BIDS (Brain Imaging Data Structure; BIDS | INCF - International Neuroinformatics Coordinating Facility) is a standard for organising neuroimaging and behavioural raw data. It enables interoperability by allowing multiple tools to analyse a given dataset without extra modifications, and reproducibility, by facilitating reanalysis of the same dataset by multiple research groups. Although originally developed for MRI data analysis, BIDS has also gained popularity for EEG/MEG data analysis, and with more analysis tools supporting BIDS, converting raw data to the BIDS standard has become an important first-step for EEG/MEG data analysis. Unfortunately, however, available tools are often too complicated to use for scientists with limited technical or scripting experience, a situation that is especially prevalent in EEG labs which are less likely to employ informatics support personnel.
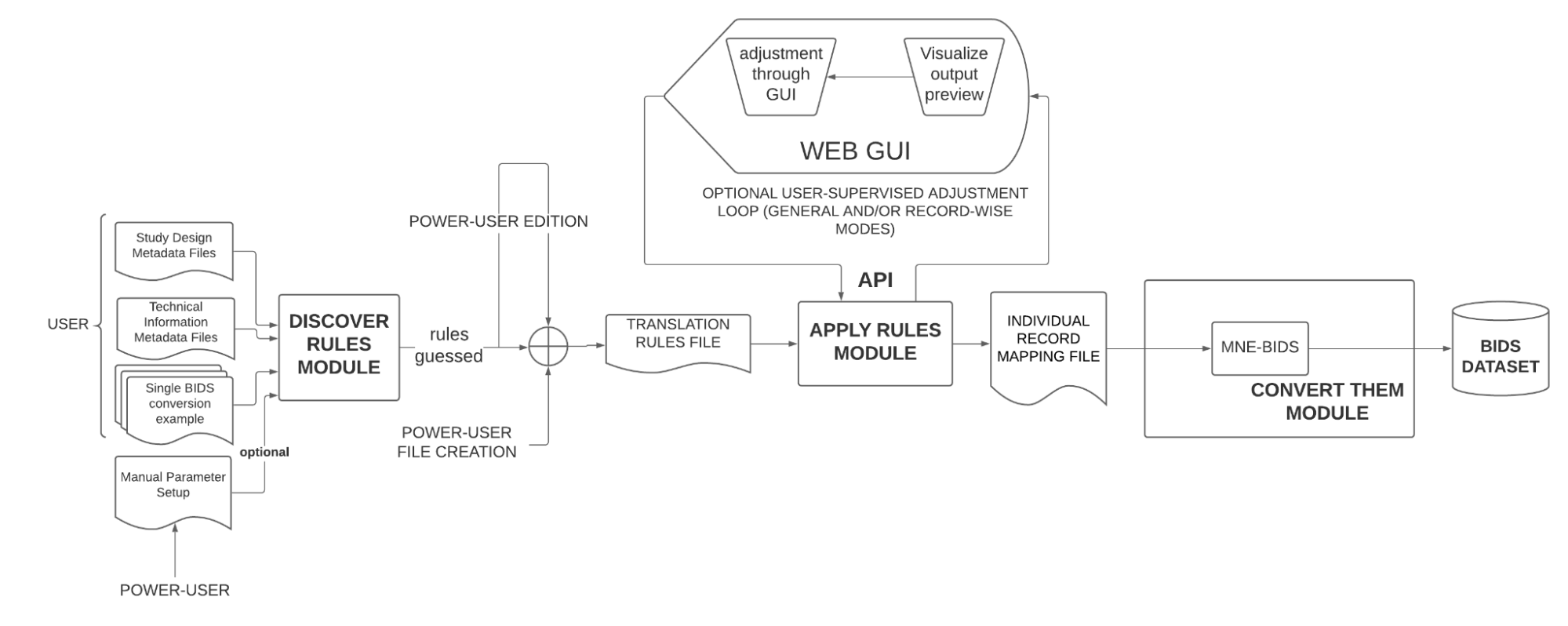
One major barrier to user-friendly conversion of data to the BIDS standard is that most tools do not include a graphical interface. Moreover, the few general-purpose BIDS conversion tools that do have a GUI in addition to a command line interface, do not support conversion of EEG/MEG data. The proposed project aims to extend one of these existing BIDS conversion tools to add EEG/MEG support, resulting in a tool that is both easy to use, and as general as possible.
