That’s right, the ROI image should be used as mask_img.
If you have a nifti file with your ROI, then I would just stick to apply_mask for now. However, if you want to look into using nilearn’s masker classes (including NiftiMasker), this example is probably a good place to start. Essentially, the NiftiMasker is a special class that stores an ROI from a nifti file or image, and it can be called using its class methods rather than with functions like apply_mask. This can be useful when you want to perform some preprocessing on your data as you apply the mask, such as smoothing or bandpass filtering. However, you probably don’t want to do that in this situation, so I wouldn’t worry about it for now.
Hi Taylor, just a follow up questions, so after I created the LSA trial_type (e.g., Right_001 in this case), I should use the GLM to model each single trial (e.g., Right_001, Left_001, etc.,) via putting “trialwise_conditions” into glm.fit command as the events file, right?
After this, I can use the follow command to get a series of beta weights and plot them for correlation matrix, correct?
"for condition in trialwise_conditions:
beta_map = glm.compute_contrast(condition, output_type=“effect_size”)
# Drop the trial number from the condition name to get the original name.
condition_name = “".join(condition.split("”)[:-1])
condition_beta_maps[condition_name].append(beta_map)
condition_beta_arrs = {}
for condition, maps in condition_beta_maps.items():
beta_arr = masking.apply_mask(condition_beta_maps, mask)
condition_beta_arrs[condition] = beta_arr
beta_arr = masking.apply_mask(imgs, mask_img)"
No, the LSA events DataFrame (lsa_events_df) is what you should use. trialwise_conditions a list of conditions in the LSA-formatted events DataFrame. With LSA, you’ll be using one GLM to fit all of the trial-wise conditions at once, so you only need to provide it with lsa_events_df.
The only issue I see is the last line (beta_arr = ...). Since you already get beta_arr earlier in that for loop, and imgs and mask_img aren’t defined, you should remove that line.
I also noticed that you replaced _ with * as the delimiter between the condition name and the trial number. As long as you use that in the events DataFrame as well, it should be fine.
Yea, I was confused about the last beta_arr command line, I will delete it. Also, while I run the condition_beta_arrs = {}, there is an error saying “name ‘masking’ is not defined”. The only masking. there is “masking.apply_mask”, I guessed I should import the module, so I did “from nilearn.masking import apply_mask” but still did not work. Do you know what it might be?
You imported just the apply_mask function, so you could call apply_mask, but not reference it within the masking module. To make your code work you need to import the whole masking module:
Hi Taylor, thanks again! I have two questions, which regarding to different datasets, the first one is mine and the second one is the dataset you used to demonstrate the LSA. I downloaded it online and test your script in order to better understand how it works.
My first question is that in my data, it is a block design which means I have multiple trials (e.g., 45) just for one condition in my functional data, do you think I need to adjust anything on this part?
It comes out an error after I ran these commands, saying that "ValueError: File not found: ‘XXX’ " - XXX is my experiment condition.
I downloaded the data in which you used its event file to demonstrate to me before (sub-108TUSW011005_ses-1_task-imagery_acq-Fs2_run-01_bold.nii.gz), and ran your script as well, it also comes up with an error saying (ValueError: File not found: ‘Right’). There are three conditions in the event files, which are Right, Left, and Both. Do you know what might be the issue here?
Unfortunately, I don’t know. I am really only familiar with this issue in the context of task-based functional connectivity (in which case, I would recommend using a psychophysiological interaction model instead of beta series, per Cisler, Bush, & Steele [2014]). I don’t know what the preferred approach for block designs is for RSA analyses.
Can you share the full traceback? It would help to know which line raised the error.
