Hi all,
I have encountered some issues with bold brain masks in some of our subjects multiband, multiecho data. I processed the data using fMRIPrep version 20.1.0rc2. In total, 4 out of 41 subjects seem to have problems with the bold brain mask and one subject has problems with the EPI bold signal itself. I have gone through a lot of other similar problems on neurostars, but unfortunately I couldn’t find the solution. Also, I am new to fmriprep, so I guess that also doesn’t help. Below I described three subjects to show you the errors I ran into:
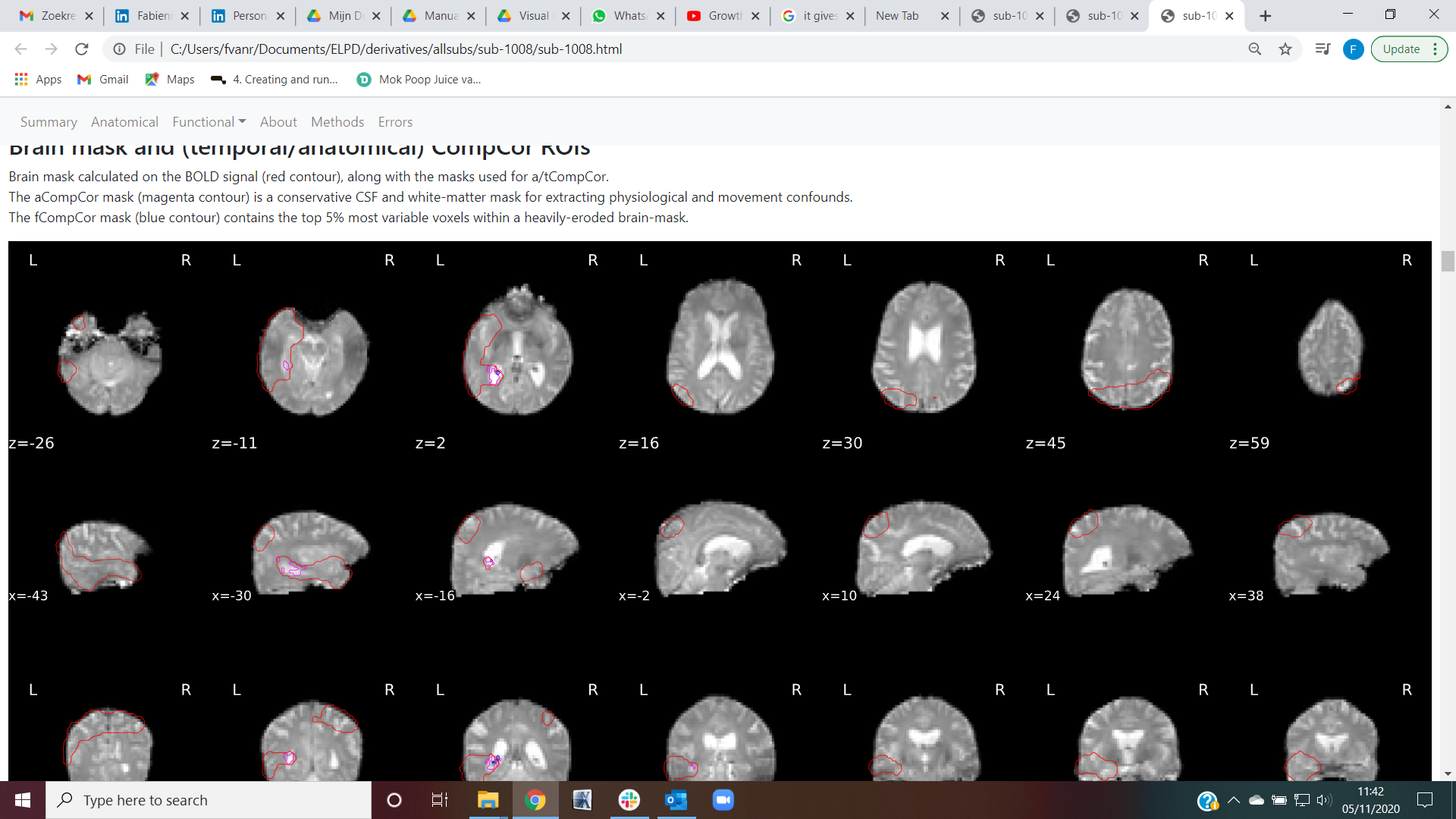
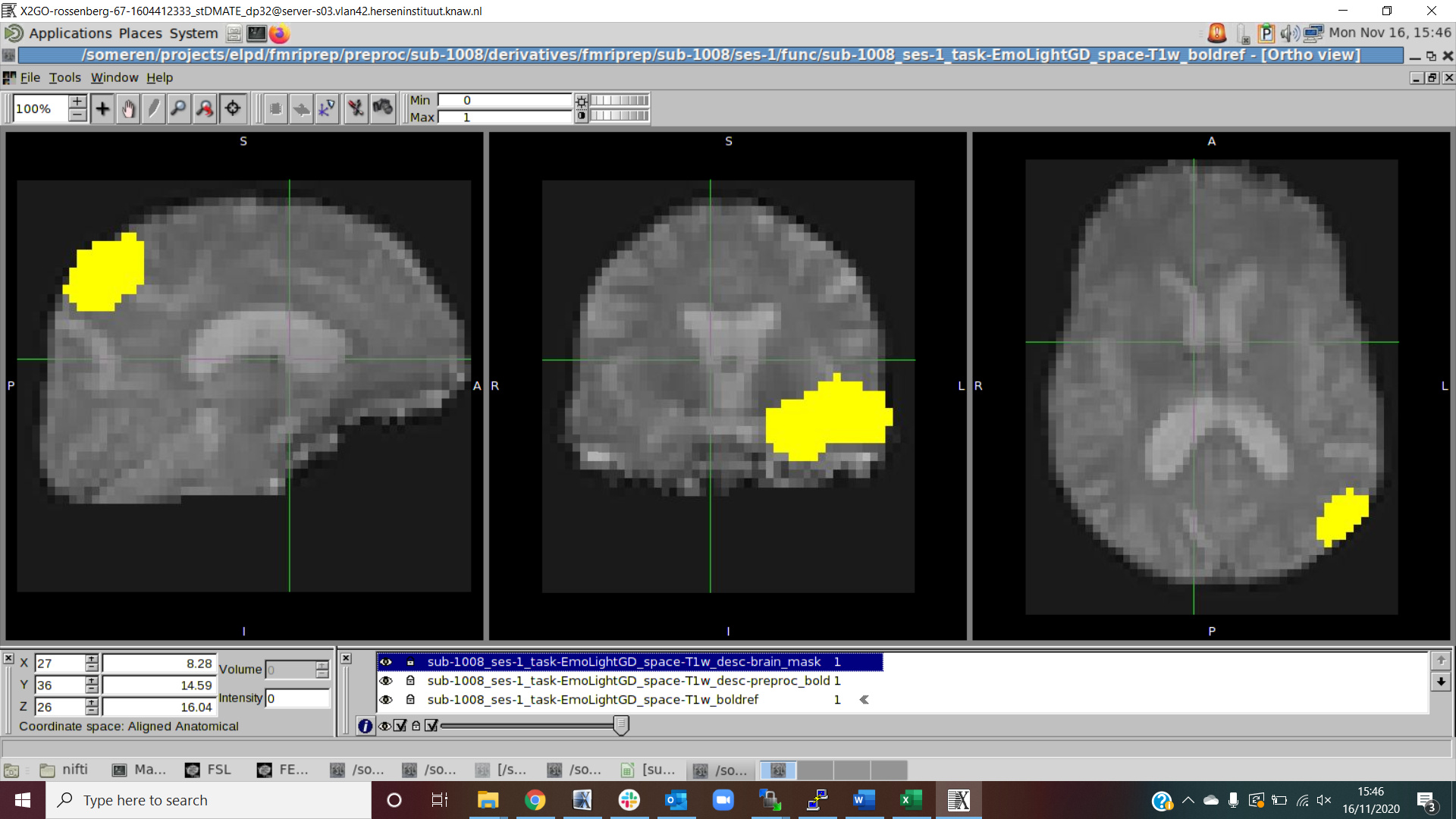
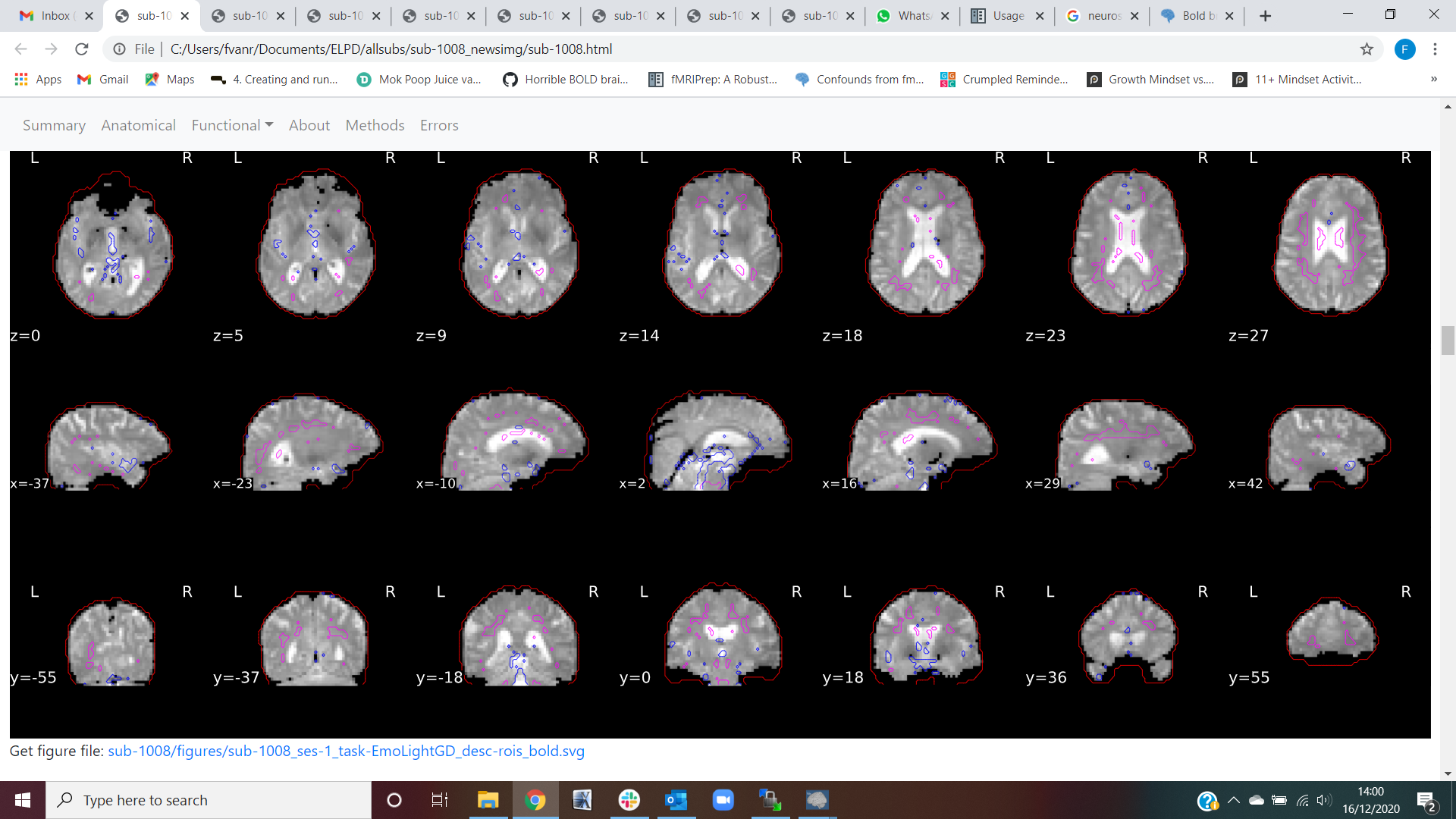
sub-1008; the brain mask calculated on the bold signal seems to go wrong, even though the bold signal itself looks fine (see screenshots on sub-1008). The output file doesn’t give any errors, but as you can see in the report the incorrect bold brain mask impacts the ICA procedure. In addition, a confounds file is made but it seems incomplete.
