i am new to preproessing multi-echo data and plan to use the fMRIprp + Tedana + XCP_D pipeline.
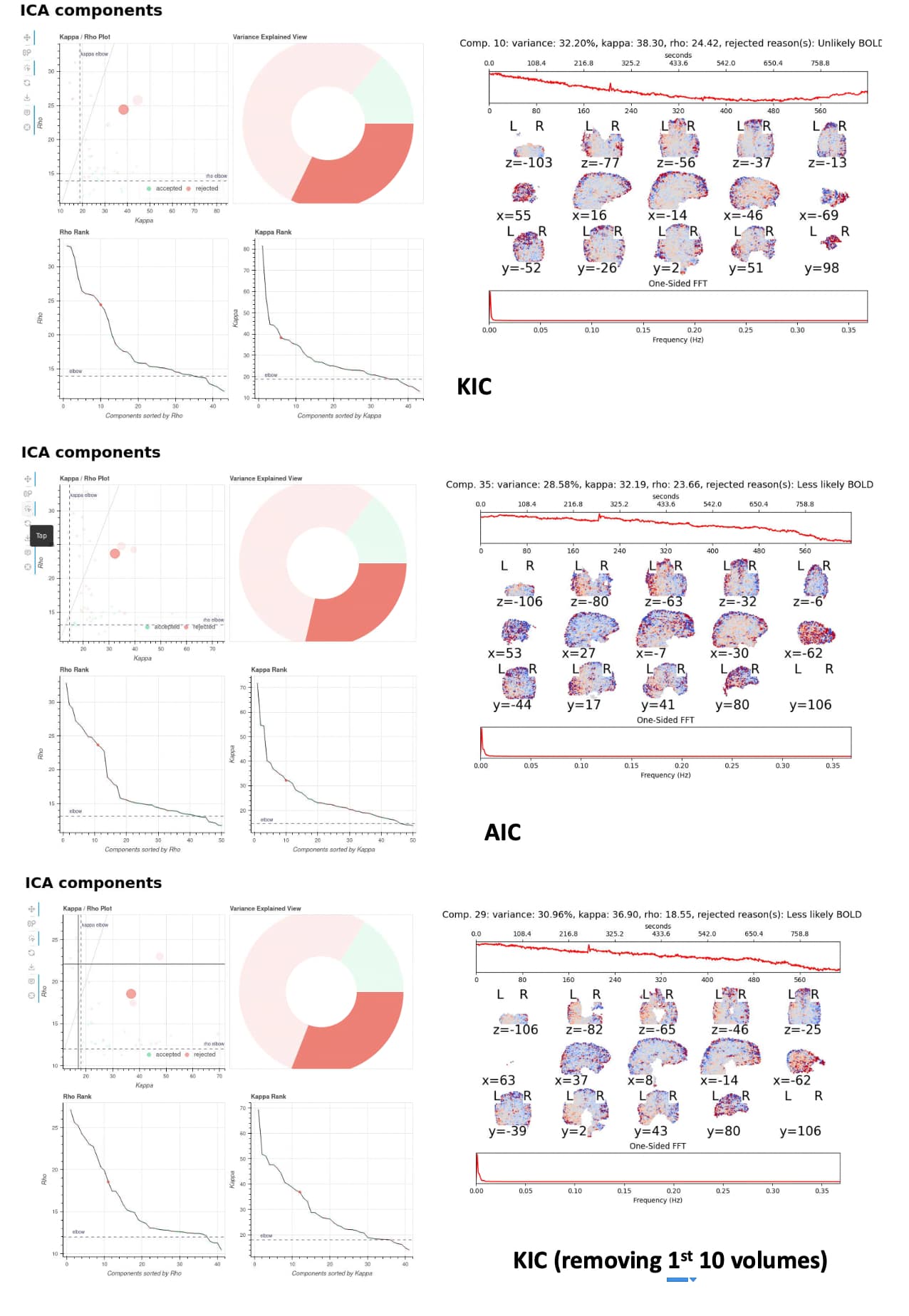
However I am stuck at the Tedana step where the output seems to be influenced by non-steady-state volumes. I tried removing dummy scans as detected by fMRIprep as well as manually removing the first 10 volumes from all echo and optimally combined scans to no avail. Trying AIC and KIC options also did not result in any changes (see the attached screenshot).
I have attached the fMRIprep and Tedana script used.
Non-steady state volumes definitely have an impact (see this discussion for a case where they were a major problem), but they would show up as large spikes at the beginning of the scan. The components you’re showing don’t have that pattern. Can you elaborate on why you are concerned?
By the way, in tedana’s newest release (25.0.1) we have added a --dummy-scans parameter that makes it easier to run tedana on fMRIPrep derivatives.
Thank you so much for your prompt reply, Taylor, and for pointing me to the discussion—it was really helpful!
I have a few follow-up questions, if you don’t mind:
Each participant has at least two runs per session, and we have two repeated scanning sessions. We’re planning to concatenate all runs within each session after denoising, with the goal of assessing the stability of subcortical signal across sessions and validating our scanning protocol.