The converter will be cross-platform (Windows, Mac, Linux) for maximum applicability allowing a wide reach of EEG/MEG labs and users. Moreover, it will be integrated into AEDAPT/NeuroDesk (GitHub - NeuroDesk/neurodesk: A flexible, scalable, and easy to use data analysis environment for reproducible neuroimaging), a Docker virtual machine incorporating a complete EEG/MEG (as well as MRI) analysis desktop environment. AEDAPT/NeuroDesk is an open-source project supported by the Australian Research Data Commons and actively developed by several universities in Australia.
Incorporating continuous integration to ensure backward compatibility
Enhancing the tool so users can enter additional information, not recorded in the original EEG/MEG raw data files
Redesigning the tool to allow either bulk or incremental conversion
Improving support for multiple-session acquisitions of the same individual
Adding automatic suggestions based on mappings provided by the community
Skill level needed:
Python GUI programming - intermediate
Text manipulation (regular expressions) in Python - intermediate
Familiarity with EEG - advantage
Familiarity with BIDS - advantage
Tech keywords:
Python
PyQt5, Tkinter, or wxPython
JSON
Circleci or Github actions
YAML
Mentors: Oren Civier @oren_civier (Swinburne University of Technology), Steffen Bollmann (University of Queensland), Aswin Narayanan (University of Queensland), Tom Johnstone @TomJ (Swinburne University of Technology)
My name is Yorguin Mantilla (github). I’m from Colombia and currently I’m studying Electronic Engineering at the University of Antioquia. I have a partner called Brayan Hoyos. We both have been working with a local university group called GRUNECO (Neuropsychology and Behavior Group) in a project similar (in requirements) to this one.
Basically we developed an app that would read EEG files from a bids-like directory tree, apply some preprocessing routines and make transversal, longitudinal, and mixed (ANOVA) analyses of the subjects (with optional html reports). The app itself is made in PyQt5 following a Model View Controller architecture. Moreover we implemented a mongodb database mimicking BIDS to be able to query the subjects (although PyBIDS could have done it, we just wanted to learn mongodb).
We also recently made an app that would take a flat directory with eeg files (with some naming convention) and with interfaces try to generate a valid BIDS dataset using the MNE library. This was for a talk in our university group regarding finally adopting the BIDS standard. We did a local implementation for the conversion but we know that mne-bids could have done the job if we had inspected it more closely.
If any of you is interested in seeing any of the apps I guess we could set up a meet.
Now, my partner doesn’t really speak English so basically we agreed on me postulating here. I’m interested in developing this project and very much wish that the result is general enough for it not to depend on Neurodesk. I was wondering if that was a problem.
I’m not really experienced in circleci nor github actions though I have contributed to a repository (pyprep) that implements the later but I have myself never configured that part.
I have only used Docker one time by testing fmriprep and mriqc. So being on the developer side of that technology will be another challenge.
Finally, I gave a quick (shallow) reading of the neurodesk repository but I didn’t find what package will be used to read the EEG files (did see SPM12 in the apps.json file but I guess thats in another context??). ¿Would it be ok to approach this project from an MNE-python side?
Thanks so much for contacting us. We are very excited. It definitely seems like a match made in heaven, so we are looking forward to seeing what you’ve already developed and how we can leverage it to our proposed project.
There are two existing projects that we considered as a basis for our work are BIDScoin (GitHub - Donders-Institute/bidscoin: BIDScoin converts your source-level neuroimaging data to BIDS), which currently focuses on MRI, and Biscuit (Biscuit), which focuses on MEG only. I encourage you to look into these solutions, and let us know how your approach is better/worse, and how you suggest to use the best of all worlds (keeping in mind the points that we listed in the “scope” section of our proposal). Then, we can organise a meeting and discuss.
