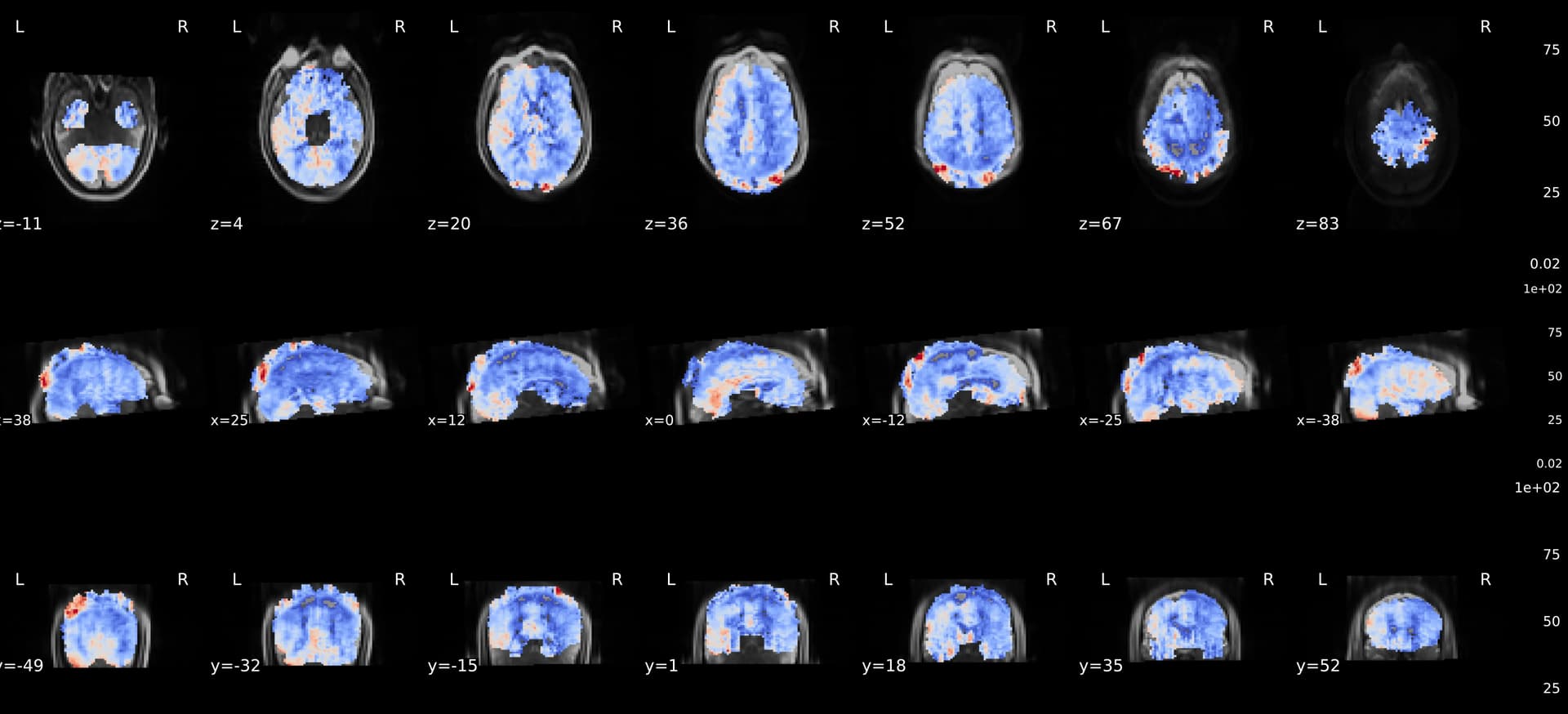
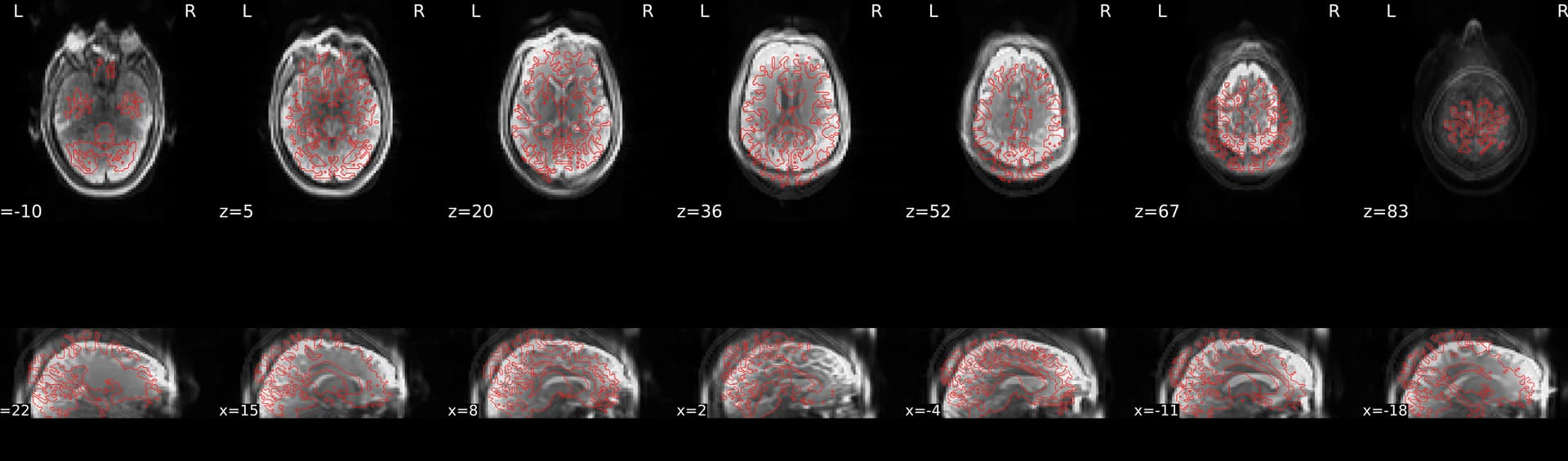
When decided then to rerun one participant to check if it was an error of preexisting freesurfer outputs, or because of using --force-bbr, however it still did not look perfect.
Command used (and if a helper script was used, a link to the helper script or the command generated):
Hi @AustinBipolar! Thanks for your comment. I will provide more info about the context.
Our t2w is specific sequence for hippocampus which we believe it won’t improve coregistration.
All t1w images have undergone quality check process, so enough quality from those is ensured
–fs-no-reconall command was applied as a second option to see whether data coming from freesurfer is the one causing the problem, but still coregistration do not match perfectly.
I released a new version of ASLPrep yesterday (0.7.5) with an updated version of sMRIPrep. Would you mind trying out the new version on your problematic subject to see if that fixes the problem?
ASLPrep relies on sMRIPrep and fMRIPrep to create these transforms, so the issue might be better addressed by someone with more experience debugging fMRIPrep’s coregistration (@smeisler?).
The first image seems to have a lot of distortion. Does the distortion correction look alright?
