Thanks for building a great pipeline! I have a few questions I hope you can help me with.
I am using a multiband (3) multiecho (3) sequence. I want to combine the echo’s by averaging them. Are there options available for combining multi echo data in the pipeline? Currently, it gives me back the uncombined, preprocessed three echos which is overloading my storage space.
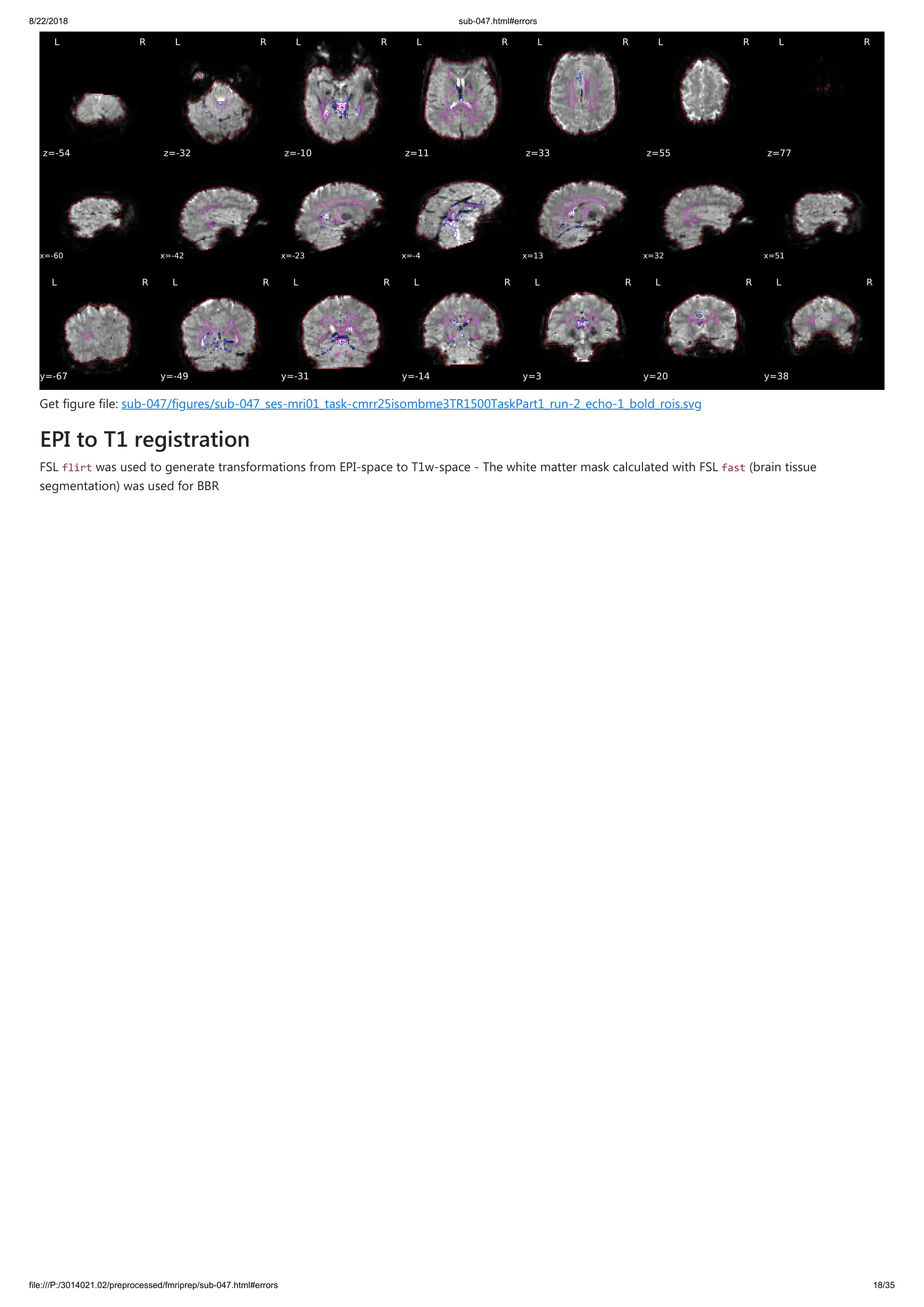
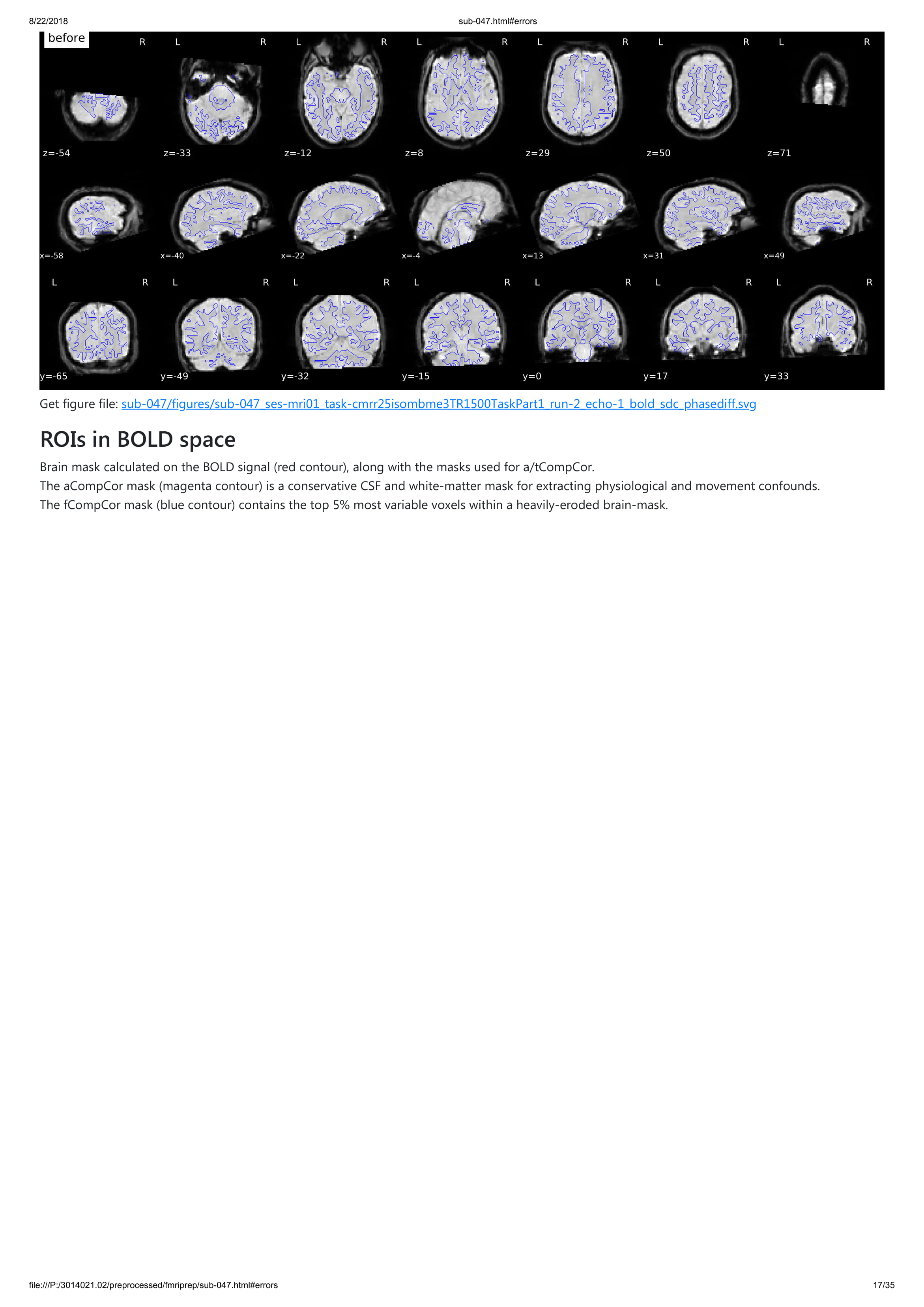
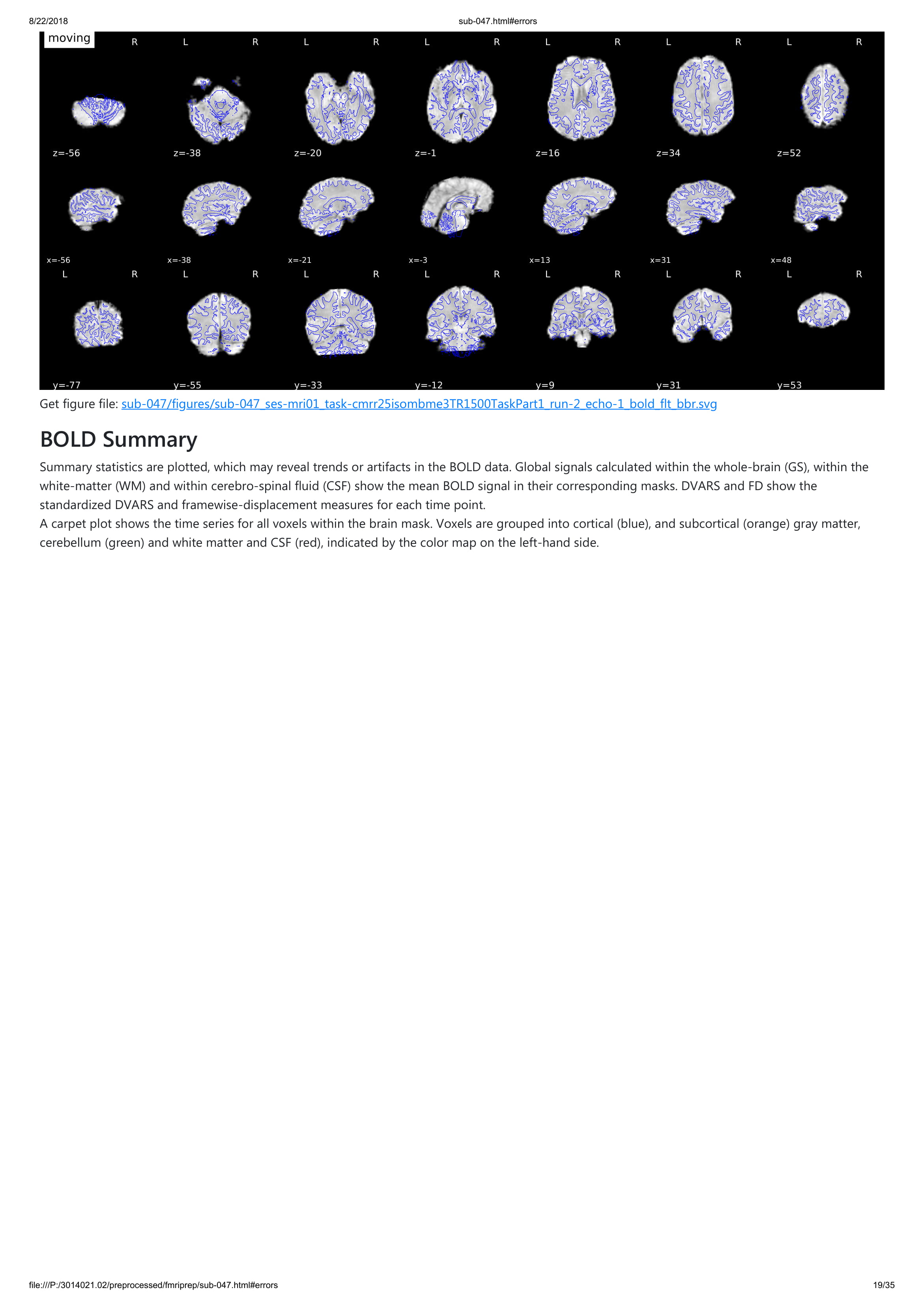