Could I just ask if you intend to participate in GSoC? or rather, would like to contribute to our project regardless? We are open to all possibilities.
With regard to your questions:
neurodesk is just an environment to make the tool easier to access, but the tool does not need to depend on it. In fact, we want it to be independent.
docker is not required for this project. To include the tool in Neurodesk, we will probably pack it within a Singularity container, but you don’t need to worry about it.
MNE python is perfect
Looking forward to hearing from you,
Oren and the team
P.S.
Just a few words in Spanish:
Muy lindo encontrar gente de Colombia. Como mi esposa es de Argentina, hablo espanol (no perfecto, pero hablo) y asi sera facil para mi comunicar tambien con Brayan. La verdad es que viajaba y vivia mucho en America del Sur, pero lastimamente, nunca llegue a Colombia. Espero hacerlo un dia.
Sorry for the late reply, I have been a bit busy these days. Both Brayan and I are really happy for the heartfelt reply. Now to answer your questions:
Yes, I intent to participate GSoC. This week I was talking to my mentors here at GRUNECO of what they think about me participating in GSoC, they are all supportive.
GRUNECO (Neuropsychology and Behavior Group) is a multidisciplinary group focused on the advancement of neuropsychology. As of now it has people from medicine, psychology and engineering; currently it is taking its first steps in software engineering. It is also trying to get more international visualization. Given this I was wondering that if the software was successfully done, would there be any problem in mentioning the support of GRUNECO much like the Macquarie University’s support is shown in the Biscuits page and along with the other universities of course.
We are currently inspecting Biscuits and BIDScoin source code to get more familiarized with it. At the moment we were able to pinpoint some comments:
Biscuit’s requirements mostly use the “>=” constraint but some of the packages broke a bit of the functionality as they got updated so for the end user maybe it is better to use the “==” constraint.
Biscuit as a whole is more profesional than what we did in our experiments, so we do recognize that we are still learning…
We have almost no experience with MEG data so a lot of idiosyncrasies are not known by us. Mostly we have dealt with EEG.
We are lost regarding the understanding of Biscuit’s architecture. We have mostly tried to implement MVC architectures in pyQt so we were trying to find those patterns. For example the Managers seem to be the controllers, and the windows are pretty much obvious. I have seen code that seem that could be part of the model but it is mixed with the View so it confuses us a bit. Now, this could be because our inexperience and because… well its hard to understand someone else’s code. Requires a period of assimilation so to speak.
In Biscuit (or at least in what we could test of it) we saw that the general workflow is to go file by file inputting the necessary info (if it was not completed by the ‘default settings’ of a project). Here the necessity to implement a more batch-oriented workflow is clear, sometimes there are just too many files. We were thinking that it would be good if the software was able to infer information from the filename given a pattern configured by the user. I have seen such approaches for example in Audio Taggers (mp3tag for example). We tried to implement that in our tests and seems that it could work. Obviously if the filename doesn’t provide much information the manual input option is still there.
Would be nice to have some example datasets offered in the page for software demonstration. We had a bit of a problem trying to test the software because we don’t really have MEG datasets. We managed to download some files that worked but for the end user it would be a nice plus to have workable examples.
Inspecting the code it seems that the database is implemented in an ORM-like way. In the past we used mongodb but only for learning purposes. To be honest it is not clear for us which way is better though ORM would be nice to explore. Doing a bit of digging it seems that pybids uses sqlalchemy for this so maybe we could do something similar.
Would be nice to be able to import participant data from table-like files (csvs,tsvs,excel). I think it would be a good guess that of a lot researchers having their participants organized in such files and most knowing how to make an excel file. Having an option to input participant data this way would make batch-processes easier.
We really liked the tree file explorer. Our implementation used just a “select file” prompt which is too rough and slow. The tree view just seems to be the natural way for this kind of software.
The project default configuration is a neat idea, well a -must- basically.
Maybe it would be nice to be able to save the state of the program. Sometimes there are too much participants/files and maybe a researcher prepares the conversion through different days so if he could start from an advanced point it would be awesome. This could be also done by incremental conversion so that he converts what he cans day by day; this would require the software to know what it already converted by parsing the output folder. We don’t really know which way is better. It is probable that Biscuits already does some of this but we didn’t delve into that.
We were a bit worried because the BIDS MEG specification doesn’t really sets what extension should the file have but BIDS EEG does have this restriction. Doing some digging pyEDFlib could just do the job for EEG and we can also draw some inspiration from mnelab’s conversion.
The role of the BIDSHANDLER package seems to be making Biscuit bids-aware and capable of doing queries. Could pybids provide a similar role? We think this is a worthwhile question since pybids is more active.
We liked the extensive use of pytest, although we have used it recently for more signal-processing packages , we have never used it in the context of a interface based software. Thats a nice challenge.
An always present pressure is the problem of maintaining the software up to the last version of the standard. So the BIDScoin approach of having the schema on yaml files is interesting for us. We had it in python functions that returned dictionaries but the yaml files are better. We were wondering how we could use the schemas in here to simplify the process of updating the software to a new version of the standard.
Sadly the bids fields that need to be entered are not currently part of the schema files of the previous point. We did notice there are some efforts going on currently for that stuff to be in schema files. In that sense it could be also nice to have the field’s information in schema files in the software. Once bids adopts that type of files it would be easy to reconfigure the software to understand them rather the home-cooked files.
As you may notice we didnt delve too much in bidscoin because is even more apart from our EEG context so we need a bit of more time to fully grasp what can we learn from it. Currently the “no-rule mapping” idea along with using generated mapping yaml files seem really attractive to us. The idea of the institution giving a “bidsmap” to the researchers is awesome too.
The output’s preview of the bidseditor in bidscoin is also something we would like to explore. I have seen it in software like Bulk Rename Utility and it really does help the user with some actual feedback of what is actually happening. Maybe a good way to present the information to the user would be two tree file-explorers representing the before and after conversion. Whatever file in the output that is not complete could be shown in red and whatever is complete could be shown in another color. The user could then click in the red files to complete the information through popup interfaces. For inspiration there is software like Beyond Compare. The file content view would also be an important asset.
We don’t really know how bidscoin works to extract the information… taking into account that there aren’t actual rules given by the user it seems a bit like magic!
The whole idea of -mapping- seems to be the right framework though. What we propose for example by filename analysis is that the user provides the rules. We wonder if this could also be extended to folder structure and if this rules could be saved as yaml files. The mapping could then be conceptualized as applying this rules to the input folder structure and providing the input. Now, this is a rule-based approach, we wonder how could that be achieved without using rules as BIDScoin suggests. As we understand this functionality works through a sort of heuristics that then the user corrects and molds to their specific-case through the interfaces. As of now we don’t really know which approach would be better. In the rule-based approach for example researchers could share their “mappings” or adapt those of others; in bidscoin this map yaml file is more custom tailored for an specific case.
We have some questions regarding the scope. Could you explain a bit the following points?:
Incorporating continuous integration to ensure backward compatibility → (We don’t know what does this really mean)
Adding automatic suggestions based on mappings provided by the community ( We also don’t know what does really mean. Specifically what is a mapping in this context? My guess is that this is sort of a folder/filename structure schemas commonly used in the community or something similar to what we previously mentioned as shareable rule-based mappings. Correct me if I’m wrong)
Extending an existing GUI-based BIDS conversion tool to support EEG/MEG . (Does this mean that the contributions will be done on the chosen parent project or this extended means “inspired by” for example?)
Enhancing the tool so users can enter additional information, not recorded in the original EEG/MEG raw data files
In the last one we get the idea but we didn’t know if you refer to the user being able to input fields already in the bids schema (but not on the recorded files) or also being able to input fields that are not on bids (for example in participants.tsv the user may add columns at their choosing).
When we talked with the Neuropsychology team they were really interested in adding fields to either the participants.tsv and the events.tsv so is a common question among practitioners. It seems trivial but I’m not sure if it could get harder down the line.
Sorry for the long post and thank you for your time!
Just apologising for not responding yet. I was caught up in grant and paper writing.
In any case, we have no doubt that you really thought about the project, and we’ll try to respond as soon as possible.
I discussed with my fellow mentors, and yes, we see no problem to acknowledge GRUNECO. Moreover, we think it is the right thing to do given that your contribution will be substantial!
We still didn’t manage to go through all the points you raised (well done!), but we do like your approach of incorporating the specification of the required JSON fields within the schema YAML files (with the hope that BIDS will adopt this approach as well). We need to think well how it will fit with the json-schema.org schemas that validate the JSONs (e.g., bids-validator/eeg.json at 306a8cd002e7aa713a1a9374338451f4faf14974 · bids-standard/bids-validator · GitHub), but definitely something doable. Actually, one of the people on the original BIDS paper is a collaborator of us in the Neurodesk project (Satrajit S. Ghosh @satra), so if you’d like to contribute to BIDS itself down the road, I guess we can facilitate it.
Some extra general points that we want to bring up already now:
Whatever system we base the tool on should have good ongoing support and an established user base. That provides some assurance of longevity. So our decision on whether to extend an existing tool or only be inspired by one will probably take this into account.
Simpler is better, not just for the user, but also for the developer.
The GUI should be a stepping stone to automated pipeline conversion, and also to “fill in the gaps” where necessary. So any approach that requires many manual inputs really isn’t what we should be aiming for. That is where the automatic suggestions based on mapping provided by the community comes into place – the idea is that the tool will use some heuristics in order to “fill in the gaps” instead of asking the user for constant input. This heuristics can be based on previous BIDS conversions of similar datasets. Our idea is to maintain an online library of mappings used in successful conversions (the mapping from the EEG raw files to the BIDS, i.e. where the JSON fields are taken from? where the BIDS data files are extracted from?), and let the conversion tool consult with it.
Similarly to the above, but even more ambitious, is to also keep a library of input raw files, successfully converted output files, and mapping used. This can be used for the continuous integration mentioned. Every time we will upgrade the software, we will run it on the library, to make sure that the behaviour does not change.
We tend to like anything based on, or that works well with MNE-Python because i) it’s Python-based and ii) MNE handles EEG and MEG
By “additional information, not recorded in the original EEG/MEG raw data files”, we just mean information relevant to the EEG/MEG experiment that there is no practical way to incorporate in the raw EEG or MEG data format (e.g., trigger labels). We want the BIDS format to include all relevant data to the analysis. To keep everything together.
We also want to discuss with you the application to GSoC, so could you please email me and I’ll write you back? (my email is on github: civier (Oren Civier) · GitHub)
Looking forward to work with you,
Oren and the team
Hi there, I noticed your interest in BIDScoin (of which I’m the main author)
You may be interested to know I took the idea of plugins to a higher level and now abstracted the GUI and DICOM-conversion away from each other, and now also implemented the dcm2niix conversion in plugins myself (an example of eat-your-own-dogfood). I think EEG conversion could be implemented as a plugin too and would be happy to support that and provide tips and help.
Hi @Marcel_Zwiers , sorry for my incredibly late reply. I didn’t have the ‘watching’ option set up in this thread.
That would be interesting to implement. The project is conceived as a backend with an API so that others can plug into it. So maybe when the project is done there would be a way to plug the project as it was a plugin.
We are still in early stage so only the high-level design of the project is done. I will look into the dcm2niix conversion to see what ideas I can take from it and maybe foresee if plugin the project into dcm2niix would be feasible.
Im putting the links on a single comment since I cannot reply anymore until someone else comments here. Having that said, here are the links as they become filled :