File “/Users/jd/opt/anaconda3/lib/python3.9/site-packages/nilearn/_utils/niimg_conversions.py”, line 271, in check_niimg
raise ValueError(“File not found: ‘%s’” % niimg)
ValueError: File not found: ‘Self’
and if you open the line, it is something like this:
raise ValueError("File not found: '%s'" % niimg)
elif not os.path.exists(niimg):
raise ValueError("File not found: '%s'" % niimg)
The LSA events DataFrame should look something like this (reduced to just the first 10 events):
onset
duration
trial_type
old_trial_type
1
8
7
Right_001
Right
3
23.6
7
Left_001
Left
5
38
7
Both_001
Both
7
50.9
7
Both_002
Both
9
66.9
7
Both_003
Both
11
82.9
7
Left_002
Left
13
97.2
7
Right_002
Right
15
111.1
7
Right_003
Right
17
125.6
7
Left_003
Left
19
140.1
7
Both_004
Both
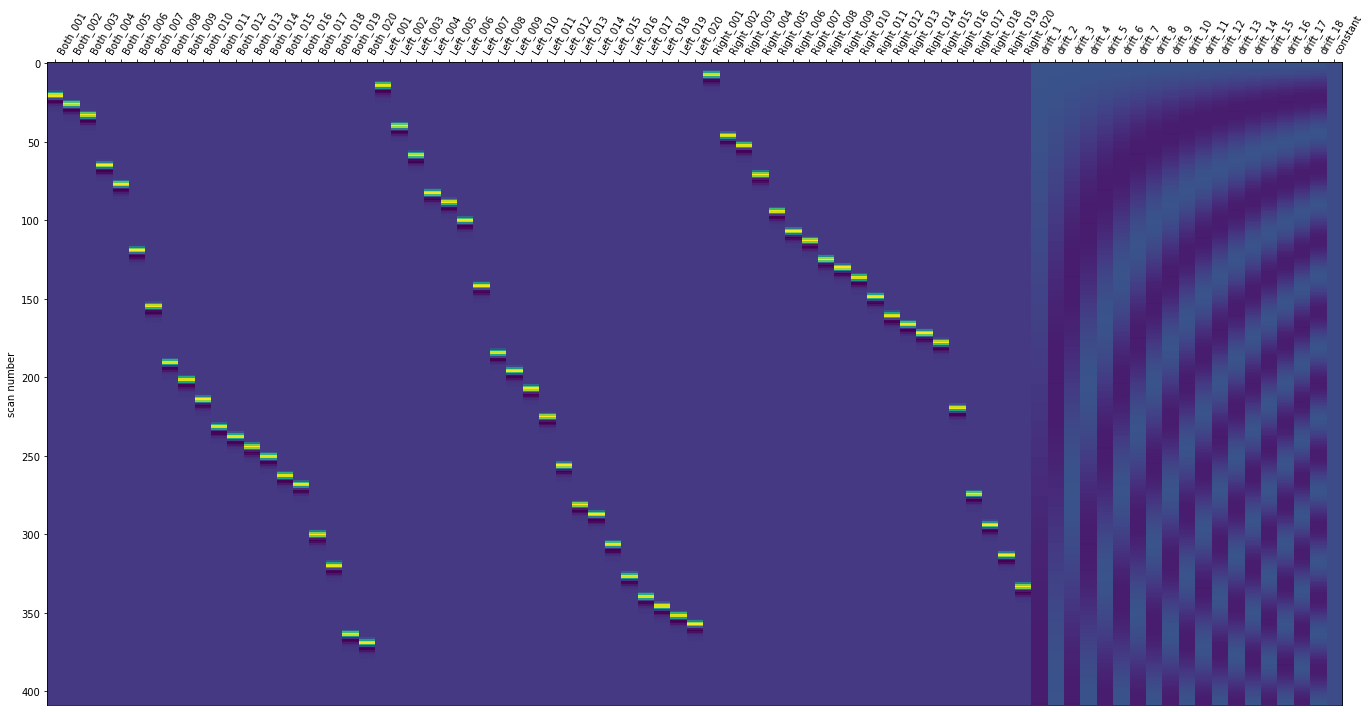
The design matrix should look something like this, with the columns on the far right varying based on the drift model you use and your choice of confounds:
Thank you so much for your help, it works for my data and the open resource data. Just out of curiosity, can you explain this step to me a little bit once you have time? Like what it does.
masking.apply_mask extracts the data in an image-like object (e.g., a Nifti1Image) from the voxels defined by a mask (also an image-like object). It returns a time-by-voxels numpy array of the masked data.
