Hey everyone,
I’m currently using fmriprep v21.0.0 and wish to run tedana on a set of echo-wise data. I understand that v21 has got a recent addition in --me-output-echos that supposedly generates the individual echo time series. I did run that is part of the fmriprep process but the information provided here is really vague and does not tell me where this was output to. In any case, I suppose the required data would be in the fmriprep_wf directory, and I am supposed to run the collect_fmriprep() function onto this directory to extract the relevant information?
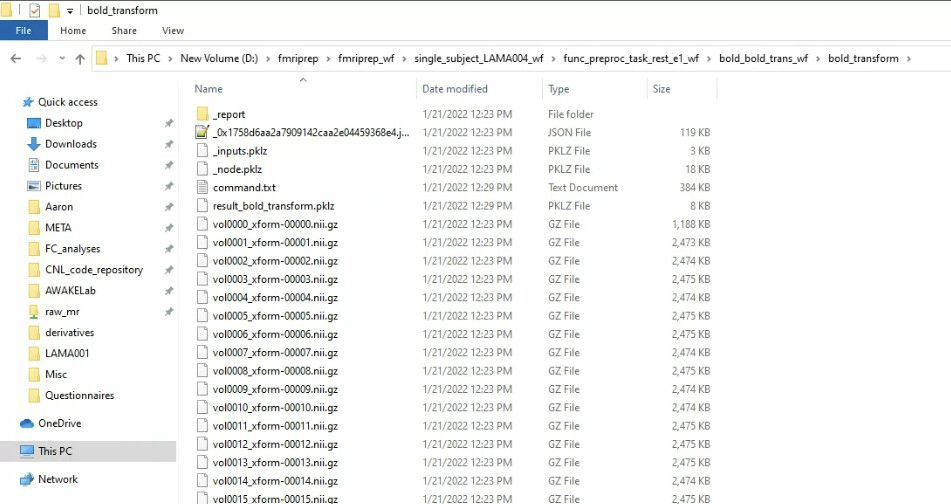
If so, the script provided here does not seem to be compatible with the current fmriprep_wf directory.
When I tried to run the above script, the only output seen was the string “Wrangling subject n” and then the script ended almost instantaneously. I then tried to alter the codes within collect_fmriprep() and it seems like _bold_file_ (it does not exist) needed to be changed to bold_transform?
bf_dirs = sorted(glob(op.join(bb_wf_dir, "bold_transform*"))) #_bold_file_*
The next part I believe, has got to do with:
idx = bf_dir_list.index("sub-{0}".format(sub))
where files in the bf_dir_list do not follow the ‘sub-’ label. I am not sure how to fix this part as I don’t know how the output of the working dir of earlier fmriprep versions look like (first time using!).
I tried to look for a step by step guide of how to run this process from start to finish but could not find any out there apart from the links provided above. Can anybody assist with this? I must say I am very new to this.