I have beeen searching for an answer to this, but I didn’t really find anything. Feel free to point me to an existing thread if it has already been adressed.
I am wondering how people generally add the “IntendedFor” in their jsons? I am using dcm2niix to convert, so the field is not there. There may be a new version that I am not aware of? Or if there is another converter that automatically adds this; that might be the best solution. I have tried googling for how to edit jsons automatically using both bash and Python scripts, but none of the solutions I found worked.
I have been adding the field manually up until now, but it’s very cumbersome and obviously prone to errors. My dataset has three sessions and two task runs for each subject, so there are 12 correction scans per person (we use the PE-polar approach). I am guessing this is also a challenge for those working with the huge open datasets that are out there.
According to this post, fw-heudiconv inserts the IntendedFor field automatically. I don’t have any experience with that tool, but it looks like you set your IntendedFor field in the heuristic file. In my program, we generally use a custom function called intended_for_gen() that finds the most recent field map before each functional scan after conversion to BIDS. That way you can remove bad field maps before you assign the IntendedFor field.
I think it’s probably a mistake to assume that everyone uses the same approach for their field maps, however. While I generally default to using the closest field map before each fMRI scan, it might make more sense to grab the closest field map to each scan regardless of whether it’s before or after. I’m not sure there’s a one-size-fits-all solution to this, but those two options can probably help.
EDIT: There is also this heudiconv thread, in which @satra mentions an approach that sounds better (at least for Siemens scanners), although I don’t know if there’s a straightforward implementation out there. The method described compares the shims from different files to assign field maps to scans.
An additional, inelegant but effective method for bash that I include in a script that does the dicom to nii conversion - it adds the Intended for right after the EchoTime details
So I’ve been testing the R and bash solutions, and they both seem to work (at least for one fieldmap - one run). Thanks to all of you for your great help! I will keep testing and hopefully I can apply it to my 3 ses + 2 runs + 2 fieldmap-per-run-setup
@tsalo thanks for pointing this out and for your suggestions. I saw that dcm2niix is recommended by the BIDS specification, so I might stick with using that… Also yes, probably there are many ways to acquire the fieldmaps as well! We have them actually after each BOLD run. Our fieldmaps are named the same as the corresponding run (e.g. task_run-1, rest), so it shouldn’t be too hard to work into a script.
A little late to the party but here’s been my solution for one field map with python. I had a version that would point different fieldmaps to different runs but I’ll have to go rooting around for that.
Here is the code that I wrote which I have been using for my fieldmaps. I hope this can help.
import os
import glob
import json
subjectsPath = os.path.join('/data', 'D2', 'Nifti', 'sub-*')
subjects = glob.glob(subjectsPath)
for subject in subjects:
#Edit 'ses-1' to be the same as your session
fmapsPath = os.path.join(subject, 'ses-1', 'fmap', '*.json')
fmaps = glob.glob(fmapsPath)
funcsPath = os.path.join(subject, 'ses-1', 'func', '*.nii.gz')
funcs = glob.glob(funcsPath)
#substring to be removed from absolute path of functional files
pathToRemove = subject + '/'
funcs = list(map(lambda x: x.replace(pathToRemove, ''), funcs))
for fmap in fmaps:
with open(fmap, 'r') as data_file:
fmap_json = json.load(data_file)
fmap_json['IntendedFor'] = funcs
with open(fmap, 'w') as data_file:
fmap_json = json.dump(fmap_json, data_file)
@skebaas Thank you! Wow this is very simple and efficient
and @Jeff_Dennison I only just got around to testing yours as well. It works!
I’m pretty sure I could easily adapt both of these scripts to applying the relevant runs for each json myself. So many solutions, I’m very grateful to you all!
I’m just curious about something, @skebaas. I see that the new jsons in your version, contain all lines on the same line (so everything is dumped on line 1). Does that work / is that like… OK? I am not able to validate either version atm cause I don’t have immediate access to our data.
This is one of the reasons I didn’t manage to do this myself, I thought the json format was very strict and I had to keep the “new line” format it was originally in.
@hannesm from what I understand there are two types of json objects. Normal JSON and JSON lines. JSON lines separates each object onto one line, and I assume it is recognizing all of the data as one object and shoving it onto that line. This can be fixed by converting it to normal JSON.
@hannessm
Also, if you’re interested I have a script that automatically removes the “IntendedFor” statements from the jsons in a subject directory (to be able to quickly fix my mistakes when adding them in). Its useful when you are in the testing phase of adding them in.
Best,
Alex
To answer your question about making the json data appear on multiple lines, it appears that specifiying indent with the json.dumps() function fixes the problem.
Here is the code for removing the IntendedFor statements from your jsons. This could be useful.