sub-1025: I think the problem is similar to sub-1008, though this time there is no brain mask on the bold signal at all (or so tiny that a confounds file was not be made, this is also reflected by the lack of summary in the report). Though this time an error was given (can be seen in report)
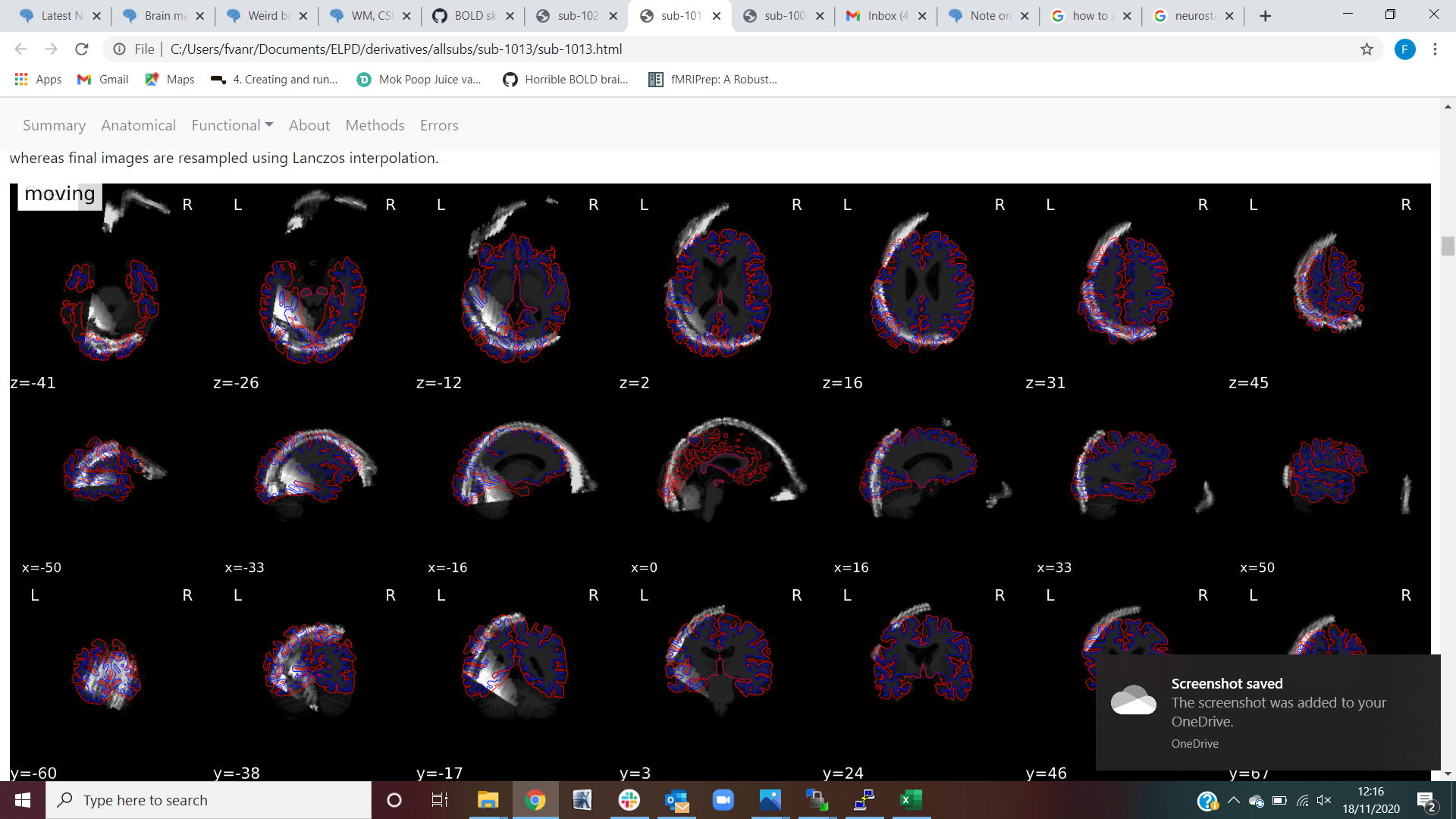
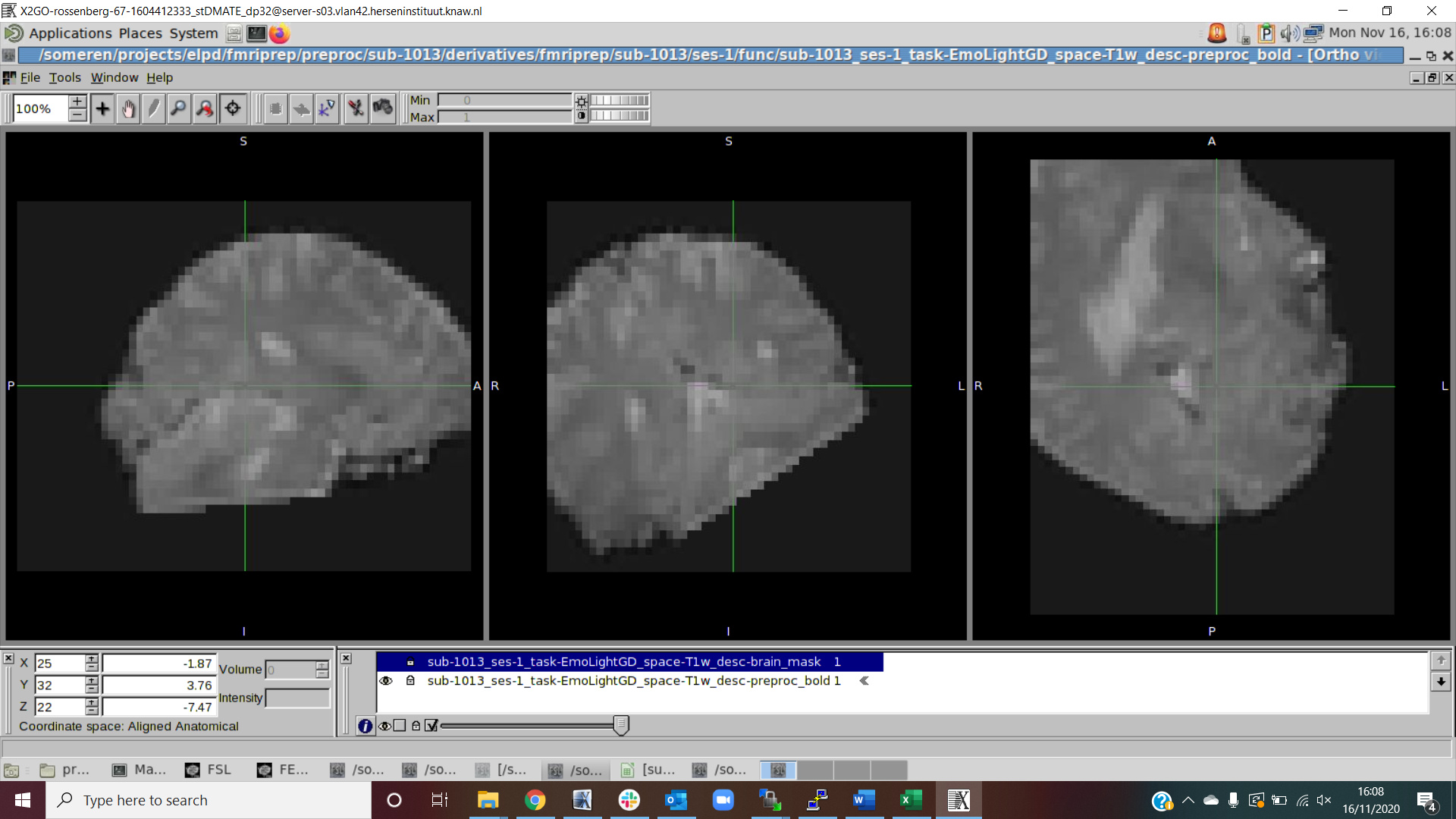
sub-1013: this problem is different. It looks like there is something wrong with the axes. The bold brain mask looks correct, however this time the bold signal itself looks weird. (See both screenshots on sub-1013). Again, no errors were given in the output files. This error was only found in the session 1, session 2 looks good.
In the reports you will probably see the following: * Phase-encoding (PE) direction: MISSING - Assuming Anterior-Posterior. I guess I didn’t include this in the json files, but our data is indeed A-P, so I think this shouldn’t be the problem.
The problems you show seem pretty clear, and I can’t think of anything you can do to immediately alleviate those.
