Hi all,
I’m running into some unexpected results in a whole-brain decoding analysis using Nilearn and Scikit-Learn, and I’m trying to understand where the differences are coming from.
Background
In my setup, I perform within-subject whole-brain fMRI decoding of memory valence using single-trial activity maps (average activity across 10 TRs of a denoised and z-scored time series for each trial), estimated for individual trials across four runs. In each run, participants were cued to recall 10 unique negative and 10 unique positive memories (the same memories repeated across runs). The goal is to build (and test) a model that predicts memory valence based on the whole-brain activity pattern (about 15000 voxels). I take all runs together (80 samples in total), and use 20-fold leave-one-memory-out (each repetition of the memory across the 4 runs) for cross-validation, training on the 76 remaining memory trials and testing on the 4 remaining memory trials. I try to predict binary memory valence (positive or negative).
Issue
With Nilearn, I get very high classification accuracies (average accuracy across participants about 85%). When I tried to replicate in a more extensive Pipeline in sklearn using SVC(C=0.1, kernel="linear",tol=1e-4, max_iter=int(1e4)), I could not replicate these high accuracies (average about 60%). I figured out that this huge drop in performance came from the difference between LinearSVC (Nilearn standard) and SVC in scikit-learn - the two implementations use different optimization and regularization strategies, which might explain the difference.
Notably, though, the high performance with LinearSVC (and the large difference between SVC and LinearSVC) did not seem stable across different preprocessing options, specifically the decisions surrounding z-scoring (i.e., standardizing each voxel across all 80 samples using NiftiMasker, or doing z-scoring within the cross-validation loop using StandardScaler). I systematically varied these options, and checked the effects using the code below:
from sklearn.svm import SVC, LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import LeaveOneGroupOut
from sklearn.model_selection import cross_val_score, cross_validate
from nilearn.maskers import NiftiMasker
from nilearn.decoding import Decoder
##### DEFINE PIPELINE CONSTRUCTION #####
def construct_pipeline(decoder_name, standard_scaler=True):
steps = []
if standard_scaler:
steps.append(('scaling', StandardScaler()))
if decoder_name == "svc":
steps.append(('svc', SVC(C=0.1, kernel="linear",tol=1e-4, max_iter=int(1e4))))
elif decoder_name == "linear_svc":
steps.append(('svc', LinearSVC(C=0.1, tol=1e-4, max_iter=int(1e4))))
elif decoder_name == "logistic":
steps.append(('logistic', LogisticRegression(C=0.1, solver="liblinear", dual=True, tol=1e-4, max_iter=int(1e4))))
else:
raise ValueError(f"Unknown decoder name: {decoder_name}")
return Pipeline(steps)
# Create trial-level labels and groups
y = np.tile(valence_labels, 4) # (80,) - valence for each trial
memory = np.tile(stimulus_labels, 4) # (80,) - stimulus ID for each trial
runs = np.array([20*[i] for i in run_labels]).flatten()
#### Save results
results = []
#### Decoding settings
cv = LeaveOneGroupOut()
standardscaler_options = [True, False]
maskerstandardize_options = [True, False]
for sub in subjects:
print(f"Loading all info for {sub}...")
brain_mask = obtain_brain_mask_allruns(sub, derivatives_folder, gm_masked=True) # Obtain brain mask
beta_maps = obtain_all_beta_maps(sub, estimation, denoising, stimulus_names) # Load beta maps for all 80 memory trials
beta_maps_concatenated = concatenate_beta_maps_nifti(beta_maps) # Concatenate beta maps into a 4D XYZ x n_samples (80) Nifti Image
for m_std in maskerstandardize_options:
print("")
print("Masking fMRI image...")
masker = NiftiMasker(
