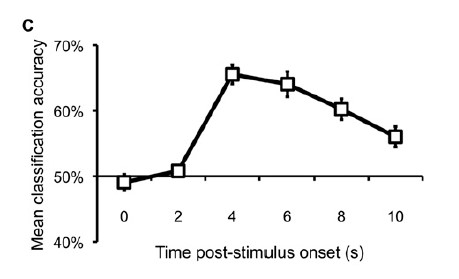
In the following paper, by computing classifier performance at each volume, the authors confirmed that classification accuracy generally conformed to the pattern of a hemodynamic response function, with peak accuracy achieved 4–8 s poststimulus onset (Fig. S2C).
How could I do this type of analysis? Are there some specific way to do this in TDT? They used SPM. So, I have the following idea to achieve that: In a single participant, I could make various first level analyses. Each one (first level) will have the same data regarding the task (files, regressors, duration, etc), but different time onsets. For example, in the first one a trial with a duration of 4s was suppossed to start at 0, so the onset will be at 0s. In the second (first level) the onset for that same trial will be at 2s. Then in the third (first level) the onset have to be at 4s.
After that, the next step should be doing the estimates for each first level and then get the mean accuracies for each one. Is this idea make sense? I attach the figure from the paper’s supporting information.
I would read up on FIR models in SPM (or TENT models in AFNI), which requires only one first-level model. Then you can get one regressor per time bin and do time-resolved decoding. TDT can nicely deal with FIR models (see decoding_tutorial). The relevant section is this:
The function [design_from_spm] appends ' bin 1' to ' bin m' to the beta names if multiple regressors have been used for each condition within a run, e.g. when using time derivatives or an FIR design.
You can either run one separate GLM per bin, or you can use cfg.set and make each bin a different set. Then you only need to run one analysis and load in data only once and can easily have all results in one folder. I do not recommend doing this at a single-trial level, unless you want to classify based on individual volumes.
Hi Martin,
Thank you so much for the solution. I have tried some of those ways and I achieved the objective. However, I realized that there is something unusual in my data. Normally in fMRI is common to expect a delay in hemodynamic response (as shown in the figure). In the case of the paper I attached, their post-stumulus onset occurs 4s (two volumes) after trial presentation. But, in my data the higher peak (hrf) is at the two first volumes (within trial presentation). Thus, when I execute the decoding analysis per volumen, accuracies are greater in the first two volumes, corroborating the idea that the hemodynamic response peak is in those first two volumes.
Is this hemodynamic response normal? About the image acquisition is important the to mention that the beginning of the TRs are sinchronyzed with the beginning of the trials, and I made sure to establish 5 dummy scans before each run to stabiliza the signal.
If you could help my with any of these queries, I would greatly appreciate it.
It’s quite unusual to see it peak that early, and even above-chance decoding in the first two volumes is unusual. To me it sounds like a mistake in the timing (e.g. perhaps everything was shifted by two to four volumes). Check the shape of the HRF in the BOLD response itself. If you find early increases, something might be wrong. If the HRF looks normal, then it could be related to filtering (quite unlikely given that the peak is shifted, not broader), you may have a confound that is left uncontrolled (seems unlikely, as well) or too few data points to get an accurate estimate of the HRF (e.g. due to your design or due to the decoding scheme).
To me, this seems like less of a decoding issue though.