I’m new to fMRI analysis and I’m working on my first dataset. I’d like to test whether a continuous self-report score is associated with the BOLD signal.
I’m using Nilearn’s first-level GLM. The typical workflow uses make_first_level_design_matrix(), which expects an events table with a trial_type column to define conditions/contrasts. In my case, however, I don’t have discrete experimental conditions; instead, I have a continuous rating/score [per trial], and I want to model its relationship with the BOLD response.
From what I understand, this should not be treated as a parametric modulator. I found suggestions to use compute_regressor() to build such a regressor manually, but I’m not sure whether my implementation is correct or whether there is a more idiomatic way in Nilearn.
Thank you for your reply. Before writing the script, I consulted the Nilearn tutorial on design matrices, as well as discussions within the neurostars community regarding parametric modulation.
As I understand it, parametric modulation is used to model how neural responses within a given experimental condition vary as a function of a continuous numerical variable (e.g., reward trials modulated by reward magnitude, relative to control trials). This approach is not well-suited for studies that focus exclusively on reward values without a corresponding non-reward or control condition.
In other words, I intend for my design matrix to use the parametric modulator as the primary independent variable, without including trial_type as a distinct regressor.
My understanding of parametric modulation is that a continuous regulatory variable W modulates the BOLD signal intensity associated with a categorical independent variable A. For example, compared with a control condition, painful stimulation elicits stronger activation in the ACC—a typical effect driven by the categorical variable of experimental condition (pain vs. control). In this framework, parametric modulation can be illustrated by subjective pain ratings: incorporating participants’ self-reported pain scores helps better distinguish and refine the BOLD response to pain relative to the control condition (i.e., treatment × rating → BOLD).
However, my current focus is the main effect of pain rating itself (rating → BOLD) rather than treatment. This effect cannot be directly represented in the trial_type column of the design matrix, as trial_type is typically used for condition contrasts rather than continuous regression.
If you include a “rating” trial_type, that includes the continuous value as modulation, I think that you obtain the design you would like to have.
Sorry if I misunderstood.
HTH,
Bertrand
Also not that your ‘correct’ column only contains 1 and 0 so if you use it as a parametric modulator you are just left with the trials that are correct (that have a 1 in the correct column): so you probably DO NOT want to use correct as a parametric modulation.
I don’t have much context to go by but my hunch would be to:
first divide your trials into 2 categories: correct and incorrect
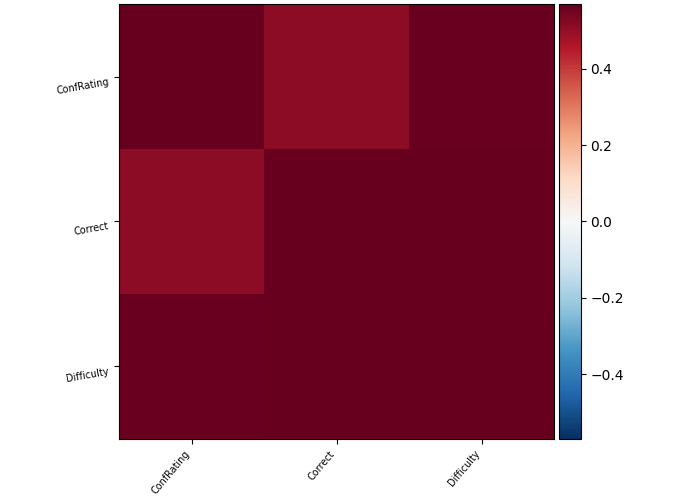
see in general what correlation you have between your ConfRating and Difficulty: because if they are highly correlated in general you may be better of just using one of them as parametric modulator.
pinging @bthirion to double check that I am spouting complete here
I can just add that the correlation between ConfRating and Difficulty is intrinsic to the question you’re asking. It’s not a matter of implementation. Maybe centering these values could help a bit though.
HTH,
Bertrand
What if I only want to use Correc and Difficulty as control variables (like head movement), and explore the relationship between ConfRating and BOLD signals? The protocol you provided seem to be the difference in BOLD signals between correct and incorrect responses.
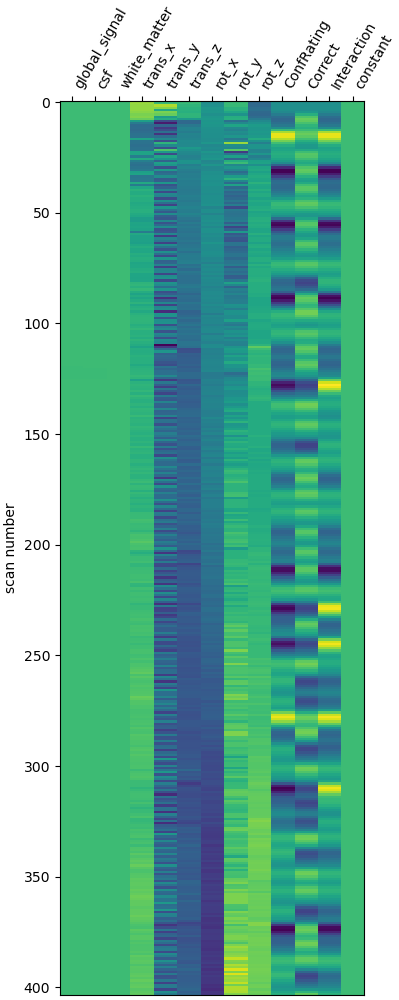
My research topic still focuses on the role of the continuous variable ConfRating and its interaction effect with Correct. I followed bthirion’s suggestion and centered ConfRating within each participant. Then I recoded Correct as -1 and 1, and calculated the interaction between the two. The specific code is as follows: