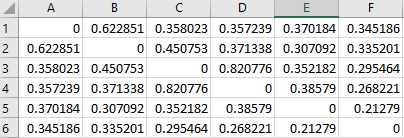
I’m computing correlation matrices for my participants, and I’ve used following code from Nilearn:
from nilearn.connectome import ConnectivityMeasure
correlation_measure = ConnectivityMeasure(kind=‘correlation’)
correlation_matrix= correlation_measure.fit_transform([time_series_participant])[0]
Example output below:
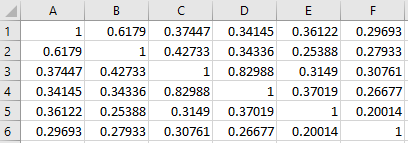
The correlation matrices I got were different from the ones I get from Matlab using:
corrcoef(time_series_participant)
Example of the same participant below
I had a search around on the Nilearn website and found that Nilearn uses the LedoitWolf Estimator in the ConnectivityMeasure function by default; which implies that correlations are slightly shrunk towards zero compared to a maximum-likelihood estimate…I’m not very familiar with this method and found the LedoitWolf Estimator is not commonly used in fMRI. And clearly it does more than just correlation…It would be useful if I could have some information regarding the steps involved in the ConnectivityMeasure function, or any information about this method. I’m trying to weigh between the two methods and choose which one to use for my research.
Thank you for your time and any help is greatly appreciated!
In fMRI, correlation matrices are estimated with very little data. Usually the number of volumes is on the order of the number of ROIs. In such situations, the sample correlation matrix is “degenerate”. Roughly speaking it means that you don’t have enough data to fill ROI x (ROI-1)/2 unique entries of the correlation matrix accurately.
The Ledoit-Wolf estimator is probably one of the least disruptive estimators of making sure other downstream operations on such a correlation matrix don’t break. Small samples sizes inflate the strength of the correlations upward. The Ledoit-Wolf shrinks the entries back down a little. The larger the length of the time-series/sample size, the less the shrinkage.
The Ledoit-Wolf estimate takes the form
alpha x [Sample Correlation] + (1-alpha) x [Identity]
where
sample correlation is the naive sample correlation matrix
Identity is a diagonal matrix with 1s on the diagonal and 0s on the off-diagonals.
alpha can be fixed but usually solved for analytically to be the best mean square error fit to the data.
It is really widely used in nearly every field of biology/finance that infers correlation matrices from either time-series or other observations. If you need to perform PCA, spectral clustering, or any other type of eigenvector decomposition on the correlation matrix, this kind of shrinkage ensures that you don’t have near-0 eigenvalues.
It is also widely used within fMRI circles to get the partial correlation matrix. You cannot take the inverse of the sample correlation matrix at small sample sizes without some kind of adjustment. The Ledoit-Wolf is the simplest way to go about this.
Due to the number and versatility of downstream analysis conducted on functional connectivity, statistically speaking it is a far better default for a correlation matrix estimate than just using corrcoef in either MATLAB or python.
I agree that it is not the most popular estimate used in fMRI analysis, but it is widely used. The scikit-learn developers and collaborators have used it widely in their papers. It is also widely used in the EEG literature by folks like Klaus-Robert Müller and colleagues. Anyone who tries to estimate partial correlation functional connectivity likely uses it or something similar to it during intermediate steps though it might not be widely reported.
My own experience is that the worst outcome from using it is that nothing improves i.e. at best it helps and at worst it does nothing because there are bigger issues that need solving.
This paper (though from genomics) gives you a really nice defense of employing shrinkage for covariance estimation.
Schäfer, Juliane, and Korbinian Strimmer. “A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics.” Statistical applications in genetics and molecular biology 4.1 (2005).