Hello, I am using for the first time a generalized Additive model (still trying to learn more about it) ,
My data are some skin conductance data recorded across 24 seconds (100 recordings per seconds I called them samples) in two different conditions (static or dynamic) . I set up the model with this command:
FullModel <-gam(SCL ~ s(Samples) + s(Samples, by = Condition), data = SCL )
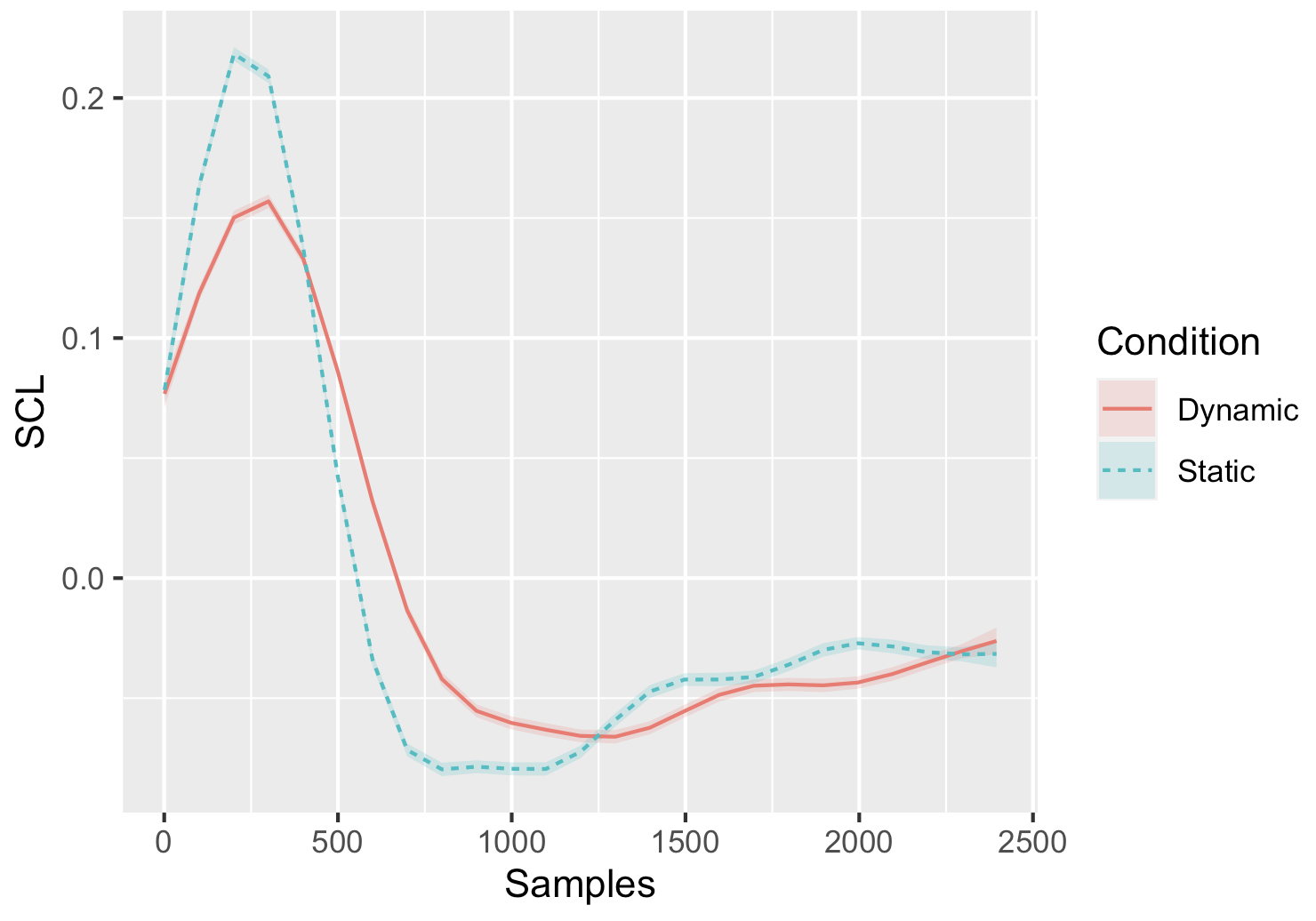
My question is when I’m trying to plot the model using plot(FullModel) vs. plot_smooths(model = FullModel, series = Samples, comparison = Condition)
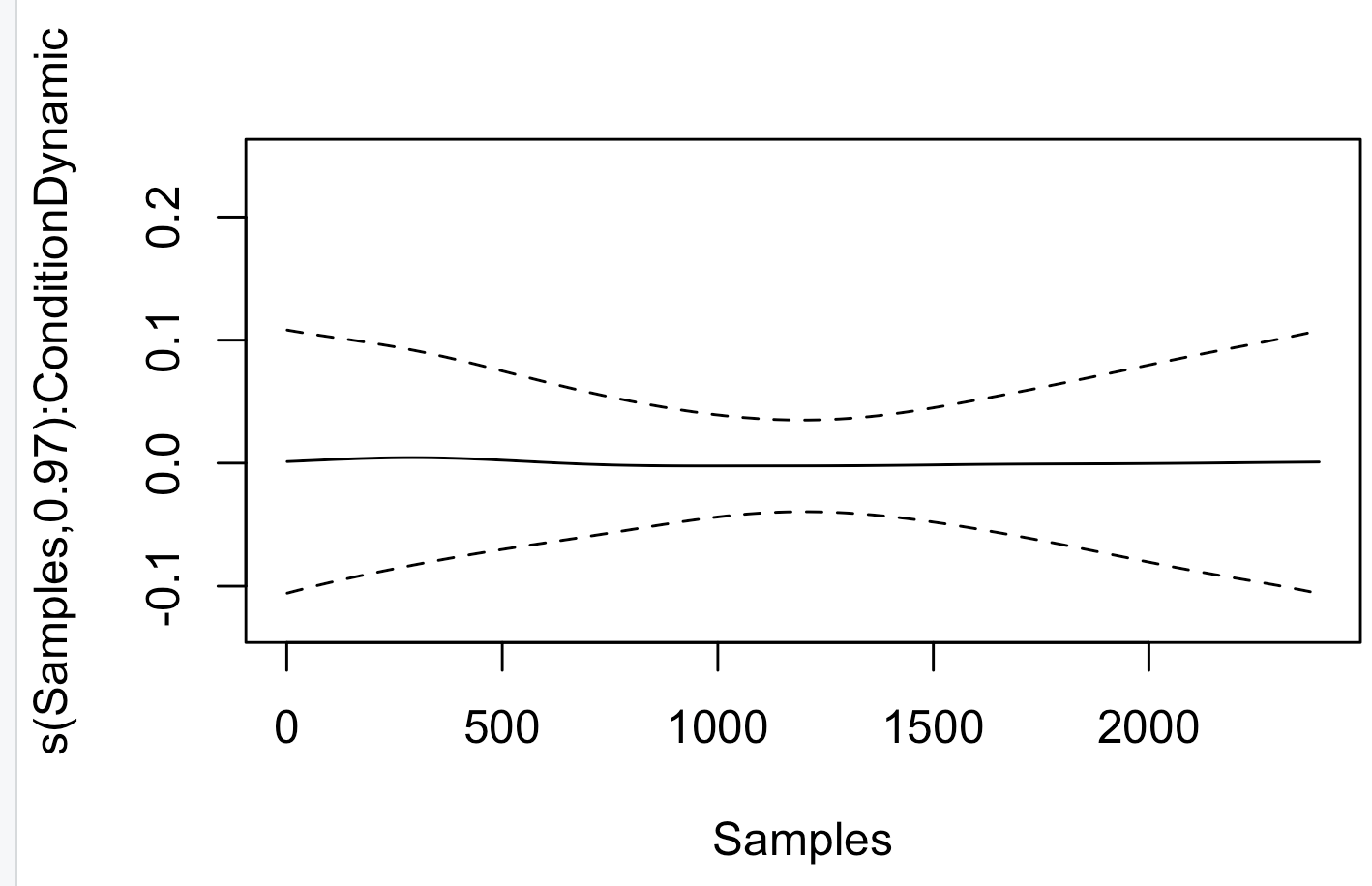
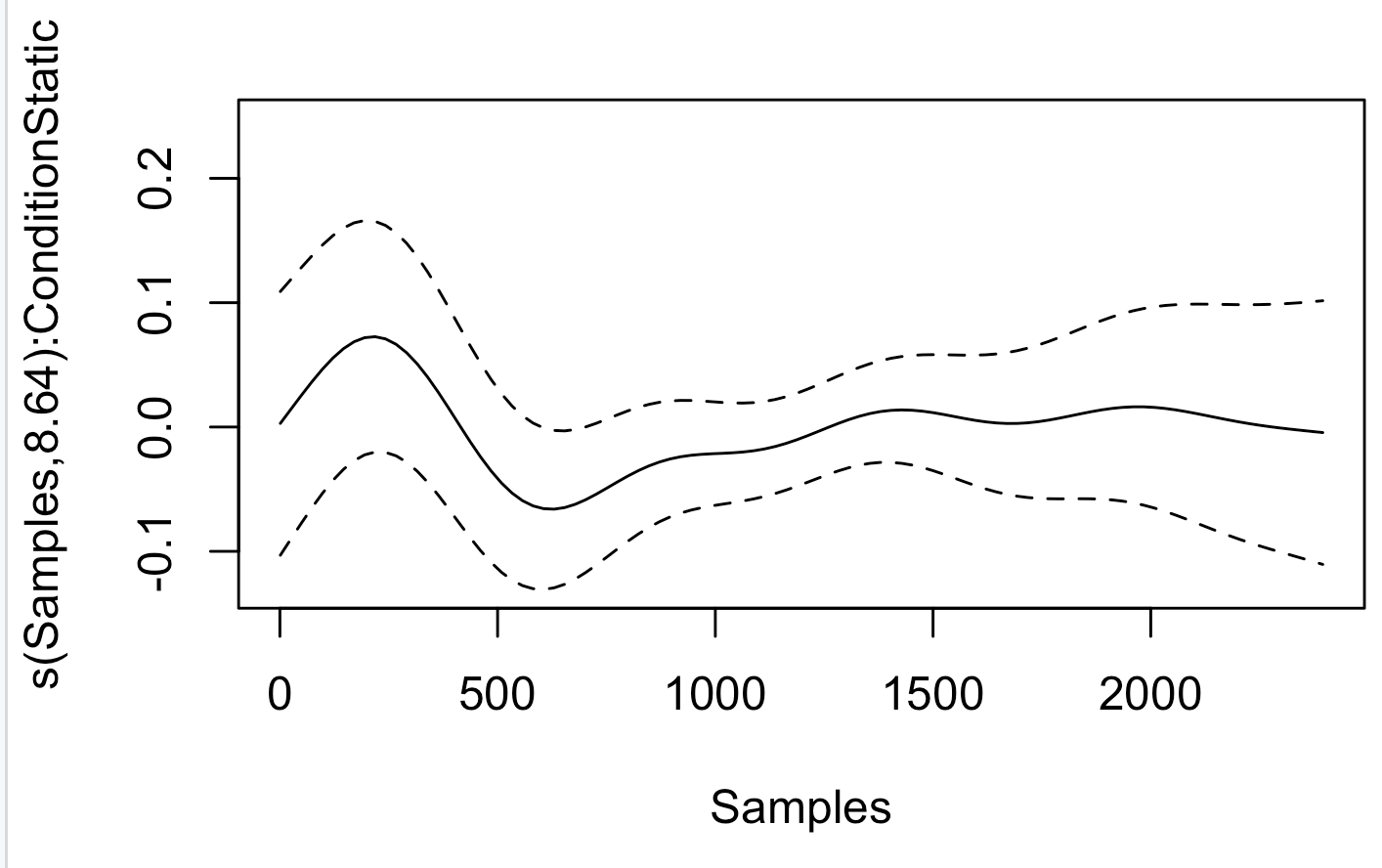
It gives me very different curves and I’m not sure I understand why; the first 2 are from the plot(FullModel)
The key difference between the two methods you mentioned—plot(FullModel) and plot_smooths()—lies in what they aim to visualize.
1. plot(FullModel)
This function is part of the base GAM implementation and shows partial effects of the smooth terms in the model.