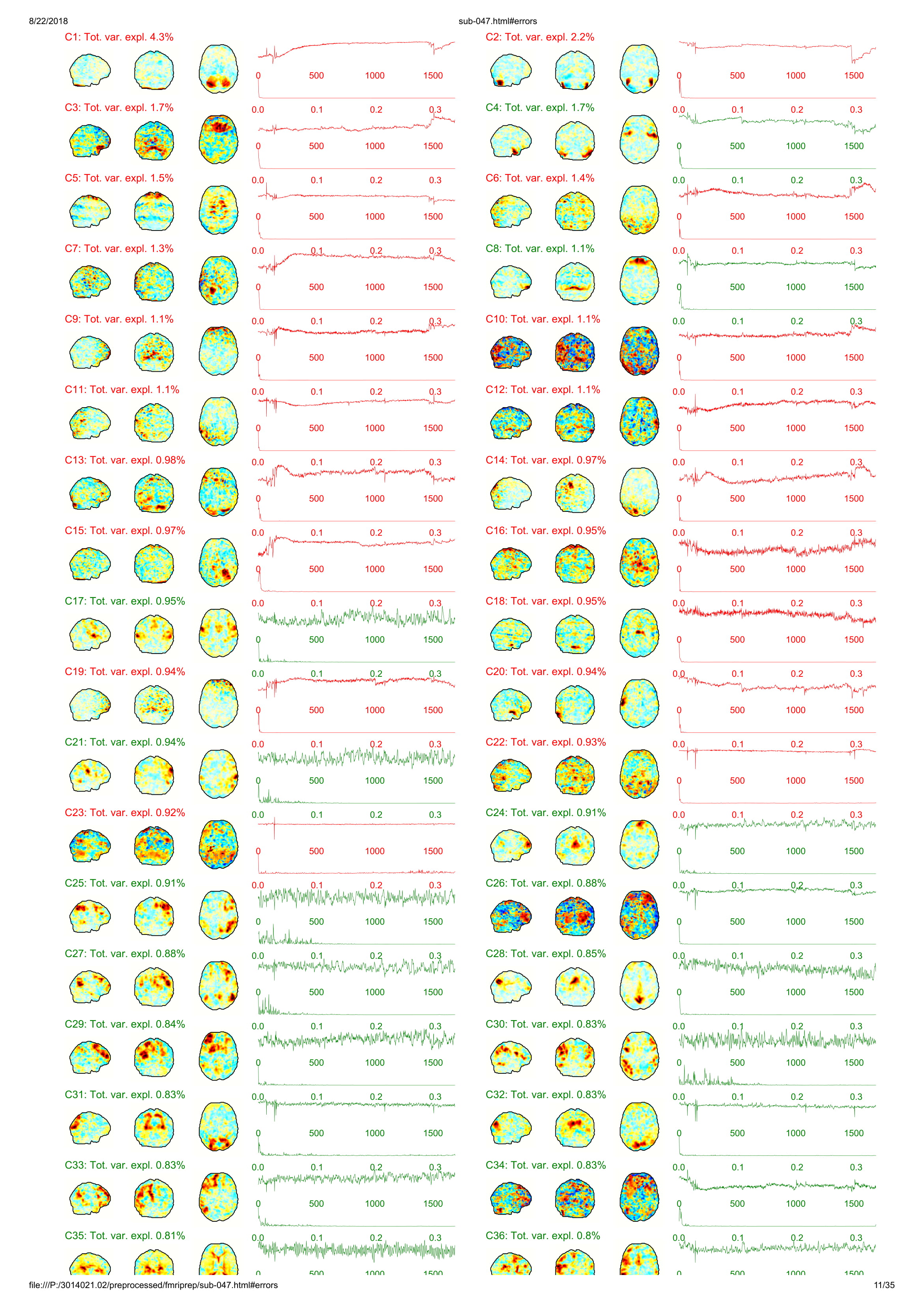
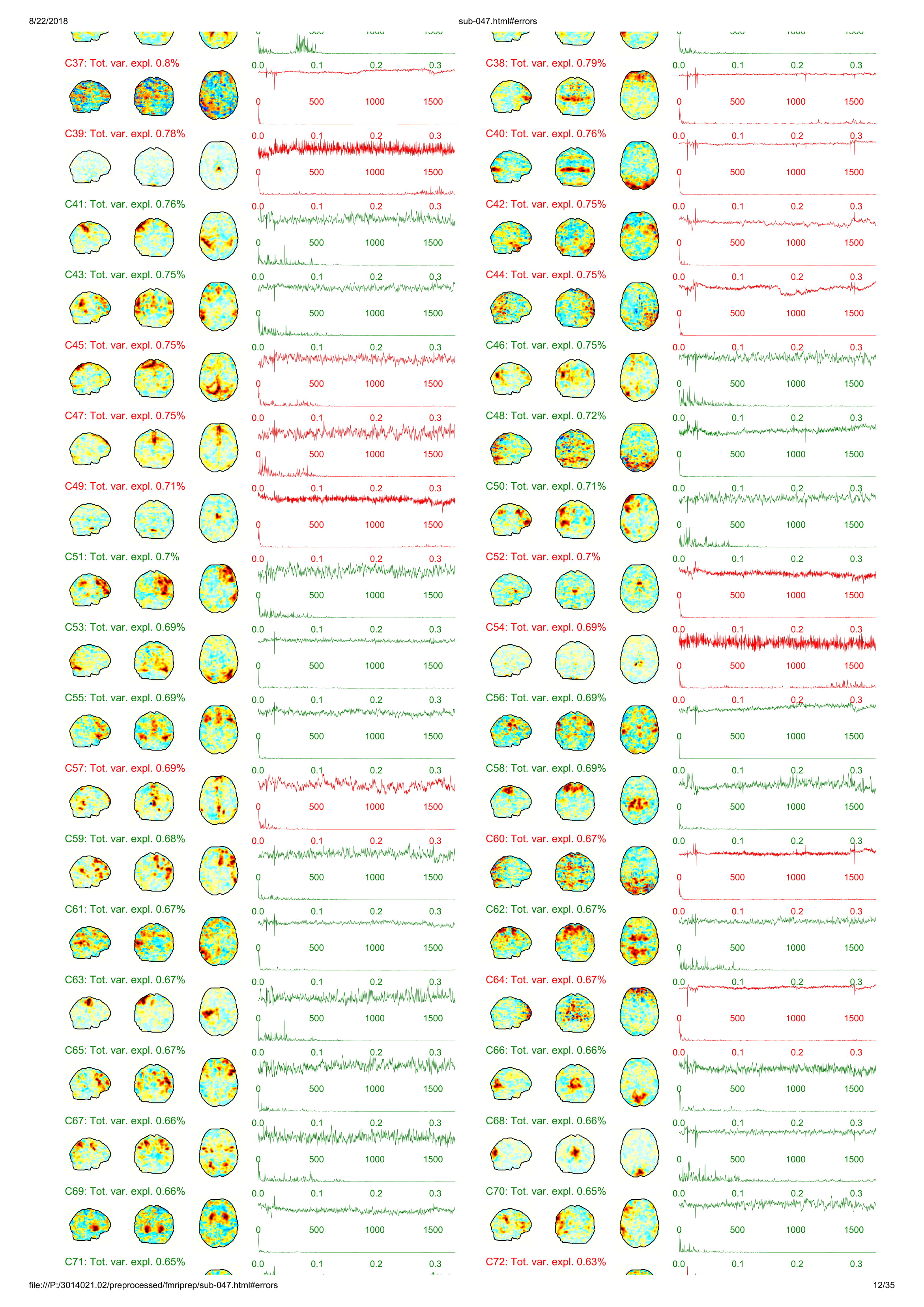
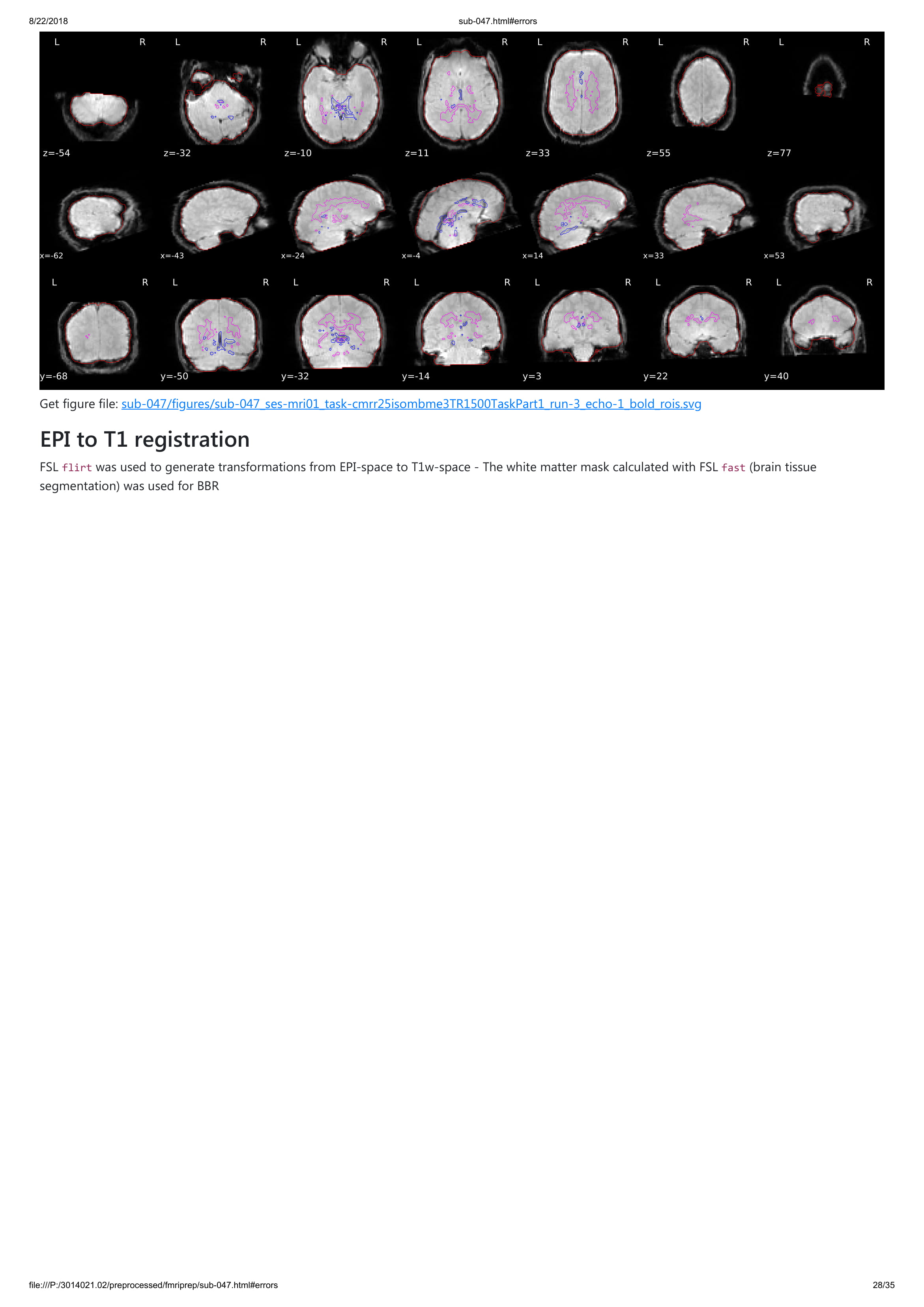
Until now all participants that I ran with fmriprep gave me an error with unwarping the fieldmaps that I collected. However, I do not understand this error. I added a pdf of one of the output participants. Any hint what is going on?
