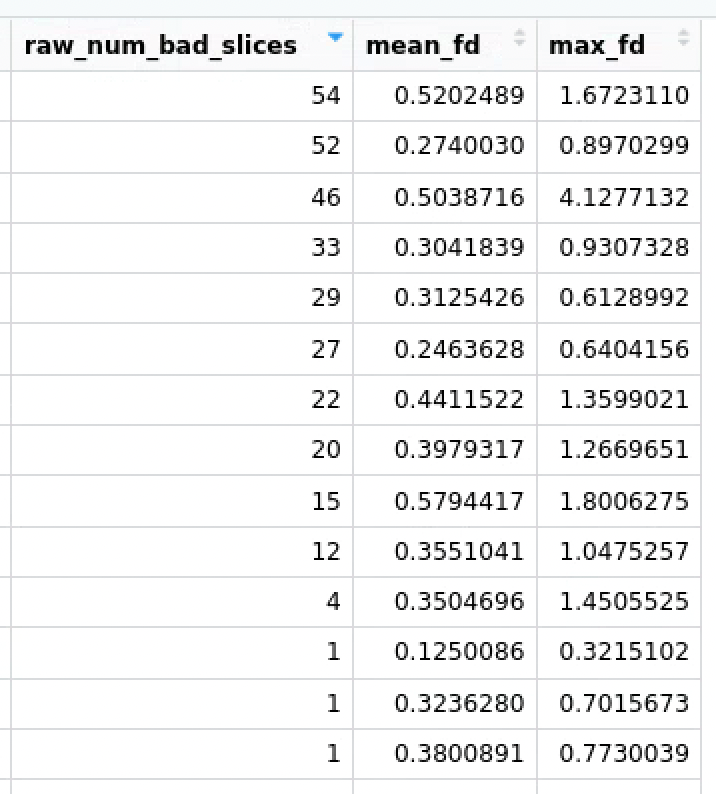
I ran preprocessing for my dataset with qsiprep. Everything seems to have worked fine, but I have a few participants who have very high values for raw_num_bad_slices. In one case, that’s linked to also a high mean_fd as well as max_fd (see screenshot below).
In my experience, people usually primarily look at mean_fd and exclude participants that diverge more than two SDs from the mean. However, according to this logic, I would be including participants who have a lot of bad slices, sometimes up to 50 (and I only have a toal of 88). I would expect that there is some relationship between bad slices and mean_fd but this seems not to be the case.
Does anyone know of guidelines or rules of thumb that people typically used in scenarios like these to include/exclude participants (we have a relatively small sample and would like to keep as many scans as possible)?
Motion really isn’t that important to DWI outputs, especially in dense acquisitions with lots of volumes, due to the redundancy between nearby gradients. I wouldn’t use the same exclusion criteria one might apply to BOLD data.
I like neighbor correlation, also a QC output, as a quality measure. It quantifies, on average, how well two neighboring gradients correlate with eachother (close to 1 is good, 0 bad, well on average be higher in more dense acquisitions since neighbors are closer together in q-space). You can choose to exclude based on that thresholded and/or include is as a covariate in your statistical models.
I see, coming from fMRI that is something I had not considered.
It seem I may be too stupid to find it a description of the columns of ..._desc-confounds_timeseries.tsv in the documentation, but I have several columns related to neighbour correlation in my output, some related to the T1 (I guess) because the include t1in the name.
Do you suggest to simply look at raw_neighbor_corr? For this value I have a range from 0.9389 to 0.9766 which is actually very good according to your guidance.
That looks even better (all > 0.98). Just for piece of mind: What then are the other columns with more complex names, e.g., what is t1post_masked_neighbor_corr as the one with the most complex name (assuming this reflects the most processing steps)?
I assume that t1post_masked_neighbor_corr is what happens after application of the brain mask whereas t1_neighbor_corr covers the whole image?
Yes, the masked versions are only within the brain mask. What that won’t capture, however, is if there are weird susceptibility distortions that lead to data leaking outside the mask or artifacts like frontal pole smearing.