In data that was preprocessed using fmriprep 22.1.1 and then subsequently processed with univariate analyses using FSL, the group mask seems to be excluding large amounts of brain tissue. I confirmed that it was not one individual subject with poor registration that caused this. We also tried running the same data through a full FSL pipeline, and we got much better coverage of the brain; the final group-level effects from the FSL pipeline looked pretty similar, but weaker. This suggests to me that fmriprep is in fact doing a better job of cleaning the data, but it’s still concerning that we lose so much of the edges of the brain. Any ideas as to why this would be or how we could fix it?
Command used (and if a helper script was used, a link to the helper script or the command generated):
Data formatted according to a validatable standard? Please provide the output of the validator:
BIDS validation passed for each subject
Relevant log outputs (up to 20 lines):
Screenshots / relevant information:
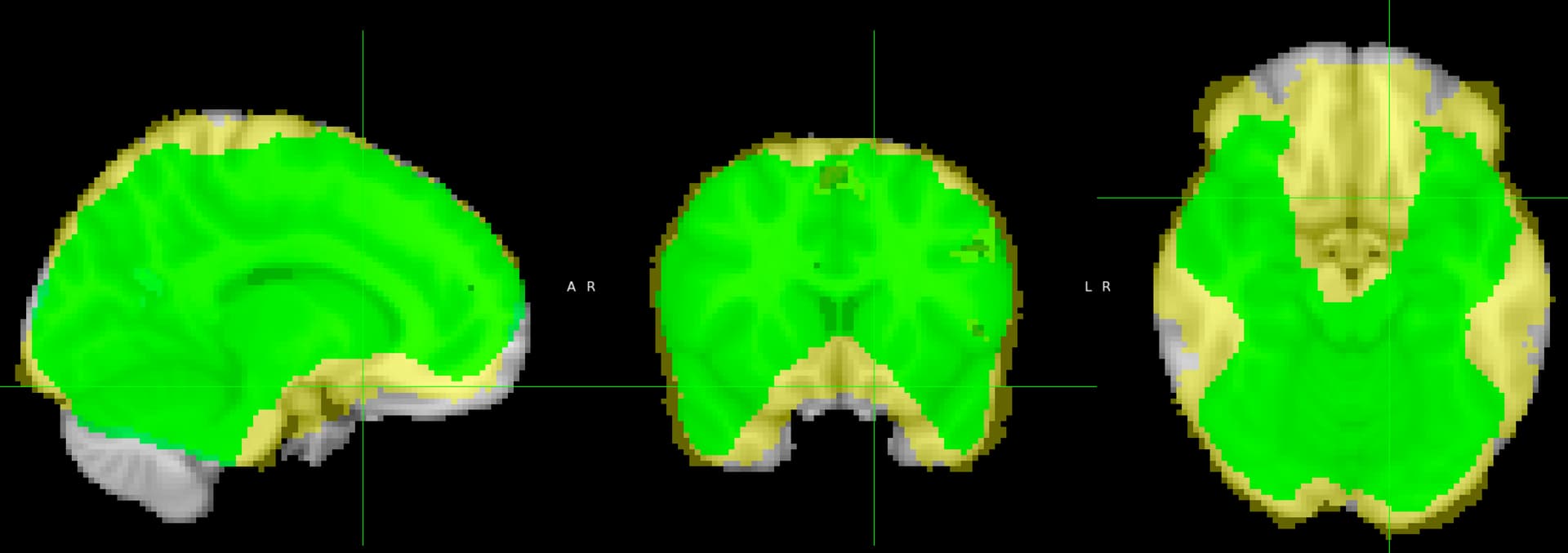
This screenshot demonstrates the issue. The yellow mask is using a full FSL pipeline, the green mask is when fmriprep was used for preprocessing. Activation clusters are visible underneath (yellow/light blue is a thresholded map from the fmriprep data, red/dark blue is the data from FSL without cluster correction).
I am going to guess this is due to different ways of dealing with signal dropout, and not skull stripping. Looking at individual brain masks of the T1s would be a good thing to check as a clue for skull stripping abnormalities. The functional brain masks are a product of both the skull stripping and signal dropout detections, so they are not as informative. As to what to do for analysis, does FSL allow you to use an explicitly defined brain mask, which you can define to be more inclusive? If you can use python, Nilearn would allow you to explicitly define a mask. You can also see if the most recent fmriprep version works better (23.1.4 at this time).
Just as a caution, depending on your stats, this could also just be an effect of more stringent multiple comparison correction on the larger FSL-pipeline mask.
Ah, you’re probably right that it’s based on signal dropout correction (which I assume comes from the field map?) rather than skull stripping. We’ll confirm that by looking at the T1 images.
If this is the case, then I’d still wonder if anything could be done about it, or if it’s fine to just ignore it (i.e., assume that the results that are showing up are solid, even if our whole-brain coverage is less complete than we intended).
I do see the following in the documentation for the fmriprep 23.1.x release: “Fieldmap handling is improved, with better preference given to single-band references in both PEPolar and SyN-SDC schemes.” We used a pepolar (blip-up/blip-down) field mapping approach. Can @effigies or any other fmriprep developers clarify if this is the kind of issue that was improved between v22.1.1 and v23.1.x? We can re-run fmriprep if needed, but I’d prefer to only do that if there’s actually reason to believe that a relevant improvement was made, since our cluster processor usage is metered, and re-running it on the entire dataset would be a lot.
As for the other things:
It should be possible to use a different mask with FSL using the same procedure that I used to manually copy the mask from fmriprep. If it were due to skull stripping, doing this would make sense. But if it’s due to distortion correction, then I would think we’d want to use a mask computed from data processed through the same pipeline as the functional analyses, wouldn’t we?
I also do agree that a smaller mask allows for more lenient multiple comparison correction, and that could be a small part of why we see stronger effects with the fmriprep pipeline. But I also found that when applying a voxel threshold (z > 3.1) to the unthresholded map from the full FSL pipeline, there are clusters in pretty much the same locations as in the analysis that started with fmriprep, but nearly all of the clusters are smaller and the statistical values at almost every voxel are weaker. I interpret this to mean that the differing results are not primarily due to more lenient cluster correction, but that instead, fmriprep is more successful than FSL at improving the signal to noise ratio of the data. This is why I’d prefer to use the fmriprep-ed dataset as our final version. But this mask issue was the one lingering concern before definitively settling on that…