I noticed that the returned nifti files are 3x as large as I am used to. Is it possible this is due to some of the settings in the pipeline? Usually I run a basic preprocessing pipeline in SPM.
Thanks for your help!
Best
Inge
PS Apologies for the multiple jpgs, the output is large and the webside did not accept pdf. Suggestions to create one large jpg from pdf are welcome!
I think you want to use --t2-coreg, but I’ll pass the ball over @emdupre here to assist you :). She’s the expert.
I think it is not very clear that you can actually click on those errors and unfold the description of the problem. We will change that. For now, could you please unfold one of those and copy the text here? Thanks!
You are running ICA-AROMA, so your outputs will have a resolution of 2x2x2 mm3. I’d bet your original EPIs have a bit lower resolution and hence, the difference in size.
Thanks for your quick reply! Sorry, of course I tried to figure out the error message already, forgot to unfold, attached the jpgs with the error message. I hope it is more informative for you!
It does seem like I shouuld have used the t2-coreg option, I found this in the documentation
"If the --t2s-coreg command line argument is supplied with multi-echo BOLD data, a T2* map is generated. This T2* map is then used in place of the BOLD reference image to ref:register the BOLD series to the T1w image of the same subject <bold_reg>. "
However, it is not yet clear to me weather this command also combines the multiecho data. Plus, does this mean that without this command I did not properly preprocess my data so far? From the output I assumed the bold data was registered T1w and then normalized to MNI. Did I misinterpret?