is differing in transform matrix between versions 0.7.3 and 0.7.5, though information from sub-897_ses-1_desc-coreg_aslref.nii.gz and brainmask.mgz is the same when using both versions. Shouldn’t it had been the same result? Anyhow, none version is solving my issue related to corregistration.
It’s from the aslref to the anatomical image, using fMRIPrep’s init_bold_reg_wf. Maybe the poor alignment is due to the 3dUnifize issue you reported elsewhere?
Hello!
I have been looking in the registration workflow and I found that in the Lanczos Interpolation, as far as I am concerned, corregistration is made from t1w to aslref. Look at the command here (which you may find in the following folder: ‘/aslprep_0_7_wf/sub_701_wf/asl_preproc_ses_1_wf/asl_fit_wf/asl_fit_reports_wf/t1w_aslref’):
What I have understood so far is that including ,1 at the end of --transform is applying the transform inversely.
Furthermore, sub-701_ses-1_from-aslref_to-T1w_mode-image_xfm.txt is coming from the concatenation of sub-701_ses-1_desc-coreg_aslref_bbreg_sub-701.lta (which transforms aslref to fsnative) and sub-701_ses-1_from-fsnative_to-T1w_mode-image_xfm.txt. So as a result sub-701_ses-1_from-aslref_to-T1w_mode-image_xfm.txt without inverting (what means without ,1) is transforming from aslref to t1w. Then, as we are using “,1” we might be corregistering from t1w to aslref.