#! /usr/bin/python3
import os
import glob
import json
'''Remove IntendedFor statement from json files if a mistake was made'''
#grab the epi jsons and store them in a list
#files = os.path.join('/home', 'skebaas', 'Nifti', 'sub-*', 'ses-1', 'fmap', '*.json')
files = os.path.join('/data', 'MNA', 'data', 'Nifti', 'sub-*', 'ses-1', 'fmap', '*.json')
fmaps = glob.glob(files)
#next search through each fmap json and remove 'IntendedFor'
for file in fmaps:
with open(file, 'r') as data_file:
data = json.load(data_file)
try:
print(f"removing IntendedFor statement from {file}")
del data['IntendedFor']
except KeyError:
print(f"ERROR: could not find IntendedFor statement for {file}")
with open(file, 'w') as data_file:
data = json.dump(data, data_file)
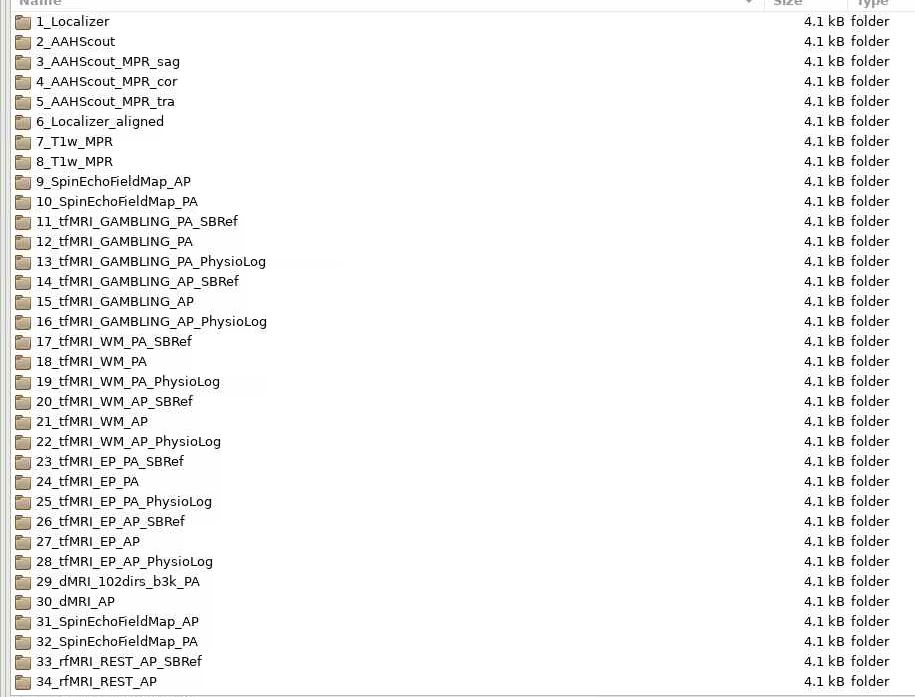
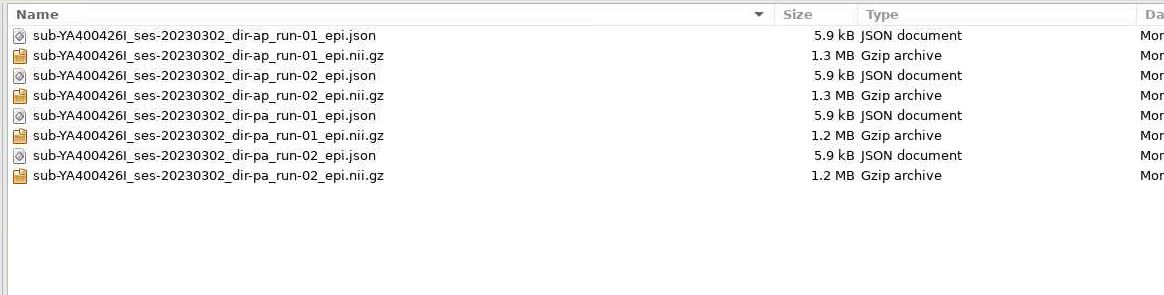
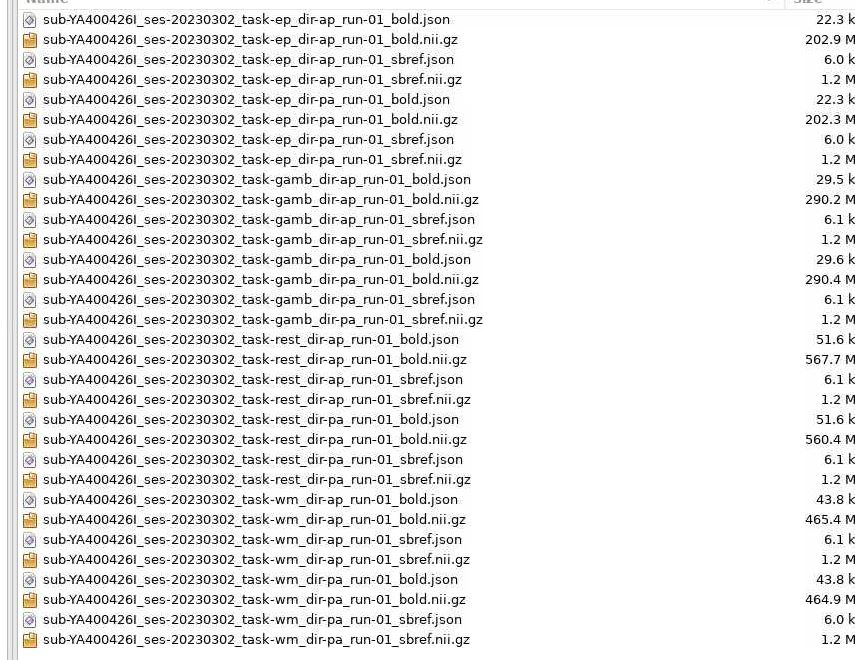
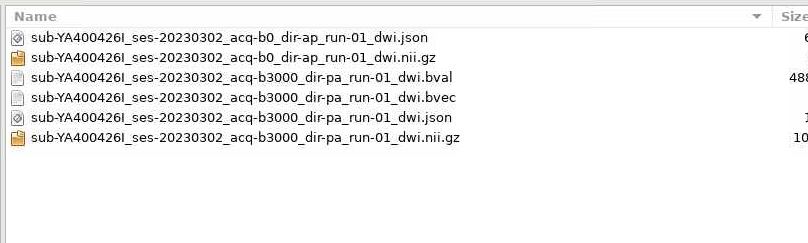
Hi guys. Good morning. I’m new to Neurostars! I’m trying to add IntededFor.py to my JSON files and am not sure how to go about it. I have a script like @skebaas that adds the Intended for when there is only one AP/PA fieldmap collected but this is a new study, and we are collecting multiple field maps.
In this instance we have 2 runs of AP/PA. I want to add the first AP/PA run-01 to the .json files in the func folder for all the task-based data and the run-02 AP/PA for the .json files in the diffusion DWI data.
Does anybody have a Intendedfor.py script they can share for how to go about handing multiple field maps?
I think someone mentioned using the Acquisition-time inside the .json file but I’m not sure how do do it. If you could share your script and how you went about doing handling multiple field maps I would really appreciate it.
Some background info—I did DICOM to Nifti conversion using .heudiconv.
It is hard to write a precise script for you because we have do not know what your file naming convention is. I encourage you to explore ChatGPT, which I used to create a script below that you can edit to match your filesystem.