mask_img=brain_mask,
standardize=m_std, # Decide if you do mask standardization or not
smoothing_fwhm=None,
runs=runs, # Makes sure that the standardization is done within a run and not all runs together
memory="nilearn_cache",
memory_level=1,
verbose=0,
)
fmri_masked = masker.fit_transform(beta_maps_concatenated)
for s_std in standardscaler_options:
for decoder_name in ["linear_svc", "svc"]:
print(f"Decoding with settings: masker_standardize={m_std}, scaler_standardize={s_std}, decoder={decoder_name}")
pipeline = construct_pipeline(decoder_name, standard_scaler=s_std)
cv_results = cross_validate(
pipeline,
fmri_masked,
y,
groups=memory,
cv=cv,
scoring='accuracy',
return_estimator=True,
return_train_score=True
)
# Extract metrics
test_acc = cv_results['test_score']
estimators = cv_results['estimator']
print(f"Accuracy = {test_acc.mean():.3f}")
results.append({
"subject": sub,
"decoder": decoder_name,
"masker_standardize": m_std,
"scaler_standardize": s_std,
# aggregate metrics
"accuracy_mean": test_acc.mean(),
# per-fold metrics
"accuracy_per_fold": test_acc,
# trained models
"estimators": estimators
})
print("")
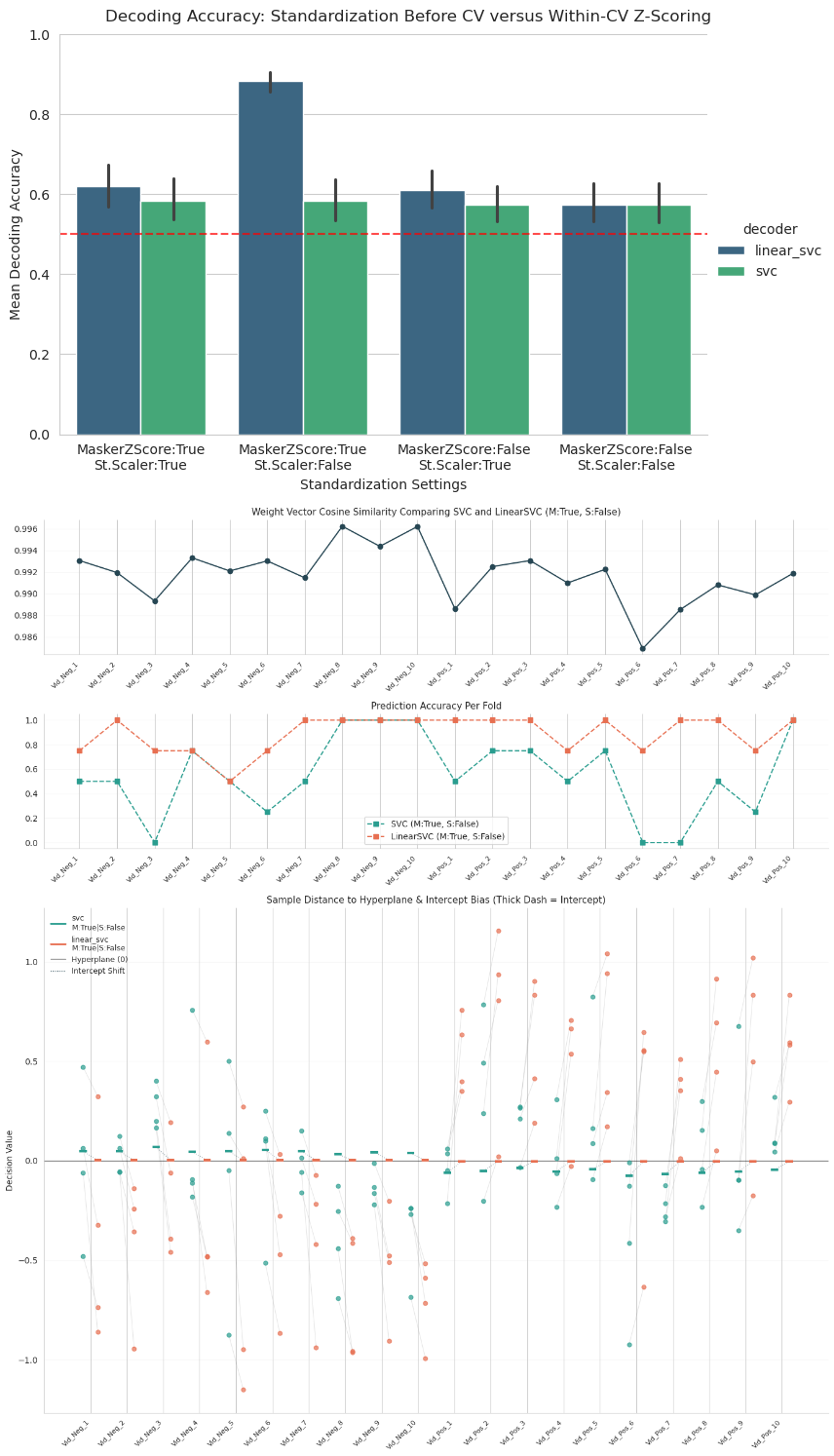
Overall conclusion from this; when using Nilearn’s standard settings (z-scoring outside the CV-loop using NiftiMasker and using LinearSVC as a decoder), I get great decoding accuracy, whereas tweaking any settings in the pipeline leads to a massive drop in accuracy. (See the top panel in the figure below for a visualization).
I moreover compared model parameters and predictions between LinearSVC and SVC for one specific subject in the MaskerZScore:True,St.Scaler:False pipeline, which had the biggest performance difference across classifiers. Interestingly, across the different folds, the model weights (cosine similarity for all voxel weights) are almost identical between the two models, although prediction accuracies and decision values differ greatly (as visible from the bottom plot, LinearSVC finds a way to separate the two classes a lot better). Overall, the different models therefore do seem to find a similar separating hyperplane, but yield very different predictions nevertheless:
Closing
After this troubleshooting, I’m not sure where exactly these massive differences come from (given that the weights are pretty similar across models), and which pipeline I should trust and proceed with. I tried formal permutation testing (shuffling valence labels of the 20 unique memories 500 times) of the high-performing Nilearn-standard pipeline (LinearSVC with z-scoring each voxel across all samples outside the CV-loop). This yields high significance of this pipeline (average permuted decoding accuracy around chance level whereas decoding accuracy with the original labels was around 85%, see above). However, above checks show that this high performance and pipeline is very unstable depending on z-scoring decisions, and I’m not sure if these very high accuracies should be trusted at all, especially for decoding of valence of internally generated memories. Moreover, following traditional ML conventions, doing z-scoring across samples before cross-validation might carry the risk of data leakage, where information from the training set leaks into the test set, inflating accuracies. However, this is the standard approach that the Nilearn Decoder object uses and in that sense somewhat standard practice.
Is there anyone that has had similar experiences using these decoding approaches, knows where this effect may come from, or has advice on how to proceed? Any help would be appreciated!
Thanks in advance. I would be happy to explain things further, or to share more code or data in case someone wants to play around with it.
Best,
Floris
(Package versions: scikit-learn = 1.7.2, nilearn = 0.12.1)