Hi,
I am wondering if it’s possible to visualize the brain region given a specific topic term in the dataset. I looked through the documentation but couldn’t find it. Your help will be much appreciated. Thanks!
Hi,
I am wondering if it’s possible to visualize the brain region given a specific topic term in the dataset. I looked through the documentation but couldn’t find it. Your help will be much appreciated. Thanks!
Hi Xinhui,
Can you give a bit more context?
If you’re talking about topics from a GCLDA model, then we actually have an example that covers that: NiMARE: Neuroimaging Meta-Analysis Research Environment — NiMARE 0.0.9rc2+9.gf69f396.dirty documentation
Otherwise, I assume the topic weights are included as annotations in the Dataset, in which case I would recommend just running a meta-analysis. The topics from an LDA model (whether generated with NiMARE or downloaded from Neurosynth) do not have associated spatial distributions in the way that GCLDA topics do, so it’s up to you to decide how studies map to voxels.
If you want something similar to what GCLDA does, you could probably use topic weights for a weighted average, but you’ll still need to decide on a mapping from study to voxels (probably using a KernelTransformer, as you would with a standard coordinate-based meta-analysis). I could probably mock up some code to do that, but it’s just a vague idea and I think running a meta-analysis is more defensible.
I hope that helps.
Best,
Taylor
Hi Taylor,
Thank you for your reply!
Specifically what I want to do is to visualize the brain region related to this NeuroSynth topic (Neurosynth: topic 11). It sounds like I’ll need to run a GCLDA model?
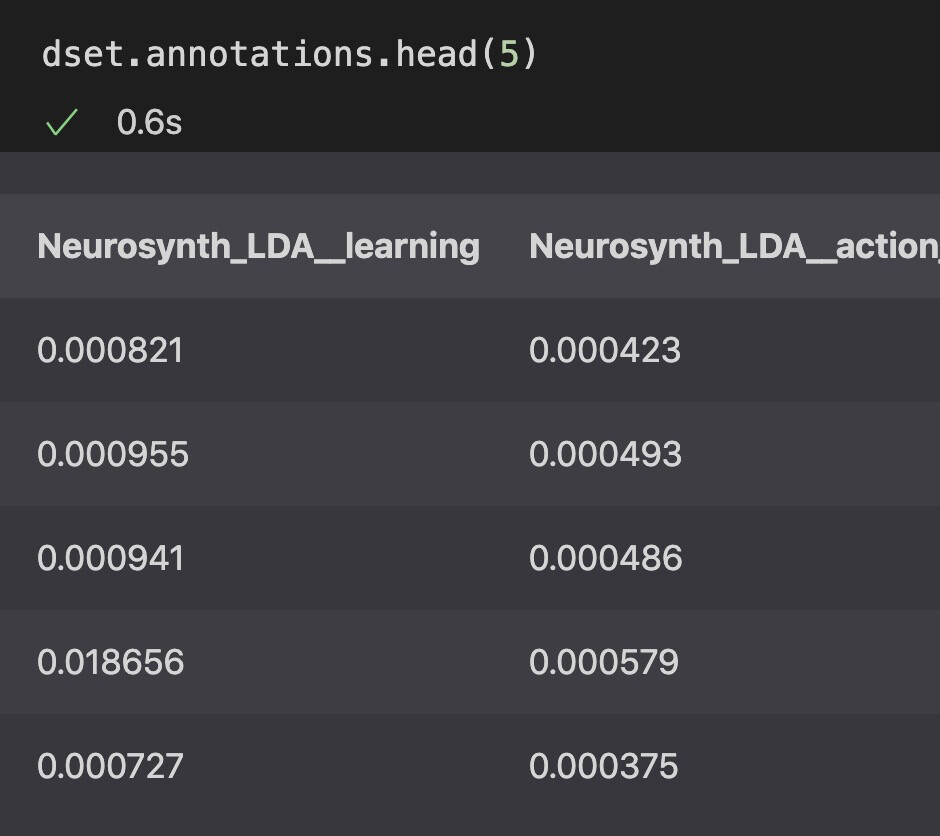
I checked out the website you sent, but still wonder how to visualize a voxel map given a label. My dataset looks like below and the label I am interested in is Neurosynth_LDA__learning:
I changed the text variable to my topic label in this code block but I got an empty map. I used a toy dataset to test the code first, not a large NeuroSynth dataset, so the empty map might be caused by the small dataset. Do you think I am on the right track and should run GCLDA with the real NeuroSynth dataset?
text = "Neurosynth_LDA__learning"
encoded_img, _ = decode.encode.gclda_encode(model, text)
plotting.plot_stat_map(encoded_img, draw_cross=False)
Thanks,
Xinhui
I see. If you want to visualize LDA topics, then GCLDA methods (such as gclda_encode) won’t work, because there is no associated p(voxel|topic) for LDA.
If you do run a GCLDA model, the topics will be quite different from ones from an LDA model (also it will take a long time). There’s no guarantee that the GCLDA model will have topics that align with the same constructs as the LDA model you’re using.
The GCLDA model is different enough that this function just won’t work. The fact that it returned an empty map instead of raising an exception seems like a bug to me, actually. If you do generate a GCLDA model and want to use the encoding function, then you should feed it free text, rather than a topic name.
Regarding your primary question (how to visualize LDA topics), I think that just running a meta-analysis and looking at the unthresholded results will probably get you what you want, but I threw together some code to calculate a weighted average that directly takes the topic weights into account. I haven’t tested it, and if you want to use it in a paper you’ll want to justify it, but I think it could be useful:
# Convolve your coordinates with a kernel to make MA maps.
# The exact kernel transformer is up to you,
# but MKDA doesn't require sample size and is used in Neurosynth,
# so I think it's a good choice here.
kernel = nimare.meta.cbma.kernel.MKDAKernel()
ma_array = kernel.transform(dataset, return_type="array")
# Make sure no studies are missing coordinates
assert ma_array.shape[0] == len(dataset.ids)
# Get list of topics from Dataset
topics = [c for c in dataset.annotations.columns if c.startswith("Neurosynth_LDA")]
# Now, you can do a weighted average using the topic weights
for topic in topics:
topic_weights = dataset.annotations[topic].values
weighted_average_array = np.average(ma_array, axis=0, weights=topic_weights)
weighted_average_img = dataset.masker.inverse_transform(weighted_average_array)
weighted_average_img.to_filename(topic + ".nii.gz)
You might need to do some debugging to get it actually working, and if you do use it I’d love to see what the results look like.
MANAGED BY INCF