You’re correct that --t2s-coreg would not combine the multiple echos. It’s another way to coregister the functional and anatomical data by first generating a T2* map and then coregistering the anatomical to that single image rather than to each of the echos separately. If you do decide to use --t2s-coreg, please report back !
The combination of echos into one usable timeseries (the so-called optimal combination) is instead handled by the tedana package, which is to-be-incorporated into fMRIPrep (but is not yet).
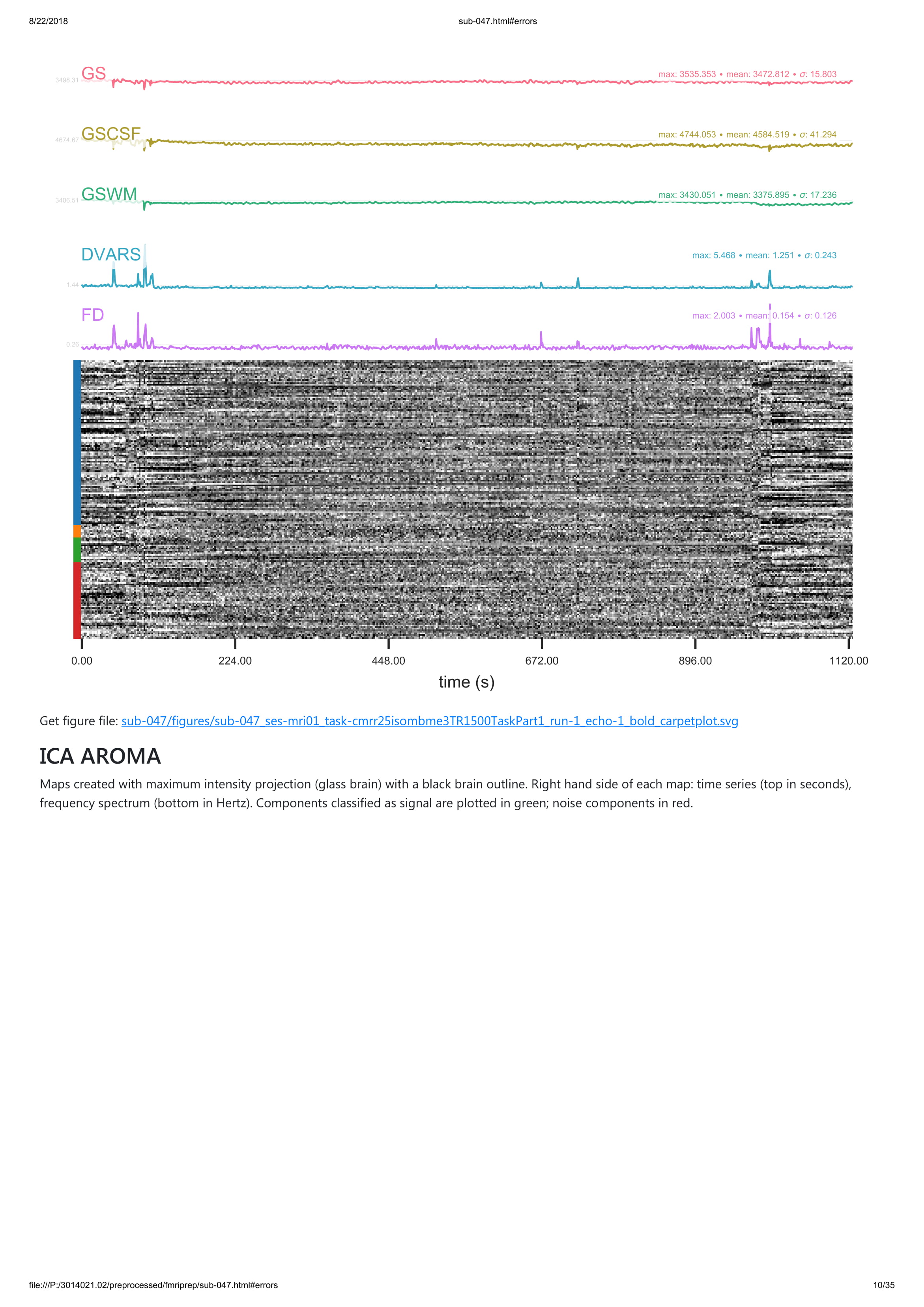
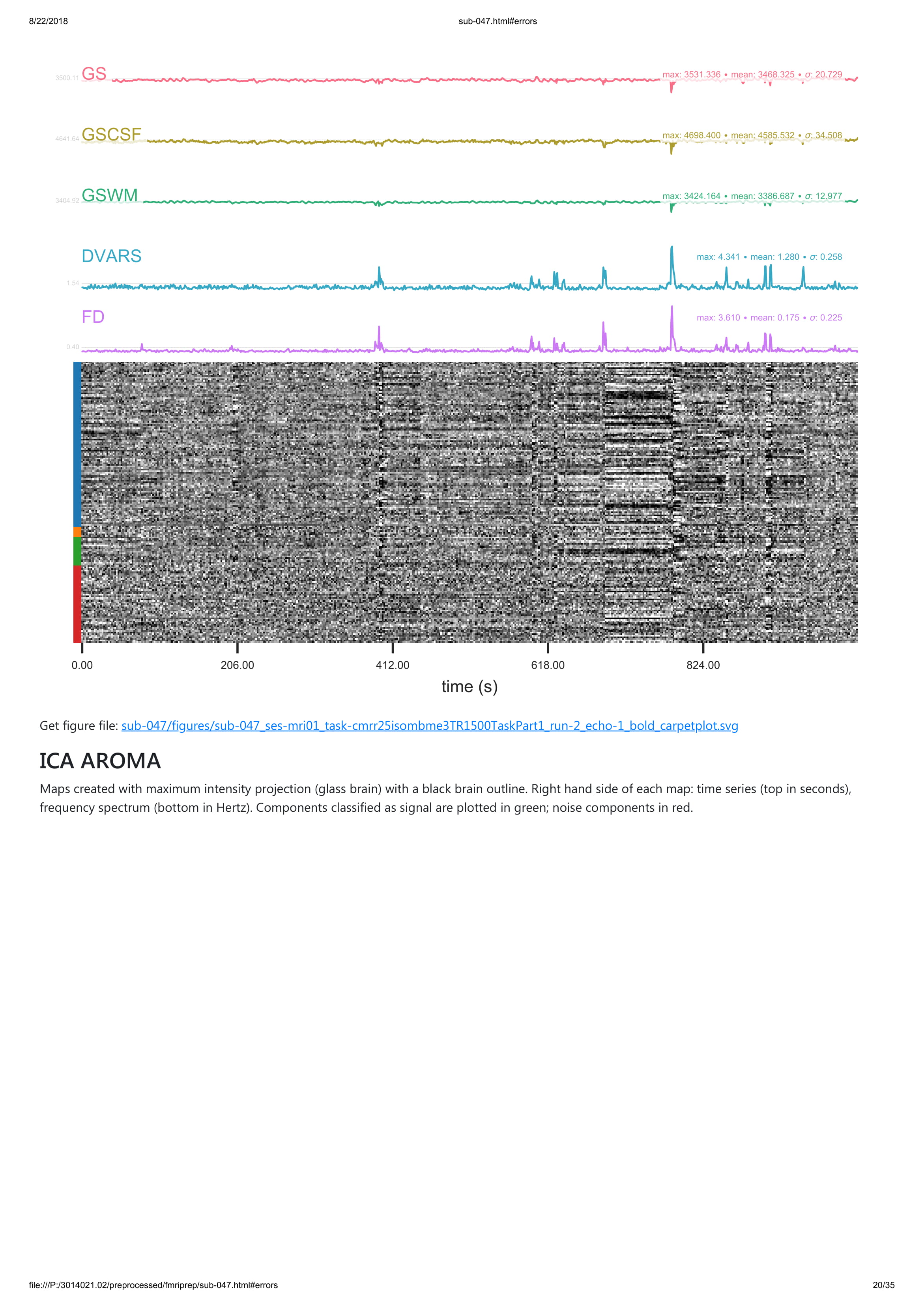
Looking at your attached reports, I’m assuming that you’re running ICA-AROMA on the individual echos-- we would not recommend this before combination, as at least with the optimal weighted average implemented in tedana it is unlikely to work.
I’m unsure if this will solve your space issue. Let me know if this clarifies things, though !
No, it doesn’t. I would really appreciate that you opened an issue in our repo requesting this feature.
No, there are some advantages in the T2* map contrast to perform a more accurate registration (especially for the longest echo that will have the lowest SNR). But it doesn’t mean that your preprocessing is wrong. @emdupre can really help you here
That is pretty accurate. Although information goes straight (without intermediate resampling into T1w space) from bold to MNI thanks to combining the mathematical mapping functions.
Finally, regarding those errors: could you share (maybe privately) a minimal example (1 participant?) for us to replicate the problem?
Of course, no problem if I share one participant. What is the easiest way for me to get the data to you? wetransfer? Plus, do you need any other information?
Edit,
I’ll open a issue to request this feature, just wondering. Where do i do this? github?
