Hi experts 
I’m fairly new to the field and currently try to make my first steps with the preprocessing and analysis of resting state fMRI data.
For the preprocessing I used fmriprep 20.0.2 (Windows, Docker environment) with the basic command:
fmriprep-docker participant --participant-label sub-01 --fs-license-file
I now end up with BOLD data, which has been upsampled to the MNI152NLin2009cAsym space. This increases the size of my data massively, which makes further analysis quite a lenghty process. Apart from that, I’m not even sure if its a good idea to to upsample functional data at all. Is this the normal behaviour?
The documentation tells me
By default, fMRIPrep will resample the preprocessed data on those spaces (labeling the corresponding outputs with the space- BIDS entity) but keeping the original resolution of the BOLD data to produce smaller files, more consistent with the original data gridding.
Am I missing something here?
Because I didn’t want to rerun the whole preprocessing before getting some external advice,
I tried downsampling my data with nilearn’s img.resample_to_img() function. This wasn’t too succesful tough, resulting in data which seems to be cut off in a weird way:
fmriprep data:
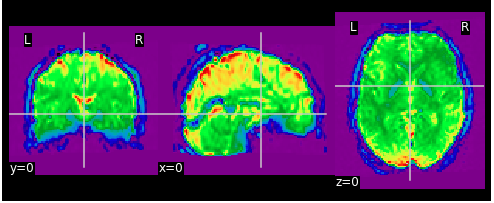
downsampled data:
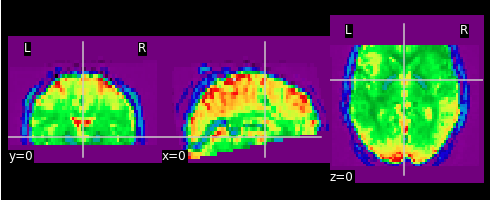
I feel like these are some pretty basic questions but I’m out of ideas…
Thanks in advance for your help!
Oh, and another (unrelated) question of me trying to work through the documentation:
If I want ICA-AROMA to be performed, do I need to add the --use-aroma parameter, or is the non-aggressive denoising done by default?
Best,
Micha