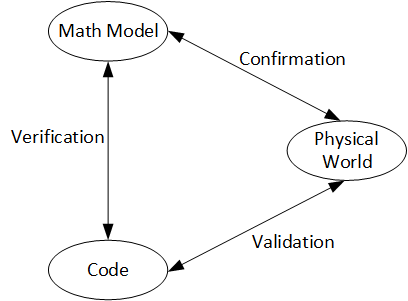
Quantitative analysis and thinking are essential in the scientific process. Models are computer implementation of mathematical system of equations built on one or more hypothesis. Scientific method requires testing the model against experimental observations: this is model validation - the term verification will be used to encompass software validation.
The project revolves around CerebUnit: a SciUnit based validation module suite that deals with models of the cerebellum - the part of the brain below the cerebrum (larger) and behind the brainstem. Validation tests compares the model prediction against experimental data. The model is then analyzed based on the results. To avoid getting overawed by the mystique of objectivity emanating from the numerical figures one should ask “How dependable is the test?”
The project will involve adding features in CerebUnit (CerebStats) that will try to address the question. In particular, - ability to return the probability of type-I or type-II error for a validation test that has undergone hypothesis testing
which error type probability is returned will depend on the user’s requirement
– return type-I error probability for false positive
– return type-II error probability for false negative
ability to get measures of performance of a given validation test
– sensitivity (true positive rate)
– specificity (true negative rate)
– prevalence
– positive predictive value
– negative predictive value
Skills: Python, statistics (basic principles of statistical testing)
@malin I would like to show my interest for working on this project. Please let me know the further steps for better understanding of the project. I would also request you to help me connect with potential mentors
Hi Harsh, I’ll tag the mentors, @apdavison and @lungsi for you, if they don’t reply within 1-2 days, please ping me here or email malin@incf.org. Welcome!
Thank you for the interest. The main aim of the project is to implement an approach to quantify the quality of validation tests (current and upcoming) of cerebellar models; Validation tests compares model outputs against experimental data as opposed to software verification.
The target for this project is the CerebUnithttps://github.com/cerebunit ecosystem: a gateway to libraries for cerebellum validation, written in Python. CerebUnit comprises
cerebmodelshttps://github.com/cerebunit/cerebmodels, cerebellum models for validations comes from here,
cerebdatahttps://github.com/cerebunit/cerebdata, experimental data for validations,
cerebtestshttps://github.com/cerebunit/cerebtests, the validation test definitions, and
cerebstatshttps://github.com/cerebunit/cerebstats, the statistical functions called by the validation tests*.
The objective for this project would be to add the functionalities for quantifying the test quality in the cerebstatshttps://github.com/cerebunit/cerebstats sub-module. Specifically the functions
The idea is to add a new directory say test_quality (for lack of a better term for now) that would contain the source codes for the aforementioned functions.
Hello! I am very interested in this project in that the project deals with unusual data to model of the cerebellum. Also, I’ve been wanting to research our brain in any way. I’ve been majoring statistics at UCLA , trying to deal with as many data as I can in order to model and find informative parametrics. I hope to know how the way of making the proposal would make getting the chance to participate in this project more likely!
Thank you @Sungho for your interest in this project idea. Your background in statistics will be quite useful.
However, I would like to make it clear that although validation is central, the project does not strictly deal with validation itself or modeling. The objective of the project is to quantify or some measure of quality of any validation test.
Consider the case of some test that claims to have 100% sensitivity and 90% specificity. 9% is the prevalence. What can one learn from this? Is this a good test?
One may attempt to answer this by constructing the table from the given information
Negatives
Positives
false negative (FN), 0
true positive (TP), 9
true negative (TN), 81.9
false positive (FP), 9.1
There are therefore 18.1 positives out of 100 and the positive predictive value is 49.7%.
The moral is that a test with high specificity does not guarantee high positive predictive value.
I would also add that the models here are already developed. The data taken from experiments (mostly publications) are used for validating them. Because using data to build model will be along the task of confirmation and verification. Below shows the synthetic ground for model synthesis and its validation.