You’re correct that --t2s-coreg would not combine the multiple echos. It’s another way to coregister the functional and anatomical data by first generating a T2* map and then coregistering the anatomical to that single image rather than to each of the echos separately. If you do decide to use --t2s-coreg, please report back !
Sounds good! This is the strategy I used to do previously. Unfortunately it means I have to reprocess a lot of participants. I will use this strategy but it will take some time for me to report back.
The combination of echos into one usable timeseries (the so-called optimal combination) is instead handled by the tedana package, which is to-be-incorporated into fMRIPrep (but is not yet).
Looking at your attached reports, I’m assuming that you’re running ICA-AROMA on the individual echos-- we would not recommend this before combination, as at least with the optimal weighted average implemented in tedana it is unlikely to work.
What would the optimal strategy for me than be? Run fmriprep without ICA AROMA, combine the echo’s myself, then run fmriprep again with ICA AROMA?
I’m unsure if this will solve your space issue. Let me know if this clarifies things, though !
Google drive seemed the be easiest, please let me know if you somehow can’t access
This is a different participant than before, I removed sub-047 bids structure due to disk quota issues. This participant has the same jacobian error as sub-047, plus it generated an error with registration of one of the echo’s (not other runs & echo’s somehow). The output is in a pdf the same folder (remove for BIDS).
Previously, I used fMRI Prep v1.1.1 on ME-data (3-echoes) and got 3 separate preproc files representing each echo.
Currently, I am using fMRI prep v1.2.5 on a similar dataset, and I’m getting one preproc file. Does this file represent the optimally combined file (i.e., the tsoc file I would have got if I had used the meica.py pipeline)?
Also, should I be expecting a medn, mefc equivalent from fMRI Prep v1.2.5?