But, I just want to make sure that I understood every steps 100%.
Here is the pipeline I studied. Please tell me if I misunderstood at some point.
Step1)
Anatomical preprocessing
Brain Extraction
Brain tissue segmentation(making brain mask)
Spatial nomalization(e.g MNI152LinAsym:res-2)
Step2)
BOLD preprocessing
HMC(We use reference BOLD image gained from t1-saturated image)
STC
SDC
resampling BOLDs into native spaces(This part was very tricky for me. I understood this process as followings. 1. combine each transform matrix into one transform matrix 2. apply one transform matrix onto each volume images)
EPI to T1w registration (re-align EPI images onto normalized t1w)
finally, normalize EPI images onto standard image.
Im pretty sure that I didn’t fully understand 100%, Any advice would be appreciated.
Your description is correct but keep in mind that fmriprep does and can do many additional steps depending on what the user ask for in the command line and also provides many useful outputs in addition to the preprocessed images, such as the confounds and the quality checks via the HTML page.
You get great details from the documentation: https://fmriprep.org/en/stable/outputs.html
Did you already preprocess your data with fmriprep or are planning on using it?
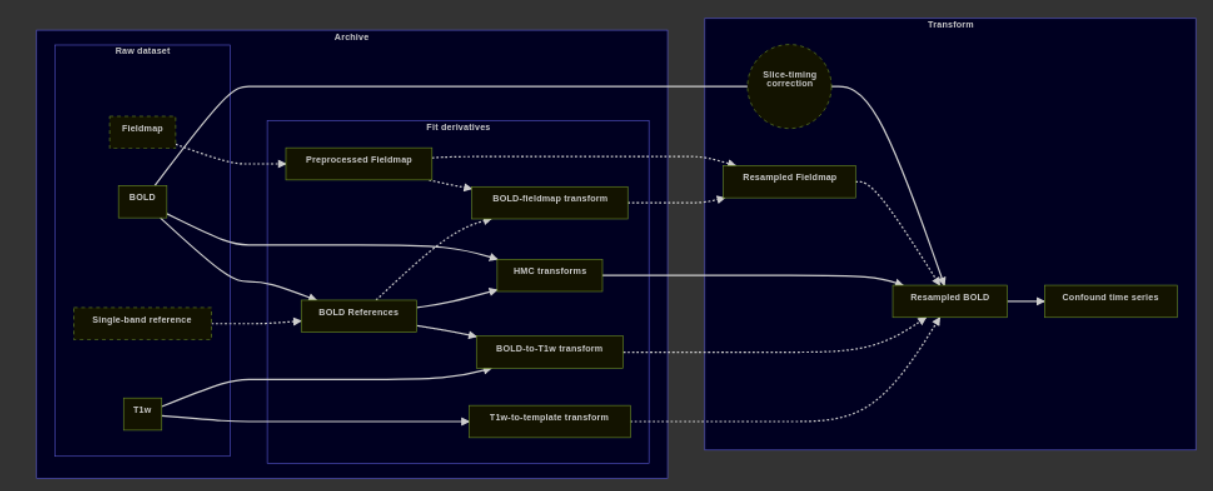
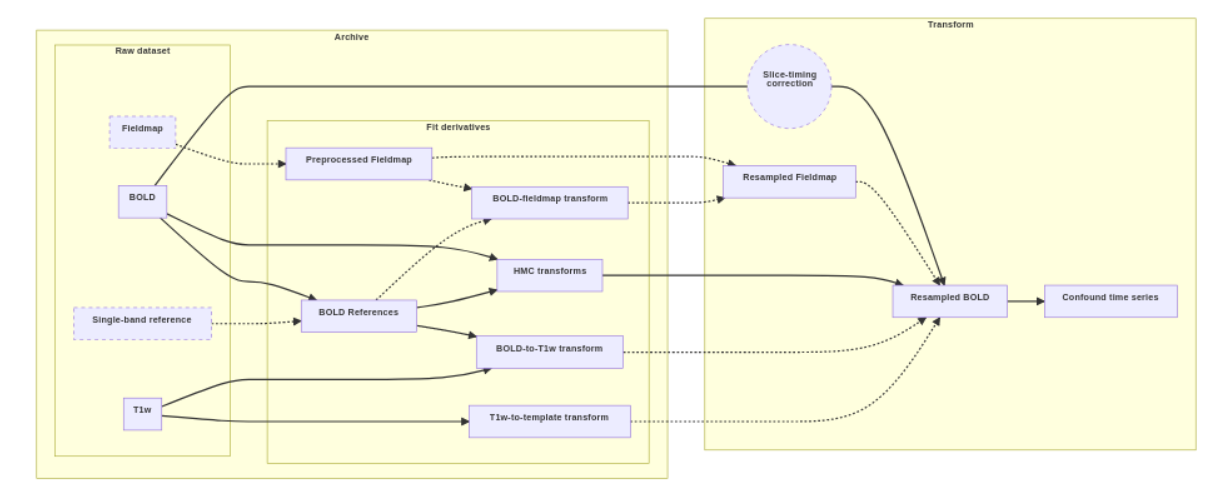
Dashes indicate optional data or processes. The “fit” derivatives include a collection of individual volumes and transform files. The “transform” section shows the process used to generate resampled BOLD series. The available inputs, such as fieldmaps and slice-timing metadata, and the target space, such as an MNI template, determine the final result.
One important point is that we try to resample as few times as possible. So while we do always resample to native (STC + HMC + SDC), that is used for processes that need data in native BOLD space. When we resample to T1w space, we apply (HMC + SDC + BOLD-to-T1w) in a single step from the STC’d (if applied) time series.