Hi Steven, thank you so much for your script. I tried your script and my understanding is that this script will create a time file for a subject, correct? But I actually have the time event file for each subject already, and most importantly, we use randomized jitter in our task, so I guess the script will not work very well.
Sure, definitely, I will create another new topic! Thanks for reminding
I am not sure what “time file” means in this context, but the script creates the indexes, i.e. rows that correspond to the TRs of the trial. You would need to loop over trials, which is something you are presumably already doing.
Sorry to jump back in on this thread so much later, but I don’t believe there’s any need to do anything to the confounds in a beta series model. AFAIK, you should only need to do that if you’re chopping up the raw time series. The LSA and LSS models model all trials and all volumes in the dataset.
Hi Tyalor thank you so much for your help here. So we have a pipeline for data analysis here and there are two parts for data processing: preprocessing and postprocessing. I believe preprocessing steps are very similar to what we have in the filed, and postprocessing is more about regressing out the confounds like motions and other nuisance. Based on what you said AFAIK, you should only need to do that if you’re chopping up the raw time series, should I just use the preprocessed file? and if I really concern about the confounds, should I use the post-processed file?
Sorry I know this go too beyond the original topic, I will keep it short and if there are more issues about this, I will open another conversation so that other people can correctly direct to what they need…
Hi Taylor, I tried to adapt the script for LSS you provided for my case but there is an error saying UndefinedVariableError: name 'Self_000' is not defined - Self is my condition name, so I wondered whether there is anything I missed or I have done something wrong while I adapting your script?
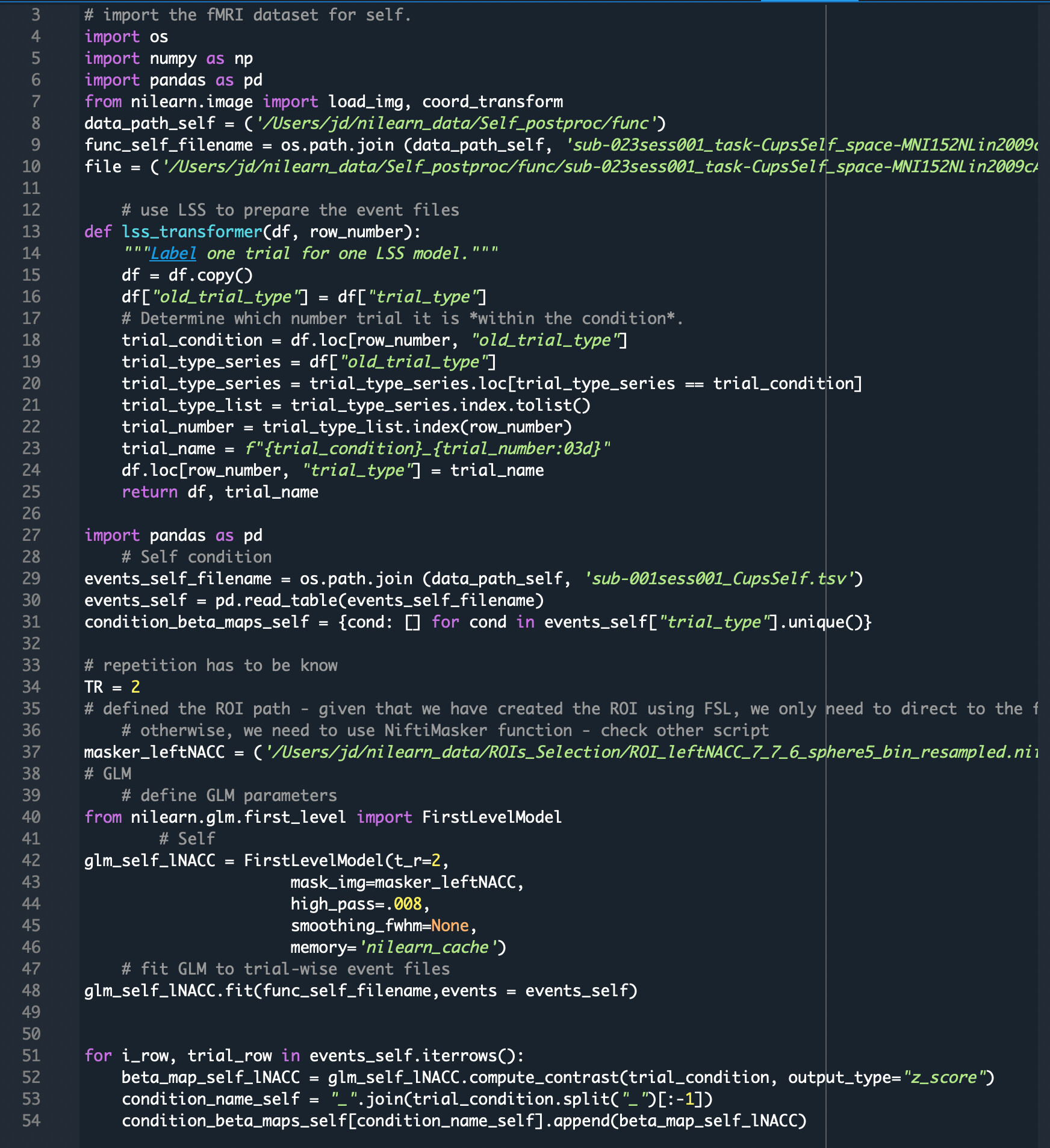
I found it hard to format the code here in an easy way for you to read, so I am just gonna upload the screenshot hope you don’t mind. Also, when I run the glm.fit, should I use my original events_self file? Or the newly created LSS-event file? I guess there should be a transform like LSA script?
