May you please rephrase this question, I am sorry but I am not sure I understand what you are asking.
But also, there are other ways to parallelize than what is listed in that documentation. For example, if you are on a cluster, you can use a SLURM job array for example, or even just looping over subjects and putting an & after your dcm2bids command will tell terminal to not wait to start the next dcm2bids command (the downside of that is that you do not explicitly state how many jobs can run at one time, so you have to be careful to have your loop only have as many subjects as you want to run in parallel. There probably is a way to control how many processes go at once, but I do not know the syntax off the top of my head, ChatGPT may be helpful in that regard).
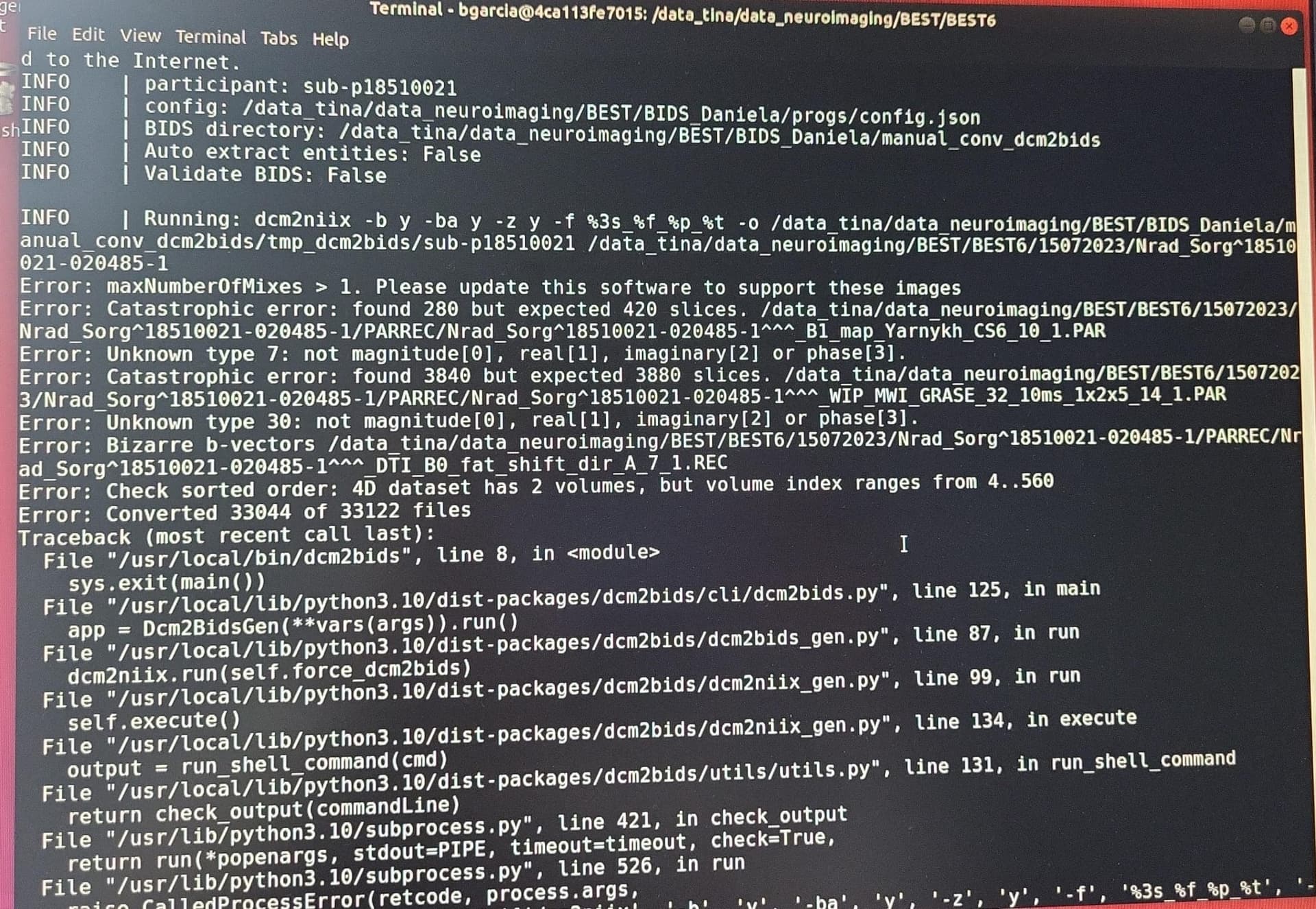
I have one question because im trying to run dcm2bids with GNU parallel for 200 subjects, but it seems to have an error when it is running dcm2bids. It says: catrastophic error: found 3840 but expected 3880 slices. Next, cite the PARREC dir and says error unknown not magnitude, real, imaginary or phase (even the tmp dcm2bids have those files!!), and doesn’t convert the dicom files to bids…but only for some specific subjects, not all of them.
The thing is i have in the subjects folder different files such as: DICOM and PARREC file. Do you think this is the reason for what it is getting an error? Also, do I have to do dcm2bids helper even if there are 200 subjects and im working with GNU parallel?
It is hard to say without knowing your command you’re running, your config file, and some json contents.
Do you know what kind of files this is referring to? That is, is it when converting bold, dwi, anat, etc?
Do you notice any difference in the dcm2niix outputs for failing subjects?
Helper should only be run once, assuming everyone has the same or similar set of acquisitions, just so you can get the naming conventions right for the study.
My config file has: anat, asl, t2map, t2star. For other subjects, it worked very well without problem!
For failing subjects, tmpdcm2bids shows less items for dcm2niix than expected (sometimes around 900 instead of 1200 items that contain json and nii files).
Finally, I just do dcm2bids scaffold, but don’t use dcm2bids_helper. Should I do that?
Please in the future post error messages as text instead of screenshots, formatted with tick marks so it reads nice
Like this. (You can also use the </> button in the text editor for this)
Based on the error, it looks like some subjects might have corrupted data or that the dcm2niix version doesn’t support the images. Did you update dcm2niix?
There appears to be another error at the bottom of the screenshot but it is cut off so I cannot advise on that yet.
dcm2bids_helper is just so you can get the naming conventions for the config file. If you have a working configuration you do not need that command anymore.