I’m trying to use cluster-extent based thresholding to identify neural correlates for my exploratory analysis. However, I found it really hard to set the arbitrary voxel-level primary threshold:
When I used a relatively lenient threshold (e.g., p < 0.01), I would get one huge cluster of ~20k voxels spanning across the whole brain (cluster identified using FSL cluster).
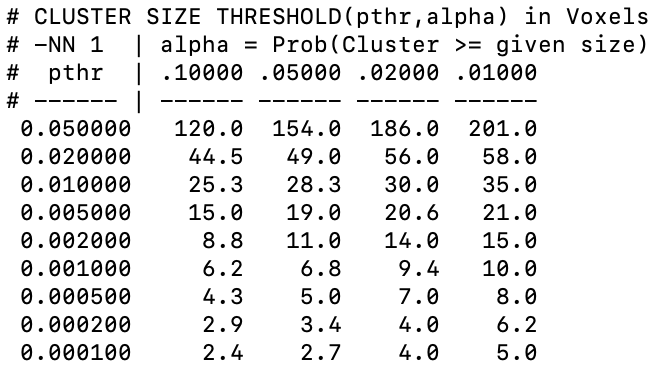
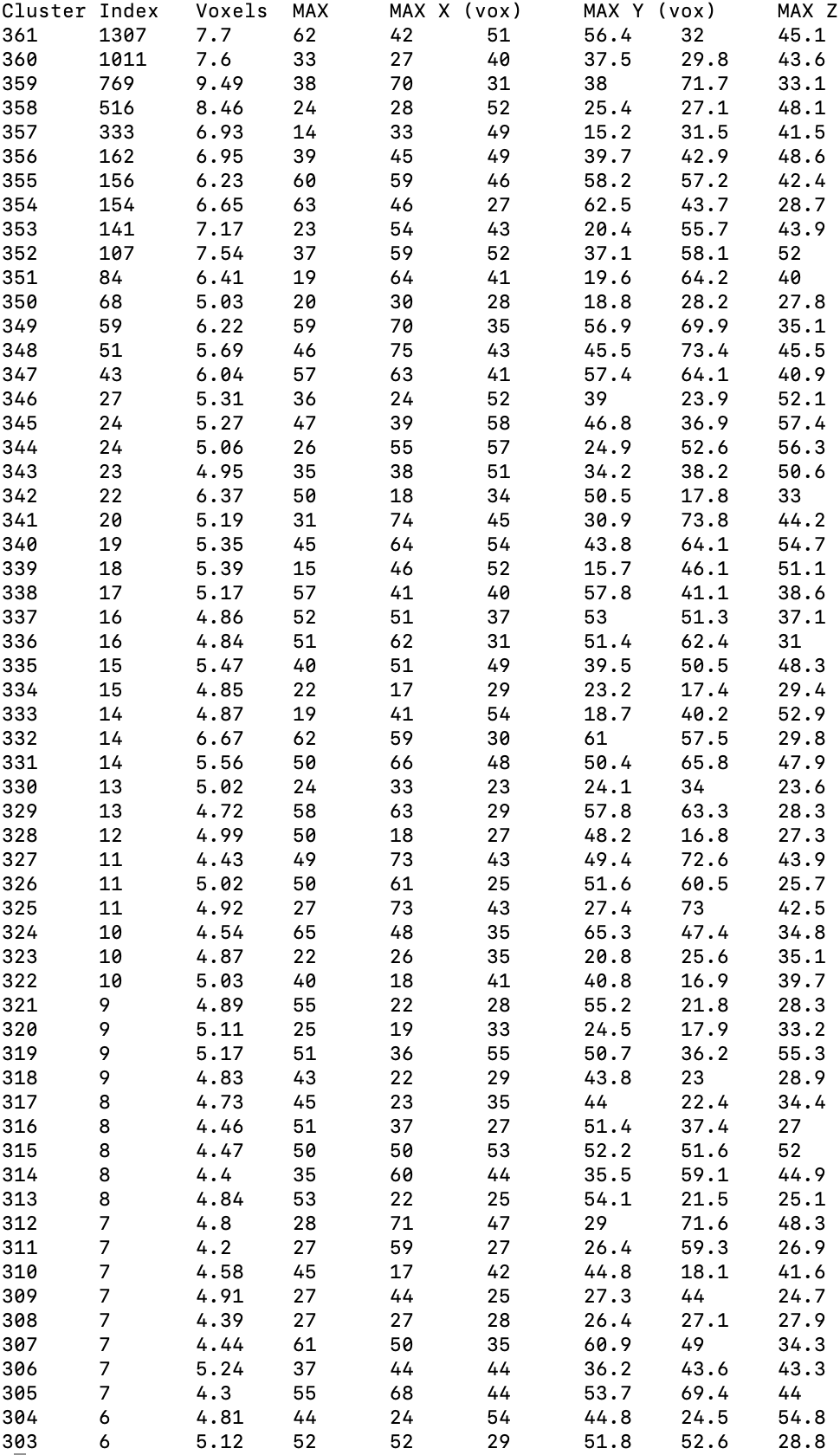
When i used a relatively strict threshold (e.g., p < 0.0001), I do get clusters of reasonable size. However, when computing the cluster-level extent threshold (using AFNI 3dClustSim), the cut-off cluster size to make a cluster significant becomes really small (cut-off size = 5). Thus, I would end up getting a lot of clusters which contain less than 10 voxels, as shown in the two figures here:
(The column labels are off, the first column name is “Cluster Index”, second one is “Voxels” and so forth)
I wonder what would be the right thing for me to do here if I want to identify voxel-clusters of reasonable size? For the worst case, if I have to arbitrarily select a cut off for the cluster size, is there any rule of thumb to go for?
That kind of trade-off is to be expected: high thresholds bias towards the super significant (and potentially smaller) and low thresholds bias towards very large (and potentially much less significant). That is one of the reasons that Bob developed the ETAC strategy, to incorporate cluster results from a range of significance cut-offs, while still controlling overall false positive rates. Please see this article for more details:
It is an unfortunate (but inherent) side effect of standard clustering strategies that the mostly arbitrary p-value threshold affects results so strongly. The ETAC strategy tries to reduce the influence of the arbitrariness: you can use a range of blur values (say, 4, 6, 8 and 10 mm) and p-values (say, 0.01, 0.005, 0.001, 0.0001) and combine the results.
Note that moving in a very different direction, if you were willing to use ROI-based analysis, you could use something Gang has worked on recently, that reallly removes the need for arbitrary thresholding:
Chen G, Xiao Y, Taylor PA, Rajendra JK, Riggins T, Geng F, Redcay E, Cox RW (2019). Handling Multiplicity in Neuroimaging Through Bayesian Lenses with Multilevel Modeling. Neuroinformatics. 17(4):515-545. doi:10.1007/s12021-018-9409-6 https://pubmed.ncbi.nlm.nih.gov/30649677/
Chen G, Padmala S, Chen Y, Taylor PA, Cox RW, Pessoa L (2020). To pool or not to pool: Can we ignore cross-trial variability in FMRI? NeuroImage: https://www.sciencedirect.com/science/article/pii/S1053811920309812?via%3Dihub
This style of analysis is very appealing for modeling at the group level more consistently, without the need for clusterwise correction.