For your model, it would display:
The smooth effect of s(Samples) (the main effect of Samples across all conditions).
The smooth effect of s(Samples, by = Condition) (the interaction of Samples and Condition).
The y-axis for each plot shows the partial contribution of the respective term to the response (SCL) after accounting for the other terms. These are not directly the predicted SCL values but rather components of the model.
2. plot_smooths()
This function (likely from the itsadug or gratia package) shows the predicted values from the model, considering the combined effects of all terms.
When you use comparison = Condition, it plots the smooth effects of Samples for each level of Condition, reflecting how Samples interacts with Condition in the model.
The y-axis here represents the predicted SCL values, which include contributions from all terms in the model.
Why Are the Curves Different?
The curves differ because they represent different aspects of the model:
plot(FullModel) isolates the effect of individual smooth terms without accounting for their combination.
plot_smooths() integrates the contributions of all terms to show the full predicted response (SCL).
Recommendations
Use plot(FullModel) to inspect the contribution of each smooth term and diagnose the model.
Use plot_smooths() for a clearer view of the predicted values and how Samples interacts with Condition.
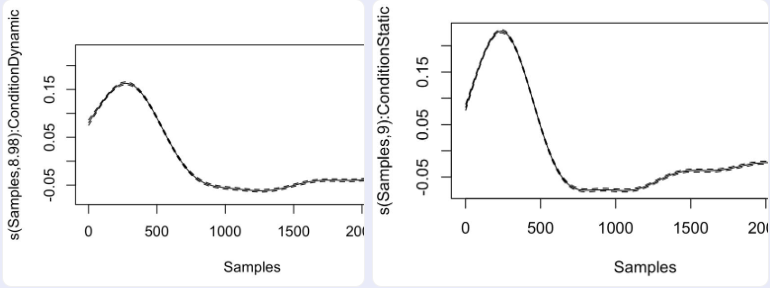
I think your model is overparameterized; you’re fitting three spline effects here, one for “Samples”, one for “Samples in Condition=Dynamic”, and one for “Sample in Condition=Static”. Your second plot is showing something like the effect of “Sample in Condition=Static”. Your first plot is showing something like “Sample in Condition=Dynamic”; it’s essentially flat because all of the variability across Samples is loading on to the third spline (the one created with s(Samples)) The call plot(FullModel) produced a third plot didn’t it? I’m guessing that third plot will better represent the effect of condition=Dynamic across Samples.
Do things seem more reasonable when working with the following model?
FullModel <- gam(SCL ~ s(Samples, by = Condition), data = SCL )
In general, it’s often a good idea to mess around with fake data when functions are confusing. For example
set.seed(0)
library(dplyr)
library(tidyr)
library(ggplot2)
library(mgcv)
d <- tibble(x=seq(0, 5, length.out=1000)) |>
crossing(condition = 1:2) |>
mutate(
y = if_else(condition==1, dgamma(x, 2, 3), dgamma(x, 4, 6)),
y = y+rnorm(n(), sd = 0.1),
condition = factor(condition))
d |>
ggplot(aes(x=x, y=y, color=condition)) +
geom_line()
overparameterized <- gam(y ~ s(x) + s(x, by = condition), data = d )
plot(overparameterized)
fit <- gam(y ~ s(x, by = condition), data = d )
plot(fit)
Thank you so much for your response!
I tried to run the model you suggested , and I get 2 significant results this time so I guess you were right : I thought it would be like a GLM where you need to set the main effect and the interaction.
Oh i see with your fake data it reproduces exactly my data. Ok so definitely changes a lot!! Thank you for the hint. One last question if you don’t mind … this models tells me that both static and dynamic leads to non linear relationship with samples. but what would be the way to decompose this and show for example that during the first 500samples one is stronger than the other ; is it back to just some basic t-tests?
I’m not very acquainted with the statistics of generalized additive models, so I can’t answer that second question with any confidence. But I have found Gavin Simpson’s blog very informative, and I see that there are a pair of posts describing two methods for comparing splines across factor levels:
As I understand, what you describe is basically accurate, but there’s some finesse needed to account for the uncertainty in the estimated splines. It looks like you have quite a lot of data leading to precisely estimated splines, and so a difference between the two curves in the region you describe sounds plausible.