import os
import json
def add_intended_for(json_path, intended_for_runs):
with open(json_path, 'r') as json_file:
data = json.load(json_file)
# Add or update 'IntendedFor' field
data['IntendedFor'] = intended_for_runs
with open(json_path, 'w') as json_file:
json.dump(data, json_file, indent=2)
# Specify the root BIDS directory
bids_root = '/path/to/your/bids/dataset/'
# List all subject directories in the BIDS root
subject_dirs = [subject for subject in os.listdir(bids_root) if os.path.isdir(os.path.join(bids_root, subject))]
for subject in subject_dirs:
# Specify the paths to JSON files for functional, diffusion, and fieldmap data
fmap_dir_ap_run01_json_path = os.path.join(bids_root, subject, 'fmap', 'dir-AP_run-01_epi.json')
fmap_dir_pa_run01_json_path = os.path.join(bids_root, subject, 'fmap', 'dir-PA_run-01_epi.json')
fmap_dir_ap_run02_json_path = os.path.join(bids_root, subject, 'fmap', 'dir-AP_run-02_epi.json')
fmap_dir_pa_run02_json_path = os.path.join(bids_root, subject, 'fmap', 'dir-PA_run-02_epi.json')
# Gather all BOLD and DWI niftis for the subject
bold_niis = [f'/path/to/{subject}/func/{file}' for file in os.listdir(os.path.join(bids_root, subject, 'func')) if 'bold.nii.gz' in file]
dwi_niis = [f'/path/to/{subject}/diffusion/{file}' for file in os.listdir(os.path.join(bids_root, subject, 'diffusion')) if 'dwi.nii.gz' in file]
# Specify the intended runs for each type
intended_for_func = bold_niis
intended_for_diffusion = dwi_niis
intended_for_fmap_run01 = bold_niis # All BOLD niis for run-01 fieldmaps
intended_for_fmap_run02 = dwi_niis # All DWI niis for run-02 fieldmaps
# Add 'IntendedFor' to run-01 fieldmap data
add_intended_for(fmap_dir_ap_run01_json_path, intended_for_fmap_run01)
add_intended_for(fmap_dir_pa_run01_json_path, intended_for_fmap_run01)
# Add 'IntendedFor' to run-02 fieldmap data
add_intended_for(fmap_dir_ap_run02_json_path, intended_for_fmap_run02)
add_intended_for(fmap_dir_pa_run02_json_path, intended_for_fmap_run02)