In case you have not noticed validation plays a pivotal role in the scientific method.
Yes I received your email. You appear to have had a good amount of experience in Development projects. Although this project idea does not involve AI your development experience will help. An obvious one will be familiarity with version control, presuming you have used Git.
Depending on what you did as a research student that work experience may have immediate application to this project.
No, not from me. Are you considering creating a mock working example for your project proposal? If so, do you think you can get one done in 4 weeks? If not, my suggestion would be for you to write a good proposal or improve one if you already started writing.
@lungsi Thanks! I will start writing out the proposal and would share the doc link with you having access to view and comment to plan the milestone across the time for better execution of the project. Does it sound good to you?
Actually having thought about this point there are tasks requiring porting some models in cerebellum - models that are already built but not yet functional for validation (i.e., CerebUnit), it may lack a Python interface or in some cases the model codes are not in Python. The “new” model can then be put through the validation test (a task that will involve you to know the experimental data) and then measure the quality of the test.
It does not have to be exactly like above but its an idea. I thought of mentioning this based on your conveyed interest.
@lungsi As I am writing out the draft proposal, There is one little confusion on my end. It would be better if you can address that.
Do I need to implement the functions referenced here cerebstats documentation?
Or Do I need to implement the functions to test/quantify the functions referenced in the link?
I will share the link with you soon as I am ready with initial draft proposal for feedback.
As what I can see at Cerebstats Github repo, It seems functions are already implemented.
So, I need to implement testing functions for testing metrics like true positives, false positives, true negatives, false negatives, prevalence, sensitivity , specificity. Right?
Yes but let me highlight some points so that you can better understand the problem addressed at the start of this thread.
Remember that what is posted at the top of this thread is a project idea. The key word here is idea. It is up to you to propose a work that would complement the idea.
Also note that it says
There is a reason why the word ability was chosen. From your Stat-101 class you may have learned that type-I error probability is actually the level of significance (alpha-level). However, getting the value of the type-I error probability is trickier, which as you know is β = 1 − power. Figuring out a number that closely relate to power is the trick. And with regards to the rest - sensitivity, specificity, etc. - one needs to run the test on multiple cases to get their values.
What all these suggests is that while getting the actual measured value for quality of the validation test may depend on the conditions - availability of tests, data and so on - the ability to measure must exist in the first place.
Therefore,
No. At its current state none of the said abilities exists.
Here’s a general recommendation to anybody considering writing a proposal on this idea.
A model - simply put it is a software codified version of what is often a system of mathematical expressions that were derived from experimental observation, in other words, a theory - is as good as its prediction (this differentiates it from curve fits). The “goodness” of the predictions will depend on how it compares against physical experiments. Let us say this process is performed by the validation test - note that the word “test” is fairly generic so “validation” qualifies it and hence differentiating from verification test, software test, and so on. Validation is a crucial step in the scientific method.
Presuming we trust the experiment and the model, the next question is “What about the validation test?” The project idea deals with this problem. I suggest you put some thought to this problem. Also, depending on your backgrounds in elementary statistics try to grasp at least the big picture concepts of the statistical terms mentioned in the project idea.
Do not parrot your proposal by copy-pasting the above idea. Think about the problem and then you will soon be able to zone in on a specific problem (within the larger problem) for yourself - this will also indicate to your proposal readers that you understand the problem you plan on tackling. You will not only have a better proposal but if it gets accepted your execution will go much smoother. For those of you coming from predominantly programming experience, this exercise may be familiar because in certain circles it is part of the Domain-driven design
@lungsi I completely agree on your stance with having better understanding of project which makes the execution of it very smooth.
When I said that functions are already implemented, I referred to three directory inside the Github Repo which consists of the functions referenced here cerebstats documentation
Now for this, I do understand some part of it. Other things I will try to refer from online resources. Also, if you do have something in mind which you feel might be helpful on this. Please do let me know, I would be very happy to receive your suggestions.
I found these above resources very useful in understanding specifically ‘Type 1 and Type 2 error’.
Please do inform me if that’s not what is used in this context! Thanks!