Run the model(s) on the preprocessed data, but include the confounds in said model(s).
If you use the original events DataFrame, then you are fitting a standard GLM, with one column per trial type.
There isn’t just one LSS events DataFrame, there needs to be one for each trial in each condition you care about. You need to set up a for loop going through the trials you want to get beta maps for, run the lss_transformer function on the original events DataFrame for each trial, fit the model using the LSS events DataFrame for that trial, and collect the beta map for the associated trial-specific condition.
Did you mean the FirstLevelModel? I don’t know whether there is a parameter there, I put this argument there but not working, saying TypeError: __init__() got an unexpected keyword argument 'confounds'. It is a data frame. Here is my script: from nilearn.glm.first_level import FirstLevelModel # Self glm_self_lNACC = FirstLevelModel(t_r=2, mask_img=masker_leftNACC, high_pass=.008, smoothing_fwhm=None, confounds = confound_self_fd, memory='nilearn_cache')
Yes, this makes sense to me. I should use the newly created LSS-event file.
Do I need to write a new for loop? Or it is on the example code you provided already? Also, I tried to run lss_transformer but I don’t know what I should put inside for the row number lss = lss_transformer(df, row_number)
Yes, you need a for loop, but it’s in the example I wrote so you don’t need to write one from scratch. The row number indicates the trial (since each trial gets its own row in BIDS events files) and the row corresponds to the loop number in the for loop. Once you adopt the for loop from my example you’ll have the iterator to use as row_number.
yes, that’s where I put the confound, I used frame-wise displacement as an example to test, I put it in the glm. fit as indicated in the website: glm_self_lNACC.fit(func_self_filename,events = lsa_events_self, confounds = confound_self_fd). However, there is an error saying that ValueError: Rows in confounds does not matchn_scans in run_img at index 0
I will take a look at again and adapt it! You meant after I run def lss_transformer(df, row_number): I should be able to run lss = lss_transformer(df, row_number) function to get a new list of the trials for my GLM? I will take a look at!
Hi Taylor, I think the script for LSS you provided should work for me - the reason why I had difficulties using it is I missed this part before running glm.fit, where I have to put in an LSS-formatted event file.
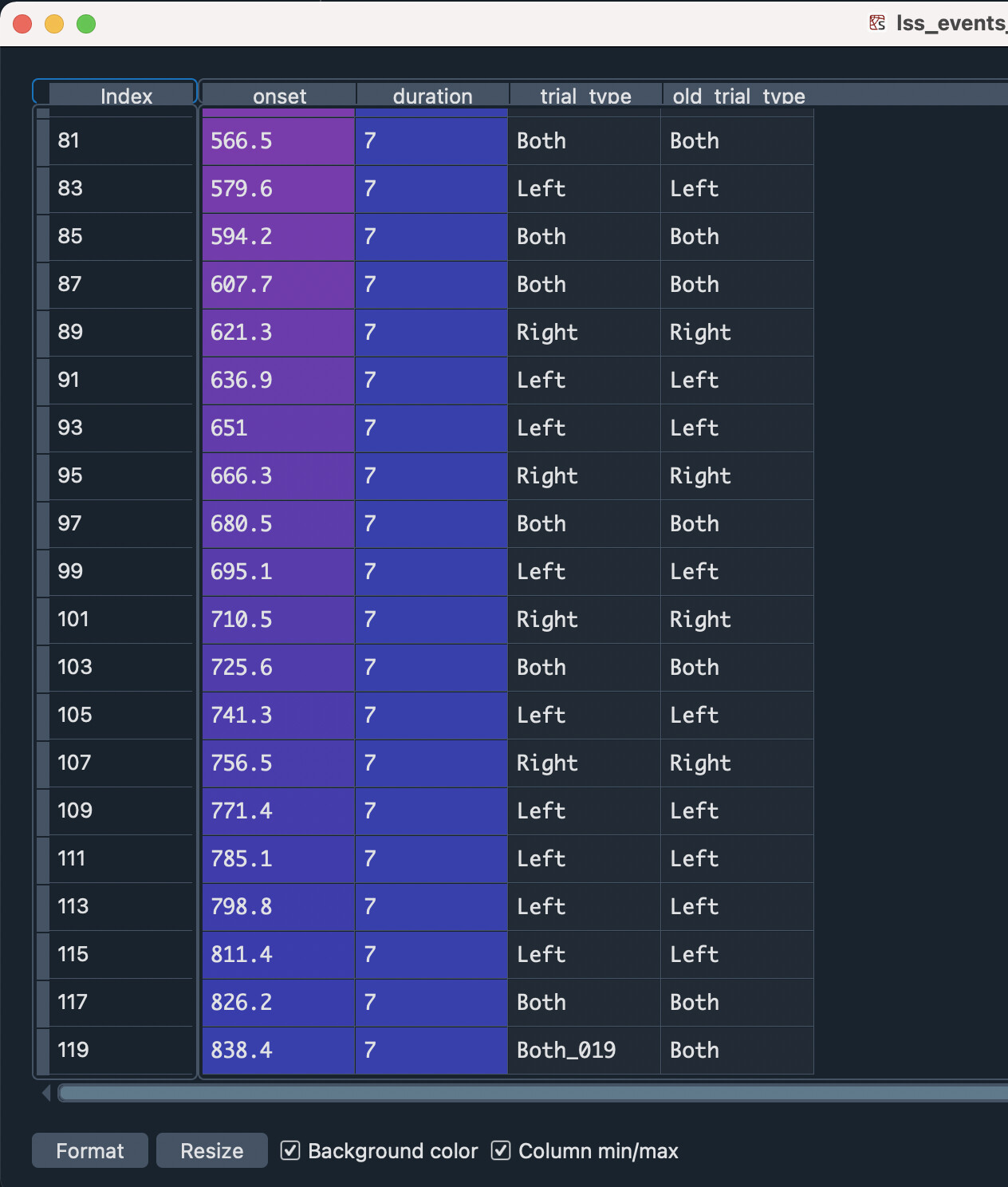
However, I encountered another issue with the script. Specifically, I only got the last trial as an LSS-formatted trial in the “new” trial type, in my case, it only shows Self_044 (as I have 45 trials for that condition) but not for other trials. It only provided me one beta map later - I guess it is for Self_044. I was thinking that I might have done something wrong while adapting your script, and then I went back to the example tsv file (i.e., sub-108), and was able to replicate the same issue: only the last row has the LSS-format (see screenshot). So I guess there is something wrong with the script, do you mind looking at it again and letting me know? Really appreciate it!
Perhaps the confounds file has some additional rows due to non-steady-state volumes being removed or something. How many rows are in confound_self_fd, not including the header? How many volumes are in func_self_filename?
