Dear datalad experts,
I have a datalad dataset comprising several datalad subdatests.
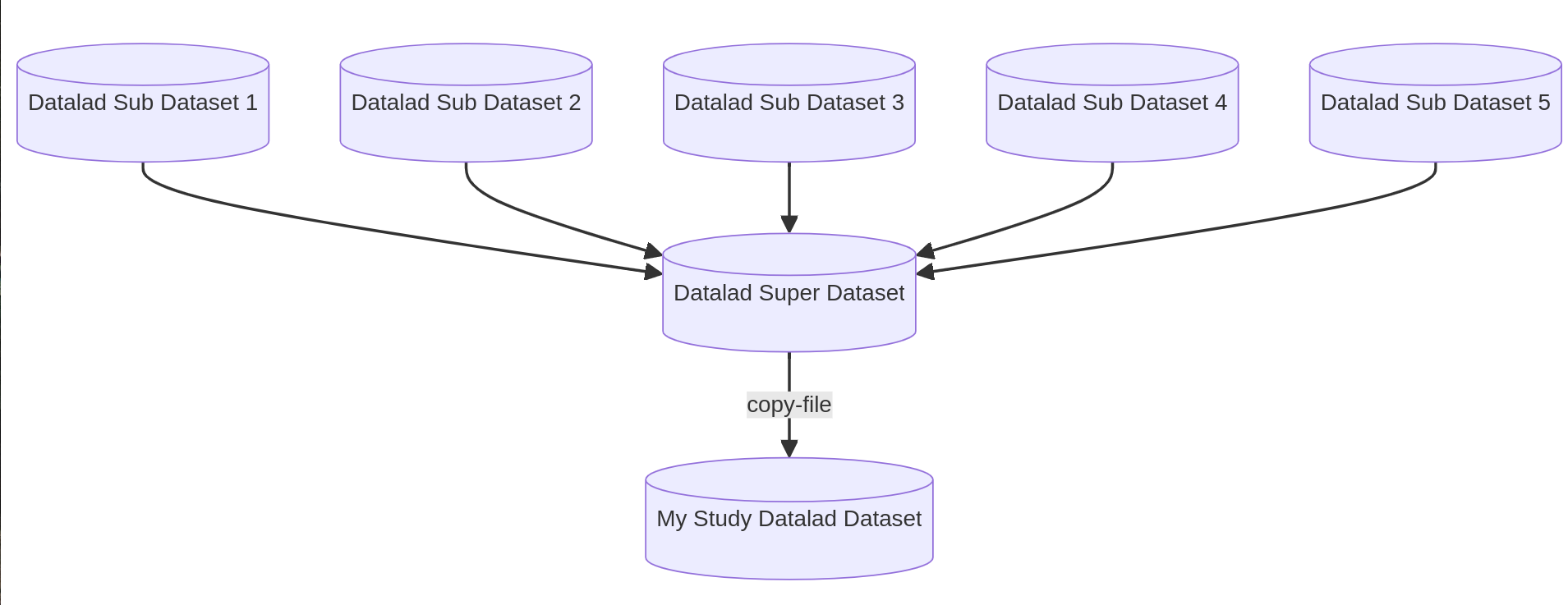
From these datasets I would like to extract several files into a new subdataset to contain data for a dedicated study (similar to the HCP structural connectivity scenario described in the datalad handbook).
I used copy-file to extract the files of interest and save them into a new dataset and it worked perfectly.
I then tried to modify my initial data and integrate change into the dataset created with copy-file but I did not manage.
Are you aware of a solution for such case scenario?
All the best,
Alex
The “tricky” part here I guess is that copy-file just copies associated URLs, and not any other availability information ATM. Thus whenever you “modify my initial data and integrate change” I guess “not manage” == “no URLs were copied”, correct?
In theory, ideally, we should tune copy-file to take advantage of introduced since then git-annex-filter-branch and I feel that we had some related discussions with Joey on “copying files” with all annex metadata, but can’t put my finger on the pulse ATM. Another related “to-be-done” is Consider command for spliting dataset · Issue #3554 · datalad/datalad · GitHub .
Meanwhile – could you describe a little more of your use case (how to modify, why not sharing via URLs, how “did not manage”?)
Hello @yarikoptic,
thank you for your quick and complete answer. I am trying to achieve something like in the schema hereunder. For the purpose of the tests, I copied-file .json files that were annexed (no text2git option) corresponding to all the subjects in my super-dataset and stored them into my Study Datalad Dataset.
Then I opened a .json file and modified its content changing the value of a key (3 to 3000) in the original super-dataset and could not see the change in the study dataset. Ideally i would like to propagate the change made to the original file to the file copied in the study dataset. Currently the copied file is still pointing toward the previous version of the file which make a lot of sense. How can I update it ?
I tried to achieve it with a datalad-sibling and then use git-filter-repo to select files of interest only but it affected all branches of the git repo
Where (on which remote) did you store those modified .json files in original super dataset?
If it is ‘git-annex’ branch is not that huge, in principle, you could ad “Datalad Super dataset” as a remote to your “My Study Datalad dataset” and “git annex merge” availability information, or even git annex get --keys of interest. Meanwhile you could simply cp the annexed .json files (key symlinks) of interest over into your “my study” datalad dataset and “inherit” their availability information. But if “Datalad super dataset” is too big, then best not to add it as a remote…
note to myself: in above I think I was thinking about copy-key (--batch) to copy/merge availability info which was resolved by Joey by creating filter-branch so it might be a matter of figuring out correct invocation matching your usecase and/or creating a helper. But it also all boils down relating to how to store/share those annexed .jsons?
did you consider migrating them to git (instead of annex) and then could just use git diff ... | git am or other mechanisms to “propagate the changes”
Hello @yarikoptic , at the moment I dont use a particular remote. I performed few tests with a RIA to have a backup. Till now, I have no remote as it was a proof of concept only
Ok thanks for the advice , I will try that 
Sure, I used .json to perform some tests as theiy are more convenient to modify. The real files I would like to manage are nifti and DICOM files similar to what is described in the HCP connectivity case of the datalad handbook