Hi all, I have a statistical problem and wonder if anyone has a good idea on how to model this appropriately? I have a series of 2D matrices (one for each subject in my dataset). Each matrix holds information about the activity of a set of brain regions (reg1, reg2, …) across multiple conditions (y1,y2,…). Now I would like to test the hypothesis, that there is a set of regions that is significantly more active than all other regions across all conditions (in other words: regardless of y1, y2, …) and across all subjects. Here’s a visualization to get a better intuition for the problem:
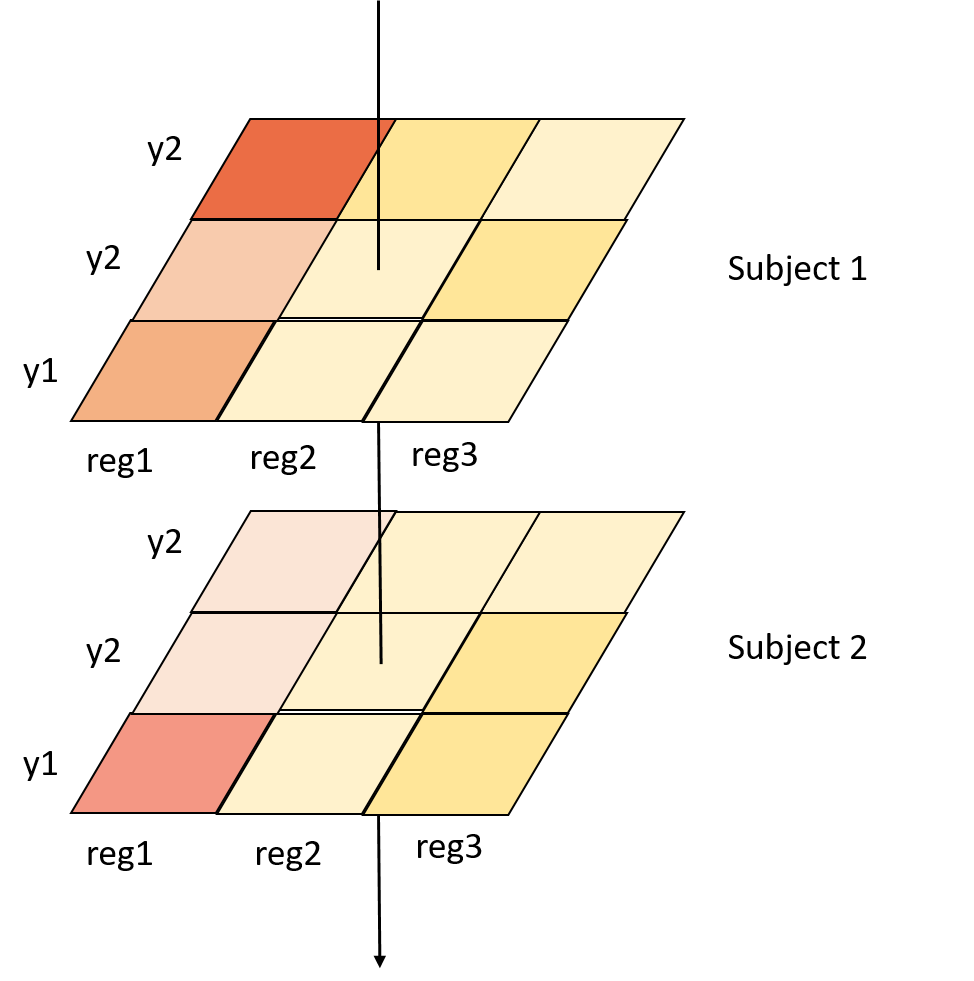
Using this example, one could hypothesize that there is a group of regions (in this case region 1) that is more active than the other regions. However, it is important to note that I do not have a specific hypothesis (I do not want to theorize which regions I expect to show more activation than others). Rather, I am looking for some sort of unsupervised procedure that can detect these regions.