We are storing large datasets (up to ~ 1 TB) that are subject to frequent enrichments from various contributors, and we need to make and publish reproducible analyses based on these data. It seemed to me that Datalad might help
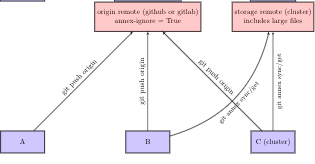
The idea is to store the data on a storage server part of our lab cluster, but we also want to have a github repository for each dataset, in order to benefit from all the nice features of github including issues, CI, PRs, etc. So this would look like this :
Before anything, since it does not seem people at the lab have an experience with datalad, I’d like some insight in order to setup the system “the correct way”.
First, how to allow users to clone/install the github directory and then do datalast get bigfiles/ without having to configure the cluster sibling by hand ? Is there a way to do that besides a setup.sh script or something like that ? (In other words, how to provide all siblings configuration along with the github dataset itself) ?
How to make sure that the github and the storage siblings won’t diverge, at least the master branch ? Should we do this with the --publish-depends option of datalad create-sibling-github ?
Can datalad handle branches properly ? What about PRs ?
We would to provide all data in the dataset, including intermediate results that take very long to compute and that other researches will need to reproduce the part of the analysis they’re interested in. Should we provide the code to reproduce these intermediate data along with the dataset ?
Should we add the code/.py and ci/.py scripts (to reproduce intermediate and final results and for continuous integration) with datalad add or git add ?
Here are a few quick answers, I hope they can help.
It sounds like you are looking for a RIA store setup. We have some documentation on this here. If you have a DataLad dataset on C and push it in a RIA store on your storage server part, and then create a Github sibling from C, anyone who clones the resulting repo from GitHub will have an automatically configured link to your RIA store to get the data (that is assuming that they have permissions to access data on your cluster part).
The one thing that is not configured automatically in this setup is the link to push data back into the RIA store (they could only push and PR Git history changes), but you could create a custom procedure that can be run automatically when users clone your GitHub repository. We can help/provide examples, so maybe check the linked chapter on whether this suits your usecase and let us know
If you go for the RIA store set up, then this isn’t necessary, but please follow up if that isn’t what you’re looking for.
DataLad datasets are joint Git/git-annex repositories, and - with rare exceptions - provide all features that both those tools provide. So, yes, branching is perfectly possible, as are PRs.
That’s my personal opinion, but I would advocate for sharing code alongside to data and results, ideally with documentation on how it should be executed. To be even more transparent, you could use datalad run or datalad containers-run commands to link data, code (+ software), and execution, as those commands produce re-executable records in the Git history of the dataset.
One thing first: datalad add is a very old command (and deprecated, I think). Please always use datalad save (it combines staging and committing) instead of datalad add.
The aim would definitely be to have your scripts saved in Git (and not git-annex). This makes those scripts available on GitHub and for CI, does not add the complexity of file locking to modifying the scripts, and keeps all version control experiences of those files precisely as how they would be if stored in a sole Git repository.
As for using git add + git commit versus datalad save to achieve that: Both methods are possible, it depends a bit on how you and your users prefer it to be. You can always use git to commit files into the Git portion of your dataset. You can also, however, add a configuration (so called “largefile rules” in a .gitattributes file) to the dataset that configures DataLad to store certain files/file types/folders/files of a certain size/… in Git instead of git-annex. There is documentation on how to do this by hand here, and there are also “dataset procedures” that can do such a configuration automatically (e.g., cfg_yoda, which creates a code/ directory and saves all files that are placed in there into Git), or you could write a custom procedure for your usecase and distribute it in your institute (docs on this here).
This issue is mentioned here : https://github.com/datalad-handbook/book/issues/596
In the meantime, do you or anyone has access to this file and could he/she hand it over to me ?
Procedures are still obscure to me, and this would be of great help to have access to this file, as it seems to do what we need.
I’ll probably come back with many other questions very soon
Thanks again !
First, a heads up : we’re not using RIA stores yet, just git siblings.
Also, I’ve written the setup procedure (to configure the storage sibling) from scratch anyway
I’ve got one more question (tell me if I should post another thread) :
The sibling on our cluster was created with the default settings, but we’d like to change the permissions (basically r+w for the group). Can we safely chmod the whole git repository to 640 ?
My feeling is that it takes more than that (e.g. updating git config core.sharedRepository as well).
I’d like not to mess up the permissions.
Thanks,
As far as I can tell this is still an issue. I would love to get a look at cfg_inm7.py so that I could have a guide to automate my own RIA store. If someone could point me to an accessible copy that would be fantastic.
we are not using the dataset procedure anymore. For a couple of DataLad versions the create-sibling-ria command should provide all relevant functionality for this. If you have a demand beyond its offerings, please let us know what is missing.