I think we will need to get some example data from you to be able to replicate this. If you could share some of these data directly, that’d be the best option. If not, we could try to think some intermediate results that we could leverage on our end while being shareable on your side.
In the meantime, could you please check the latest LTS release (20.2.1) on your sub-1013. We included some improvements that might have fixed the issue.
Thanks so much for your reply. I included the input data from the three subjects I described above in the following wetransfer link: https://we.tl/t-dLWSFiSQ1V
Let me know if this works or if you need any other info. In the meantime I will do what you said and try to run fmriprep with the latest release.
Hi @oesteban, were you able to discover what went wrong?
I ran the error subjects with the latest version of fmriprep and the results look much much better than before. However, I’m still not sure about the brainmask and the acompcor/tcompcor masks: the brain masks seem much larger than necessary and the acompcor and tcompcor don’t look very accurate either. In addition, it looks to me like the bold signal is more eroded compared to the bold signal from the previous fmriprep version. Here’s an example:
I won’t use the acompcor and tcompcor measures for further analyses, but I will use FD (which is dependent on the bold brain mask if I’m correct?) Can I safely use the FD confounds and the bold brain mask for further analyses? I uploaded the output reports of the subjects in the google drive folder in case you want to take a look: https://drive.google.com/drive/folders/1IzJRw9TiORyAOz6TzbXhC1wP6nhsT7eF?usp=sharing.
Hi @fabienne, I downloaded your data and it’s sitting in the Downloads folder of my laptop. Unfortunately, I haven’t had a chance to run them. I will try to prioritize for early January.
That said, your screen capture looks much better. Those a/tCompCor masks look sensible. The pink contour (aCompCor) does not include GM regions and covers CSF and WM with high-certainty segments. The blue contour (tCompCor) also makes sense, concentrating around the brain stem and 3rd ventricle.
The mask looks good, and although the lower threshold for the visualization could be better, I think this is just a confusing effect of the color scale settings of this particular plot. Just to be safe, please open the corresponding sub-1008_ses-1_task-EmoLight_desc-preproc_bold.nii.gz file and check whether the data is so tightly cropped with a mask.
Thanks for your reply, no worries!