Does that make sense? Thank you. Any help would be appreciated. I’ve also attached the single IntendedFor.py script I used for one field map which is this:
#!/usr/bin/python3
import os
import glob
import json
subjectsPath = os.path.join('data','Nifti', 'sub-*')
subjects = glob.glob(subjectsPath)
for subject in subjects:
print(subject)
#Edit 'ses-1' to be the same as your session
fmapsPath = os.path.join(subject, 'ses-1', 'fmap', '*.json')
fmaps = glob.glob(fmapsPath)
funcsPath = os.path.join(subject, 'ses-1', 'func', '*bold.nii.gz')
funcs = glob.glob(funcsPath)
#substring to be removed from absolute path of functional files
pathToRemove = subject + '/'
funcs = list(map(lambda x: x.replace(pathToRemove, ''), funcs))
for fmap in fmaps:
with open(fmap, 'r') as data_file:
fmap_json = json.load(data_file)
fmap_json['IntendedFor'] = funcs
with open(fmap, 'w') as data_file:
fmap_json = json.dump(fmap_json, data_file, indent=4)
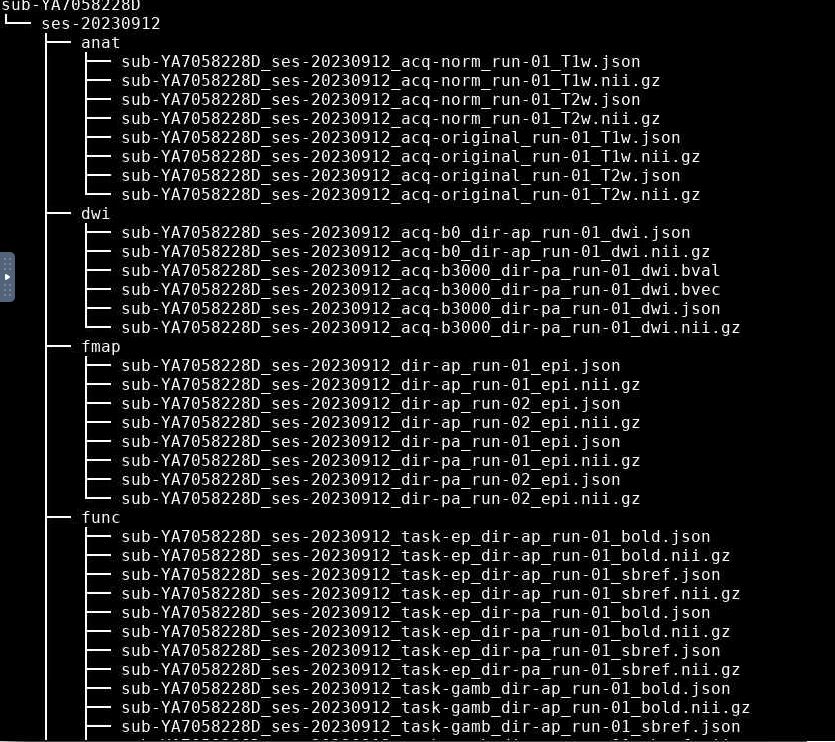
That first image suggests your data are not BIDS valid. All data must be in ses-X/[func|fmap|anat|dwi] folders. I suggest your reorganize your data, update the script to match your file system, and open a new post should your errors persist.
And for future posts, it is easier for us to read directory structures using formatted text. That is, run the command tree on a folder, then copy and paste the outputs here, surrounded by tick marks so the text is formatted nicely
What I’m trying to do is for the fmap AP/PA run-01 pair to have that be intended for the .json files in the func folder and the run-02 AP/PA pair to be intended for the diffusion scans in the DWI folder. But I’m not sure if the scans sometimes get messed up it could output more than one run (e…g, run-03 for AP/PA). This is not correct as there should only ever be 2 runs for AP/PA so I was wondering if there was a way to use the first pair for the func folder and the second pair for the diffusion. Would it make sense to then use acquisition time as an indicator?
How have other people who have multiple field maps gone about inserting IntendedFor?