I have preprocessed my data using fMRIprep and then wanted to use it in SPM for further analysis. Usually, I would remove volumes where head motion was > 2mm or 2 deg. I took the motion parameters from the confounds.tsv file ( trans_x , trans_y , trans_z , rot_x , rot_y , rot_z) and was trying to find occasions where motion was > 2mm or 2 deg. To make sure I was doing this right, I also ran one session in SPM using realign to produce the rp.txt file which contains the 6 head motions parameters.
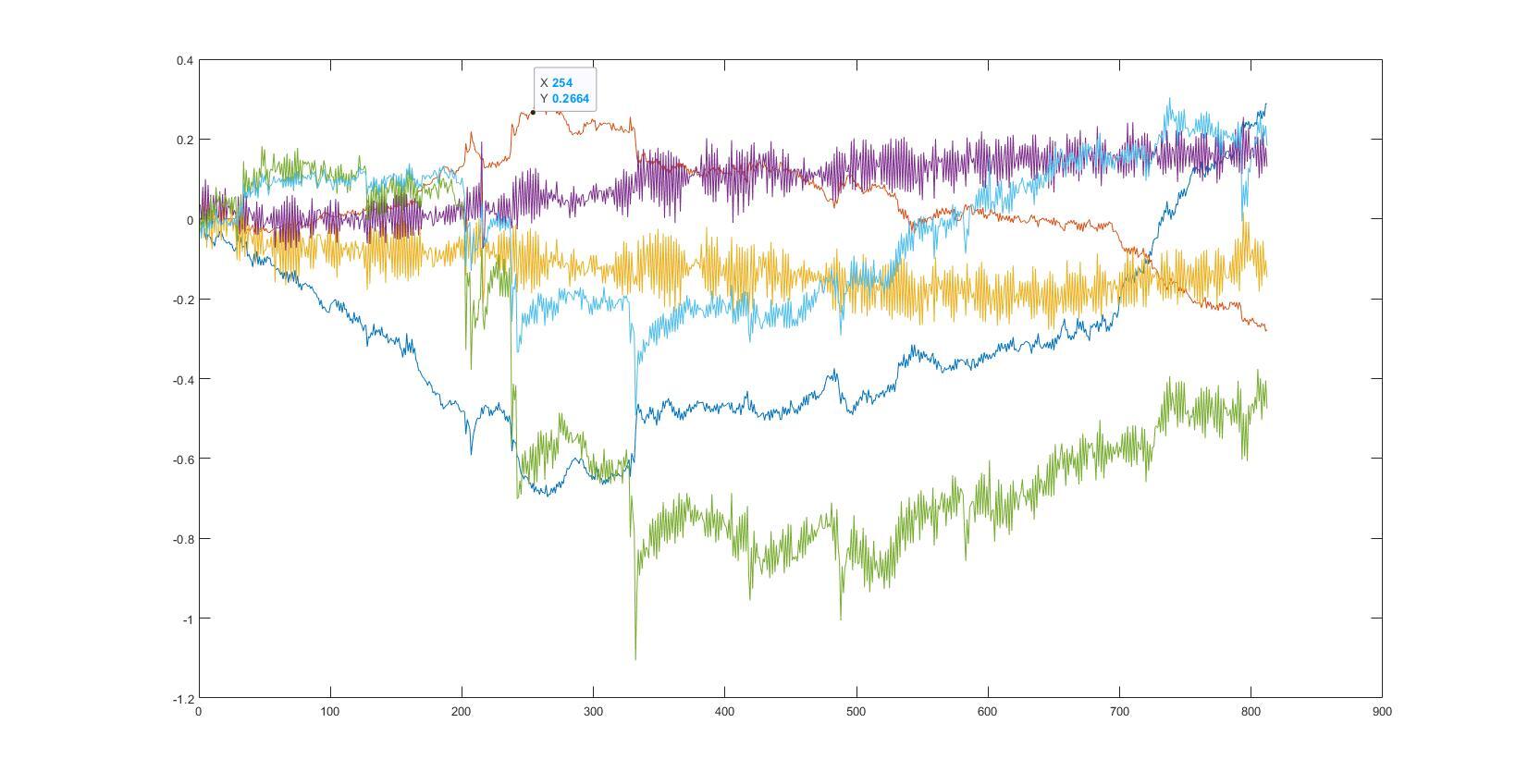
When I compared the fMRIprep and SPM motion parameters I noticed that the overall trends were the same, but there were some noticeable differences between them even though they both should save in mm and radians. In the attached figures I plotted x, y, z translations and x, y, z rotations for fMRIprep (dark orange, purple, light blue lines) and SPM (dark blue, light orange, green lines).
As the figures show, sometimes fMRIprep values are inverted compared to SPM and can also be a smaller value (half the size).
Do you know if the inversion issue is caused by the FSL/SPM hemisphere difference?
Why is the scale of fMRIprep not matching SPM? Is it not in mm or radians or am I extracting the wrong confounds?
Have you compared the framewise displacement between the two alternatives?
The problem you propose is a bit of a rabbit hole because there are at least two sources of methodological variance you can’t control for:
Registration methods: in fMRIPrep we use FSL MCFLIRT. Although some literature has compared several alternatives, the different implementations of image registration do not coincide on their solutions. They are typically close, as per the literature, but never the same.
Rigid motion parameters: these are typically calculated from the internal representation of the transforms (generally an affine matrix) and software sets different assumptions for this transformation (e.g., you can decide that the center of rotation is at the center of the volume, at the coordinate (0,0,0) of the corresponding physical coordinate system or at voxel with index [0, 0, 0]. The inversion you mention is likely coming from this issue.
An additional problem is that a 2deg rotation might not be ever seen if your parameters were calculated with the center of rotation on a corner of the image. In those cases, translations of 2mm can be alternatively estimated as a small rotation, so you will also miss some big translations. That’s why J. Power proposed the Framewise Displacement as a measure of head motion - please read that paper (it’s referenced on fmriprep.org). The two alternatives should overlap better using FD (although, there are also issues here). So independently of what conclusion you arrive, please use FD instead of motion parameters.
Complementing Oscar’s response, the Power’s FD measure is based on a “conversion” of derivatives of the rotation parameters from radians (rotation parameters) to mm, in order to combine with the translation parameters. This is based on a simplification (looking at voxels at a certain distance from the center of rotation), and also depends on the coordinate space (center of rotation). To avoid depending on the reference space, you would need to generate voxel-wise displacement maps, like in this paper https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3896129/ (have a look at Fig 1).
However in my experience Power’s FD measures will have high correlation across implementations of motion estimation, but will have shift in absolute values (maybe due to the dependence on reference space). I would be curious to know if that’s what you observe @coulborn
@pbellec should we generate another regressor? something like the average voxel-wise displacement map for the cortical gray matter? (or for the surface vertices, if freesurfer was enabled) I’ve been entertaining this idea and it would be a very low-hanging fruit to implement.
@oesteban sorry I missed that. I need to keep neurostars open at all time
This is deviating from the original question and suggest we move this to some other medium.
I like the idea of generating summary statistics of motion that would not depend on the reference space, and hopefully be (more) directly comparable across software. I don’t know of such measures already proposed in the literature, and if it does not exist already, it would require some amount of validation to compare with more classical motion6, motion12 and motion24 models. But I also agree this is relatively straightforward to implement - and validate.