I would truly appreciate some guidance into this, and in case I am wrong when understanding the workflow let me know
That’s happening after the transform is computed. The step that creates the transform uses the aslref image as the source and the T1w (or T2w in some cases) as the target. I believe the relevant workflows are fmriprep.workflows.bold.registration.init_bbreg_wf (if there are Freesurfer derivatives) and fmriprep.workflows.bold.registration.init_fsl_bbr_wf (if there are not).
Four settings that can impact the coregistration are asl2anat_dof (--asl2anat-dof), asl2anat_init (--asl2anat-init), use_bbr (--force-bbr/--force-no-bbr), and run_reconall (i.e., if there are Freesurfer derivatives or not; --fs-subjects-dir/--fs-no-reconall). I think the ASL reference image’s contrast should be similar enough to BOLD that the overall method is fine (and my previous experience with ASL data has reinforced that), so maybe adjusting those settings will help.
Hi @tsalo, thanks for your answer. There is still somethings I do not understand sub-701_ses-1_from-aslref_to-T1w_mode-image_xfm.txt and out_fwd.tfm coming from the concatenation contain exactly the same data and were created at the same time. Besides, when looking at how reports are generated, perfusion_calib.nii.gz is being overlayed to /data/output/sub-701/ses-1/perf/sub-701_ses-1_desc-coreg_aslref.nii.gz which is even named as “ref_vol” in this workflow. If corregistering to t1 space shouldn’t it be ref_vol a t1 and not an asl image.