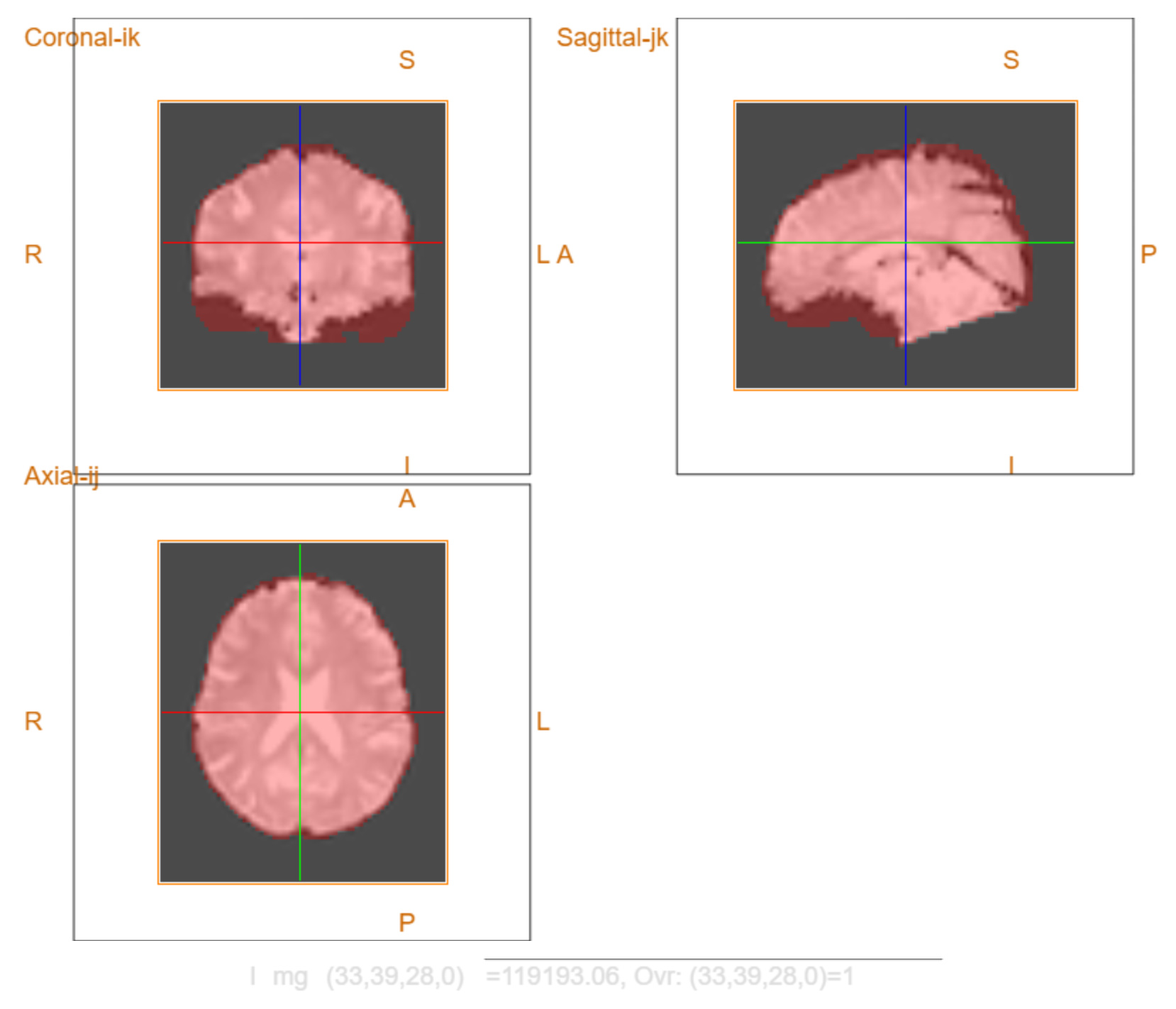
I’m glad the a/tCompCor masks look sensible. I opened the corresponding desc-preproc_bold.nii.gz file and used the desc-brain_mask.nii.gz to overlay it. I overlayed the desc-brain_mask.nii.gz on top of the bold signal from the latest fmriprep version, but also on top of the bold signal from the older fmriprep version that I used. This looks as follows:
Brain mask latest version (red) on top of bold signal latest version (pink):
What do you think? The desc-preproc_bold.nii.gz output from the older version looks better than the desc-preproc_bold.nii.gz from the latest version right? The new brain mask actually fits the old bold output perfectly, but why does the new bold output look different?
