I’m running fMRIPrep on some data and it fails pretty miserably. FSL, on the other hand, does a pretty fair job (all images are below).
To the details:
I’m preprocessing data the consists of T1, rest and task (few runs), where the rest and the task come from two very different scanning protocols.
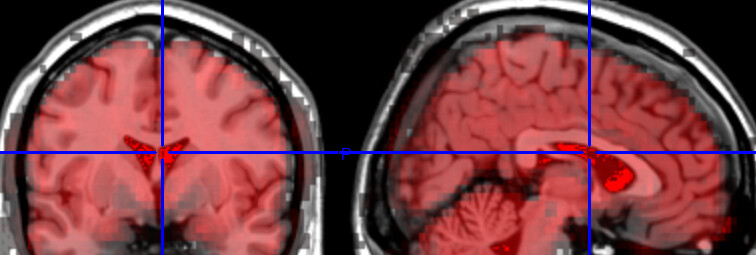
After running fmriprep, when presenting the average bold level (red) over MNI space, we get the following:
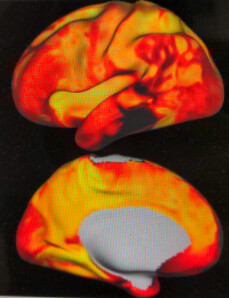
for task data, the registration looks not amazing but fair:
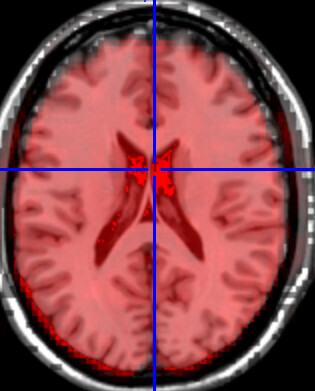
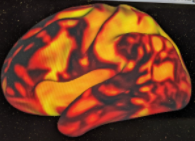
for the rest data, in the left hemisphere the registration is bad:
When registrating to the 32k_dense surface, its even more apparent - the black stains are VERY low values:
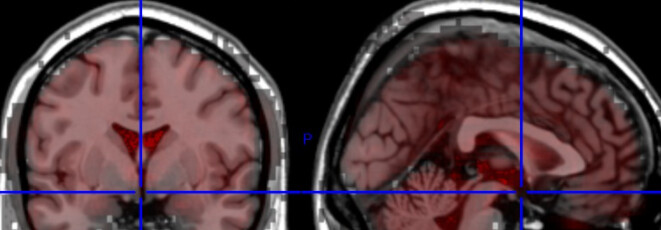
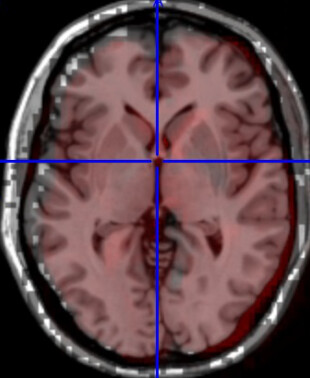
However, when using only FSL, we get -
which is by far better.
So, for whom got all the way here, I’m quite uncomfortable with the idea of taking it as simple as fmriprep doesn’t work, FSL does - and I would like to try to get some intuition as for why is it like this. But I need to know where is a plausible place to start.
If anyone can help me with that, it will be super!
if you are reusing any previously computer derivatives (like Freesurfer)
Also when you say:
What is the background image? It is worth noting that there are two widely used MNI152 spaces, one that is default for FSL (nlin6asym) and another default for fMRIprep (nlin9casym).
Maybe some screenshots from HTML output files might be valuable here.
Always worth trying to update to most recent version 21.0.0). Also, you’d want to make sure that you use different work directories between versions. The only thing you may want to reuse are Freesurfer derivatives (as long as it comes from Freesurfer 6 you should be fine).
The HTML has a field for spatial normalization where you can see how well the images conformed with whatever space you assign them to.
Finally I’ll note that aroma uses the FSL MNI space, while the non aroma outputs will use the Fmriprep MNI space (unless explicitly set different).
The normalisation looks ok, and it’s supported by the fact that the task registration (is this the term? i.e the application of the T1 normalisation results to the bold?) looks fine.
Is there a way to have a close look at the rest registration specifically?
The HTML report should have different sections for all BOLD runs with fmriprep outputs, so you should be able to see both your task and resting-state files, unless I misunderstood what you are asking for.
Sorry for the late reply, but thought you might be interested -
eventually, there were a few slices missing in the BOLD scans from the superior part of the brain - totally a known part of the scanning protocol. This made the BBR registration go bunkers, but the non-BBR dealt completely OK with it.
Now, for a reason I can’t tell (and won’t - I moved on), the auto-selection preferred the completely corrupted BBR coreg over the pretty-ok NoBBR coreg.
Having this noticed, I just used the --force-no-bbr option - but this definitely maybe something to address for whom looking for improvement in the package.