In the specific step above, you’re using apply_mask to get the data from your ROI’s voxels (your ROI being masker) out of the maps variable, which is a list of statistical images. Then you take the resulting 2D array and put it in a dictionary, where the keys are the conditions and the values are the 2D arrays of trial-wise beta values for each of the voxels in the ROI.
Thanks Taylor! That totally makes sense! Do you mind telling me a little bit about what the “map” here serves beta_arr = masking.apply_mask(maps, mask)? I found a little bit hard to picture it
Hi Taylor, I have another question and hope you can answer once you have a moment. So I am trying to put the confounds into my analysis, do you have a suggestion like where I should implement this? I guess it should be in glm.fit step, and then extract the beta-weights? I tried to do that but it comes up an error saying that “Rows in confounds does not matchn_scans in run_img at index 0”. I defined my confound tsv file path first and the object type is str, whether it will works?
If you are splitting up your scans into trials, you will need to extract the corresponding rows in the TSV as well, so there is not a mismatch in number of volumes and number of confound observations in each glm.
There are several places where the confounds can be introduced (e.g. in a separate image cleaning step using nilearn.image.clean_img, nilearn.signal.clean, or by including the confound rows in your first level design matrix). I don’t have all of your code so I don’t know if there’s one that would be especially convenient, but (and if I’m wrong please correct me) I don’t think there should be much of a difference between the methods if done correctly.
I think I wanted to use frame-wise displacement as confound in firstlevelmodel, should I specify this in my glm.fit command like glm_self_lNACC.fit(func_self_filename,events = lsa_events_self,confounds = confound_self_fd)? Also, like what you said I am splitting up my scan into trials, how can I extract the corresponding rows in the TSV and then match for it to avoid mismatch? I guess the error Rows in confounds does not matchn_scans in run_img at index 0 is about mismatch? here is the traceback:
# Build the experimental design for the glm
run_img = check_niimg(run_img, ensure_ndim=4)
if design_matrices is None:
n_scans = get_data(run_img).shape[3]
if confounds is not None:
confounds_matrix = confounds[run_idx].values
if confounds_matrix.shape[0] != n_scans:
raise ValueError('Rows in confounds does not match'
'n_scans in run_img at index %d'
% (run_idx,))
confounds_names = confounds[run_idx].columns.tolist()
else:
confounds_matrix = None
confounds_names = None
You might want to consider more than just FD as your confounds based on the paper. Usually when I see FD as a confound, it is the average FD and is used as a second-level confound.
If confounds_self_fd is a numpy array or pandas dataframe then yes that code will work. How to extract the rows is dependent on whether you are more comfortable in numpy or pandas. If you convert your confounds dataframe to a numpy array, you can index a row with confounds_array[i,j], where confounds_array is the name of your converted dataframe, i is the row(s) you want to extract, and j is the column(s) that has the covariate of interest. In pandas you can use the .loc functionality to extract rows (see here).
Sure - I will consider the six motion values but first I have to figure out how to put then into covariates!
Yes, the confounds_self_fd is a pandas dataframe. The problem is I have 45 trials and correspond to my time event file, however the confound tsv file I have right now is in TR format (e.g., 153 TRs, then there are 153 rows in that file), do you have any suggestions on how to match the values in confound file to my trial?
Something like this (you’ll need to get the scan times for the trials and replace X and Y with them)
TR = 2 #put your TR there
n_vol = 153
times = np.arange(0,n_vol*TR,TR) # list of times associated with each TR
begin_of_trial = X # in seconds
end_of_trial = Y # in seconds
beginning_index = np.where(times < begin_of_trial)[0][-1] # get earliest scan index included in trial
end_index = np.where(times > end_of_trial)[0][0] # get earliest scan index included in trial
scan_indexes = np.arange(beginning_index, end_index)