Yes, you need to collect the beta maps in the for loop. Below is a portion of the example code I shared. Note that the step that calculates and collects the trial-wise beta maps is within the for loop. Otherwise, the only GLM you will have access to is the one from the last trial.
The volume of the functional file is 143, and the number of rows not including the header is 139.
Hi Taylor, I wanted to let you know that I figure this out (have not 100% sure but it works now and have 45 betas in that loop), I dont want to waste you any time on this. It did not work because I defined something wrong as I copied the things from LSA script, and also I did not put the GLM under the for loop, that’s why it did not run all the 001…045 for me. After careful inspection and think about what you said about “Note that the step that calculates and collects the trial-wise beta maps is within the for loop” , I figured out
I am a little bit lost here. So I guess beta_map = glm.compute_contrast(trial_condition, output_type="effect_size") command will let me collect the beta maps in the for loop as the trial_condition has been defined in the for i_row, trial_row in events_df.iterrows(): and the def lss_transformer(df, row_number):? Or I need to write some for loop script to make it works?
Also, do I need to adjust anything here def lss_transformer(df, row_number): and for i_row, trial_row in events_df.iterrows(): lss_events_df, trial_condition = lss_transformer(events_df, i_row) ?Because in the outcome file lss_events_df on the variable explorer window, only the last row has LSS-formatted trial.
I aslo wanted to let you know that I solved the confound file issues - I just need to make the header as true so that the script can identify the first row. I have a follow up question, while conducting trial-based modeling like LSS or LSA, do you think I should still use motions as covariates to regress out this effect? I am thinking whether it would reduce my analysis power, especially considering it is trial-based modeling. Do you have any thoughts about this?
Since you’re collecting beta maps, I don’t think that analysis power is a real issue, as long as you have some degrees of freedom remaining (meaning the number of columns is still greater than the number of rows). If you were using the test statistics, then the degrees of freedom would be more of an issue. I would recommend using your standard model’s confounds, including motion parameters, but I am not 100% confident about that.
Thanks Taylor. Yea, I don’t know how the confounds are modeled and controlled technically. I could imagine running a whole GLM while controlling confounds. But right now I am running GLM for each trial, I was thinking should I get a specific row from the confound file that corresponds to that trial I am modeling? I am not sure whether I should just put the whole confound file into the GLMs for each trial without specification.
Hi Taylor, no worry about that - I figured it out - it is bc I did not binarize the mask…
Hi Taylor, I have an extra question related to this, so I am extracting the signal and calculating the coefficients from the ROI. Everything went well. However, when I run this with an atlas, it comes up error, saying that Given mask is not made of 2 values: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96]. Cannot interpret as true or false this is the vmPFC atlas. However, with other coordinate-based ROIs, I don’t have this issue, do you know why? Is there anything I did wrong while defining the ROI, or you think it might be something about the script? Thanks