I think I might know the answer, but I’m not entirely sure. What I suspect is that the red brain mask calculated on the bold signal in the ‘brain mask and compcor rois’ is based on the bold signal from the first echo time, whereas the bold signal itself is the result of the optimally combined time series. If I look at the output from the new fmriprep version the reports section specifically lists ‘Multiecho EPI sequence: 3 echoes’, whereas this was not the case for the output from the older version. In addition, the output from the older version specifically mentions: 'reports for session …, task …, echo 1. I suspect that no optimal combination of the three echoes was performed when I used the older version (even though the method section did mention the optimally combined timeseries). This might also explain why the brain mask from the new version matches the bold signal from the old version so well, because they both resemble echo 1.
Could this be true?
Per nipreps/fmriprep#2348, there is a minor masking-related bug in fMRIPrep where a mask is created for each echo and applied before optimal combination. Then, the optimal combination step creates its own mask based on which echoes have good signal. I have a pull request open that should use only the first echo’s mask, so if that gets merged then your description will be accurate.
Per ME-ICA/tedana#617, a few multi-echo users have noted that tedana's optimal combination procedure may be masking the data overly aggressively. This is mostly because there are two common goals for multi-echo acquisitions: (1) improving coverage in areas affected by signal dropout and (2) identifying and removing non-BOLD signals from the data. Most of the work in tedana has focused on the second goal, which requires at least three “good” echoes at each voxel being denoised, while the first goal is really focused around getting every last bit of reasonable signal from earlier echoes.
We (the tedana devs) are working on a solution that will hopefully increase brain coverage in the optimally combined data in order to better support that first goal. Once that’s implemented, I can increase the minimum tedana version in fMRIPrep's requirements.
From what I understand, this was just a documentation issue (see nipreps/fmriprep#2174). The old method did optimally combine the data, but the reports were inaccurate.
Thanks a lot for your reply. This clarifies much, though I still have a few questions.
Are these issues only present for the latest fmriprep version or also for the older version I used (20.1.0rc2)? Because the tedana workflow wasn’t masking the data overly aggressive for the older version I used, or so it seemed. Though the latest fmriprep version solved my initial issues with a few subjects it gave new problems with the bold signal. Does it make sense to run an fmriprep version later than 20.1.0rc2 but prior to 20.2.1?
How much time do you think it will cost before the issues are fixed?
There were bugs in fMRIPrep’s processing of multi-echo data that were fixed in 20.2.0rc0 so I wouldn’t recommend using 20.1.0rc2.
That makes sense. It’s a product of our (the tedana devs) focus on denoising over optimal combination in the most recent release. The next release should resolve that.
Unfortunately, AFAIK there’s no fMRIPrep release that pairs the older version of tedana with the corrected version of the fMRIPrep workflow, so even if you use 20.2.0rc0 you’ll still have tedana's aggressive masking issue to deal with.
I have pull requests open that should resolve both issues, but I don’t know how those will translate to fMRIPrep versions. The change to tedana will require a new release before we can get it supported in fMRIPrep, although we’re due for one anyway so that will hopefully happen fairly soon. I cannot speak to fMRIPrep's release schedule, though. @oesteban will probably be able to answer that though.
@oesteban, considering everything that’s been said in this thread so far, what do you think are my options for using fmriprep? I have few time left to finish my data analysis and I’m hesitant whether I will be able to use fmriprep or whether I should go back to manual preprocessing, though I obviously much prefer fmriprep. I’m looking forward to your response, but if it’s perhaps easier to discuss this via a call let me know!