sub-701_ses-1_from-aslref_to-T1w_mode-image_xfm.txt is probably the BIDS-named output created by copying and renaming out_fwd.tfm.
desc-coreg_aslref is the ASL reference image that is used for coregistration. It isn’t a coregistered ASL reference image, which would instead be named something like sub-701_ses-1_space-T1w_aslref.nii.gz (i.e., using the space entity). When the space entity isn’t present, the file is in the “native” space for whatever modality the suffix indicates. So for aslref, it’s in ASL space. For files with the T1w suffix and no space entity, the image is in native T1w space.
Hello again @tsalo, thanks for the clarification.
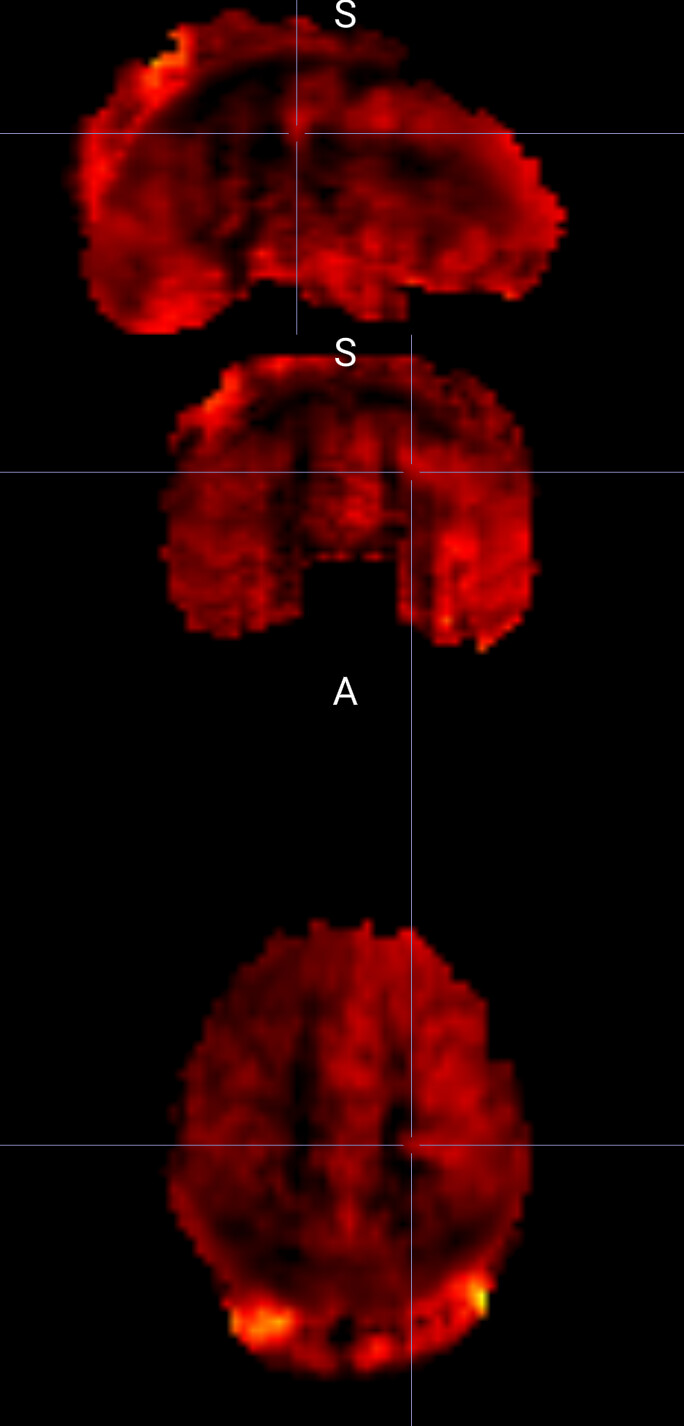
I understand that in native space outputs, the output spaces is the asl one. Then, one of our participants cbf maps is looking like this in native space:
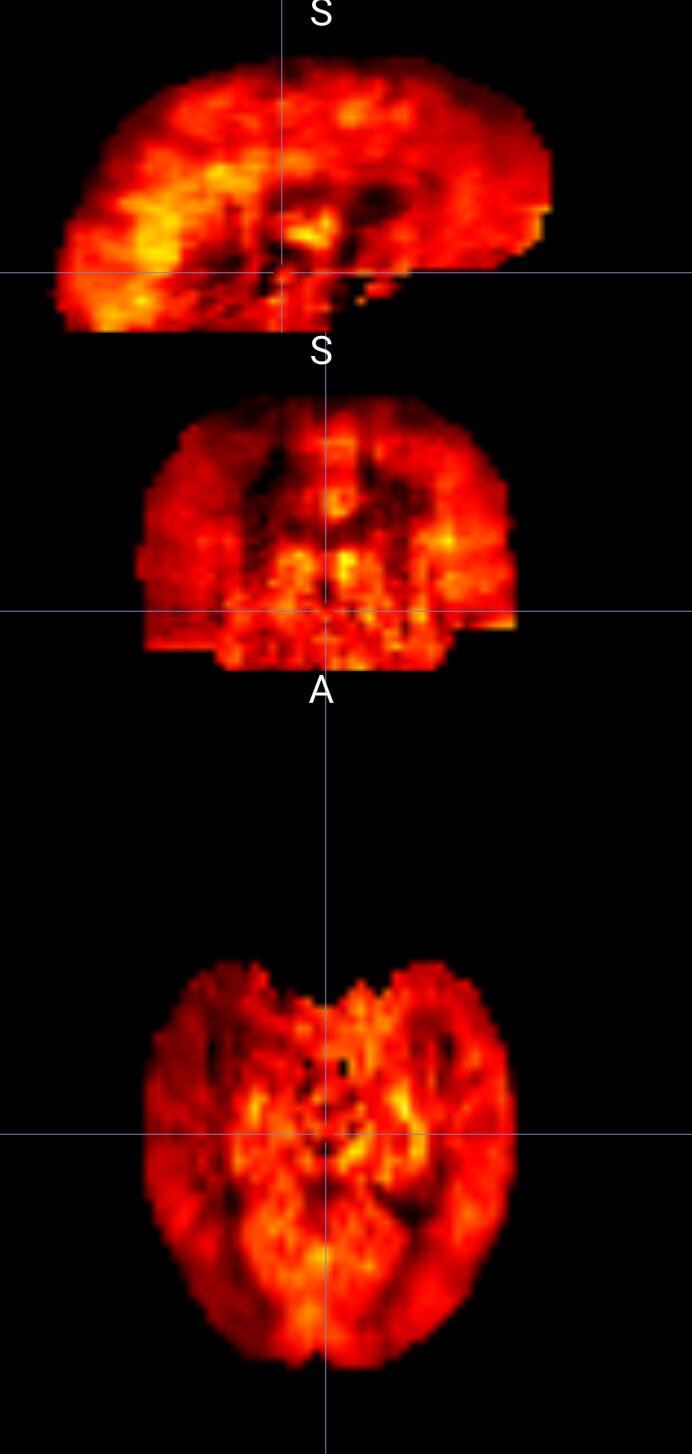
We decided to try performing basil with fsl anat (so not running aslprep), to see whether the error was coming from our data. We found out that outputs looked okay, here I am showing you the perfusion_calib output from the same participant: