@djarecka - I will report the issue on GitHub as soon as possible. I have tried to run the notebooks on Google Colab and they worked fine for me.

1 Like
@djarecka - I would appreciate the opportunity to start working on the code. Please let me know what specific areas you would like me to focus on. Thanks.
@adi611 - have you had a chance to clone the pydra repository and run the test locally (you can check the developers installation.
If you’ve done this, you probably saw that some tests are skipped, a few of them are skipped because they require slurm scheduler, and most of them are in test_submitter, search for need_slurm. In order to test them we use a simple docker image mgxd/slurm:19.05.1. Have you ever worked with docker? If you had, you can recognize some comments from our GitHub Action workflow:
- we pull the image
- start running the image in the background and mounting the local pydra repository
- setting clusters
- preparing python environment
- and running the tests
Please try to repeat the steps, and see if it works for you. Feel free to ask any questions!
1 Like
@djarecka - I tried the running the tests locally using the given developer’s instruction and this was the result: (no docker, no slurm)

As you mentioned there were some tests which were skipped and few of them were failing because they required slurm scheduler:
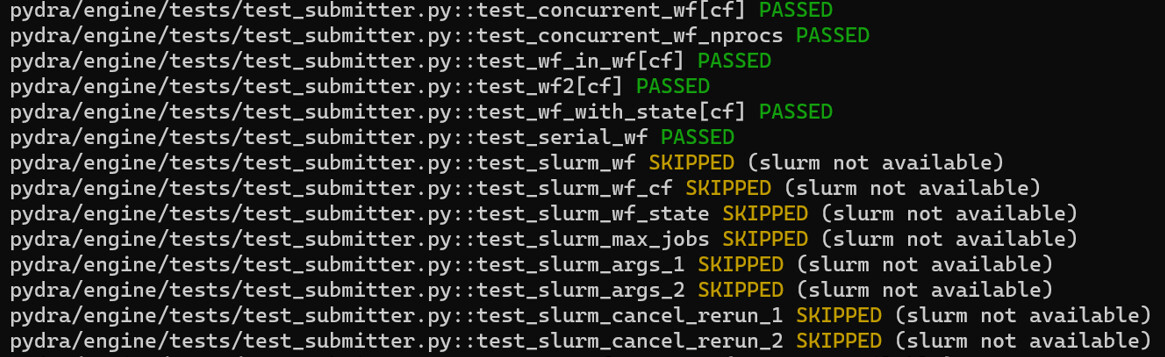
After following the instructions mentioned in the Github workflow (using docker and slurm):

The number of skipped test cases reduced from 96 to 88.
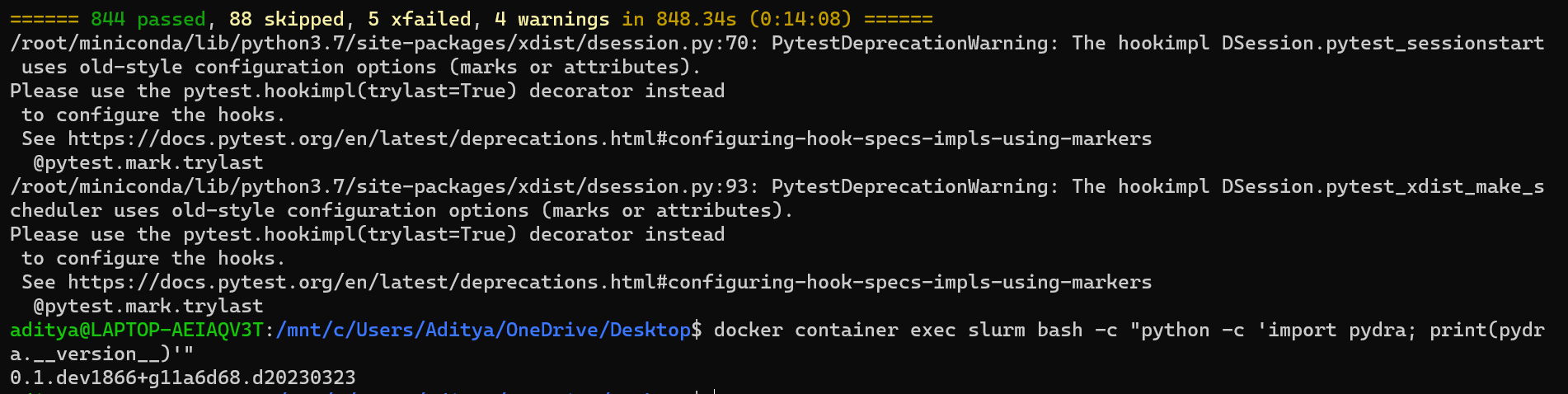
@djarecka - In the first coverage report, 830 test cases has passed and 96 are skipped while in the second report 844 has passed and 88 are skipped. So I’m confused why their sums don’t add up, is this ok?
I think they should sums up to the same number… but perhaps there are some changes when some tests are run twice if marked as flaky? Not sure. Could you run again to check if you have the same results?
Could you also double check if you indeed run the same version of pydra in both case? You can check it by running pydra.__version__
1 Like
@djarecka - There is a difference between the two versions, the first coverage report which runs on the command pip install -e ".[dev]" is running pydra version 0.1.dev1866+g11a6d68.d20230320
While the second coverage report which runs on pip install -e /pydra[test] is running pydra version 0.1.dev1866+g11a6d68.d20230321 which is a newer version.

@djarecka - Since the GSoC proposal submission phase has started, could you please guide us on the necessary specifications that will assist us in creating a successful proposal? Thank you.
if the versions are different that means that perhaps in the docker you’re not using the local version you have on your local machine. Did you mount the directory with local version of pydra to the container? The idea was to run the same version locally and within the container
@adi611 - you should read the official guide: Guides | Google Summer of Code | Google Developers
1 Like
Yes I did mount the local version of pydra. For confirmation I repeated the same steps as before and now they both have the same version: 0.1.dev1866+g11a6d68.d20230322 which is different from the earlier versions 0.1.dev1866+g11a6d68.d20230320 and 0.1.dev1866+g11a6d68.d20230321.
@adi611 - sorry, I’m a bit confused, so let’s try to clarify.
Now you have the same version of pydra when run locally and in the slurm container, correct?
Do you still have a different number of tests?
@djarecka - Yes I have the same version of pydra when running locally as well as while running in the slurm container but I still have different number of tests.

Ok, don’t worry for now that the number is different, we can think about it later. The most important is that you run in the container the version from you local directory.
You will see in thes_submitter tests that need_slurm, you can read them and try to understand. A couple of them check the additional argument that you can provide to slurm, i.e. sbatch_args, e.g. this one. You could add a test/tests that check --error and --output as the sbatch_args. We have some code that should be checking it, but I believe we don’t test it.
I tried writing tests for the required --error and --output as the sbatch_args:
@need_slurm
def test_slurm_args_3(tmpdir):
"""testing sbatch_args provided to the submitter
error file should be created
"""
task = sleep_add_one(x=1)
task.cache_dir = tmpdir
with Submitter("slurm", sbatch_args="--error=error.log") as sub:
sub(task)
res = task.result()
assert res.output.out == 2
error_log_file = tmpdir / "SlurmWorker_scripts"
assert error_log_file.exists()
@need_slurm
def test_slurm_args_4(tmpdir):
"""testing sbatch_args provided to the submitter
output file should be created
"""
task = sleep_add_one(x=1)
task.cache_dir = tmpdir
with Submitter("slurm", sbatch_args="--output=output.log") as sub:
sub(task)
res = task.result()
assert res.output.out == 2
output_log_file = tmpdir / "SlurmWorker_scripts"
assert output_log_file.exists()
But I am getting error for test_slurm_args_3 while testing:
-
test_slurm_args_3 - AttributeError: 'NoneType' object has no attribute 'replace'
Possible reason for this could be in workers.py here:
if not error:
error_file = str(script_dir / "slurm-%j.err")
sargs.append(f"--error={error_file}")
else:
error_file = None
Here we are assigning error_file to None when --error flag is indeed detected. And later we are using .replace() function on error_file which is None in our case.
@djarecka - Was this the expected solution for the given task? And if yes, what could be the possible workarounds and fixes to the error?
As I said I realized that this part of the code is not tested, so it’s very likely that we should fix a couple of things. Could you create a PR with you tests? You can also suggest a fix, or we can just discuss it in the PR. Thanks!
Next Tuesday there is a deadline for the project submission. I would be happy to read the draft if you prepare something this week.
Also, one of the last year contributor agreed to share her proposal, so you can see an example: proposal.pdf - Google Drive
More example you can also find on PSF website.
As the project description says the workers you want to add can depend on the your interest, but if you don’t have anything specific in mind, you can look at PSI/J that should provide a unified API for various scheduler. Perhaps you could try to test it with pydra