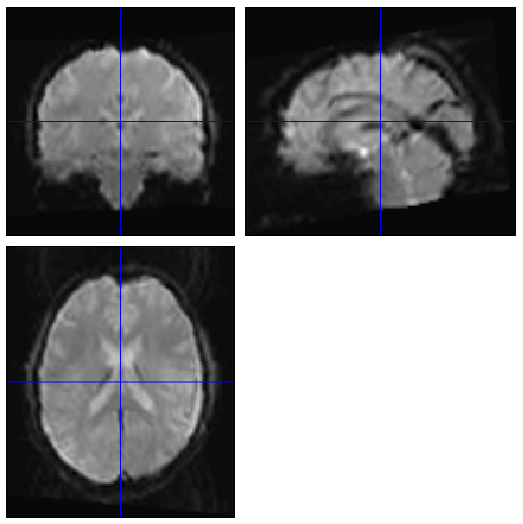
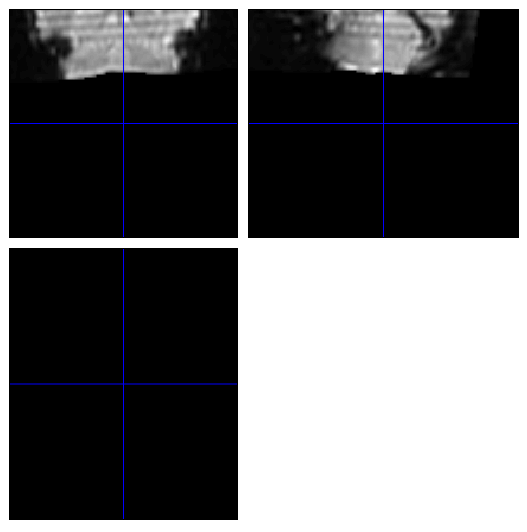
Apart from those two volumes, there are no issues with the raw functional data. Normalization warps the data-set starting at the problem volume (the prior volumes normalize fine) to the end of the run, causing it to look like the picture below.
I basically need to decide whether to cut the participant, cut out the problem volume and retry normalization, or see if there isn’t some fmriprep option I can tweak to fix this.
This is the code I used for the one participant (to re-check my original analysis). I was on fmriprep v1.4.1
fMRIPrep isn’t designed to handle such aberrant data, and there is no way to indicate that volumes should be excluded from motion correction. If you don’t need those volumes (e.g., they’re in dummy scans), then you can try truncating the dataset to exclude them.
Another option could be to motion correct the time series, and take the mean/median image of the motion corrected series. This volume could replace any missing scans. You will also want to add an indicator regressor to indicate that the volume should be excluded from analyses. For example:
This assumes that you’re censoring the first two volumes. There should be one row per TR.
Note that fMRIPrep does not need the censoring derivatives. This would just be how you would want to package your dataset so that somebody could interpret it.