I am a beginner in the field of neuroimaging. For the past few weeks I have read various research papers related to Tractography. I am looking to implement some algorithms. For that I have been trying to collect some datasets but I am getting confused of what is actually needed to implement and validate the tractography algorithms. In some datasets I get only .nii files and whereas in some i get .trk files, .fib files and various masks. Does anyone have any dataset arranged in a structured manner with implementation as it will be very useful in getting me started for implementation.
Raw data from a scanner is typically in DICOM format (though proprietary Philips PAR/REC files are sometimes seen). While some DICOM files have the extension .dcm, many have no file extension. Since each vendor describes diffusion data differently, DICOM is not one format but many. One typically converts these images to NRRD format (.nrrd or .nhdr, if you use Slicer) or NIfTI (.nii, other tools).
Initial processing typically removes artifacts and noise (e.g. degibbs, dwidenoise) and spatially undistorted images (e.g. TOPUP/Eddy). Then the DWI images are fitted as tensors (e.g. either as a 3x3 matrix or V1, V2, V3), or more sophisticated models of ODF. The fitting also provides scalar values like TRACE, MD, MK, etc. These Voxelwise values are typically saved in NIfTI format. Some tools store these in custom formats (e.g. DSIstudio .fib).
Optionally, voxels can be connected together using streamlines. Popular formats include TCK, TRK, BFloat, DAT, and VTK (confusingly also saved as .fib).
Hi @Chris_Rorden. Thanks for the response. I have some queries. I have been reading about the fiber reconstructions like representing DWI using tensors (DTI), q ball, CSD, etc., In one paper titled Deep Tract (By Itay Benou) I saw that an RNN model has been used instead of these above models to form a fODF.
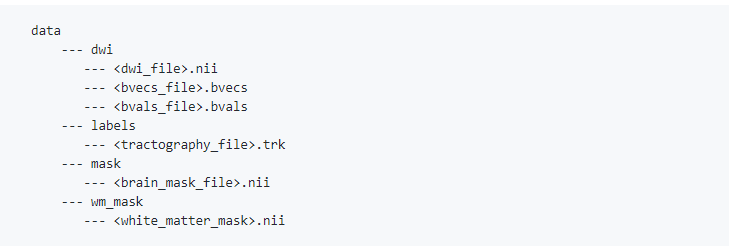
In the above snippet it provides what is required to implement the algorithm. I have downloaded some datasets like ISMRM 2015 challenge, Fiber Fox. But in these datasets I have the .nii files, and the ground truth of the 25 fiber bundles.
As per the Github repository for the above paper the data format is