For 640 volumes (TR = 1.355), we observe some variability in component classification between runs and sessions for the same participant—for example, 9–15 accepted components out of 15–20 total, 10–20 out of 35–40, and in some cases around 30 out of 50. Do these numbers seem reasonable to you? Would this variability affect the reliability of concatenated data across runs?
We’re planning to include global signal regression (GSR) in the denoising pipeline. Should GSR be applied during Tedana (using --gscontrol) or later in XCP-D?
The number of dummy scans detected by fMRIPrep varies from 0 to 2 across runs. Should I set --dummy-scans to 2 in Tedana, and subsequently --dummy-scans to 2 as well in XCP_D?
I think @handwerkerd is a better person to ask. I don’t have a good sense of how many components one should expect and what proportion should be accepted.
I am personally not a fan of GSR. If you have the time and interest, I’d recommend looking at rapidtide, which does a sort of dynamic global signal regression. If you still want to stick with GSR, you should know that tedana’s GS control methods (gsr and mir) are not the same as the popular GSR approach, so you should take a close look at the descriptions (see here and here) before applying them. You can grab the global signal regressor from your fMRIPrep derivatives if you want to use XCP-D and don’t want to try tedana’s global signal control methods.
I typically set it to “auto” to just rely on fMRIPrep’s dummy scan estimation. That will work in XCP-D, but for tedana you would need to determine the number of dummy scans from the fMRIPrep confounds separately for each run. One thing to note is that tedana will not add rows of zeros back into the mixing matrix/ICA confounds file to account for the dummy scans, so you’ll need to add them in yourself before running XCP-D.
Thank you so much for your prompt response as always Taylor!
Follow-up on point 3, as the number of dummy volumes differs between runs, i should manually remove the number of dummy volumes based on fMRIprep outlier columns from each echo file and run tedana without the –dummy scan flag then add back zero rows to the mixing matrix (corresponding to the number of dummy scan volumes) then run XCP_D with --dummy scan auto flag?
However, if I also trim the optimally combined scans, would this pipeline produce the same outcome:
Manually removing the number of dummy volumes based on fMRIprep outlier columns from each echo and optimally combined file then run tedana and XCP_D without the –-dummy scan flag and without adding back zero rows to the mixing matrix?
In regards to GSR, we are planning to start with GS + orthogonalized noise components as regressors at the XCP_D step before exploring rapidtide down the track. My understanding is that GS should be orthogonalized separately. Would I replace bad_timeseries from the sample code below with the GS column from fMRIprep to generate orthogonalized GS before combining with orthogonalized, rejected components generated from Tedana with --tedort flag for the custom confound file for XCP_D?
#Regress the good components out of the bad time series to get “pure evil” regressors
betas = np.linalg.lstsq(accepted_components, bad_timeseries, rcond=None)[0]
pred_bad_timeseries = np.dot(accepted_components, betas)
orth_bad_timeseries = bad_timeseries - pred_bad_timeseries
Thank you so much again for your time and invaluable guidance. Any clarification you can offer on these points would be greatly appreciated!
I’m not sure where you’re seeing influence by non-steady state scans. The initial screen shot shows a large slow linear drift. The spike on the first value in the line plot is the FFT, which means the rejected component has a large magnitude slow drift. That may or may not be a problem (probably not), but it’s not an issue because of non-steady state scans (unless I’m missing something)
For 640 volumes and TR=1.355, 15-20 components is definitely too low. 35-40 seems low for that many volumes, but it also depends on voxel size, smoothness, and the total number of voxels. Component estimation is still a step we’re trying to improve (I actually think this is an under-discussed issue with all fMRI ICA methods & not just tedana). For now, a practical option is to identify a number of components on the high end of “normal” estimates and provide that as a hard-coded value (i.e. --tedpca 50). Then also use --ica_method robustica That second option will run ICA multiple times to find a fewer number of stable components. Note: in tedana v25.0.1 we’ve added a warning message if ICA fails to converge on repeated iterations. If, for a run, it send it’s failed to converge more than 10 or 20% of the time, I’d recommend redoing that run with a slightly lower initial number of components.
I am also not a fan of GSR. There are enough studies that convincingly show it removes neural activity and is affected by factors like attention and arousal. That said, external regressors of any time can be removed within or outside of tedana. Running two linear regressions for denoising will affect the weights for each individual regressor, but the post regression denoised time series should be nearly identical. I’m fairly sure the GSR option in tedana just regresses out the global signal without orthogonalize (even if the rejected component time series are orthogonalized). Since I never use GSR, I’m not 100% sure about this, but I could dig into the code if you want a more definitive answer.
@tsalo is the better person to answer questions about dummy scans & fMRIPrep.
You’d need to remove the same rows from the fMRIPrep confounds file, but yes this should work.
You don’t want to orthogonalize non-ICA confounds based on ICA-confounds. I’d just leave the global signal regressor as is.
Tedana’s GSR approach creates a global signal spatial map and builds the time series from that. It then regresses out the “global signal” (not 100% sure it’s the same as standard global signal) from the optimally combined data and individual echoes before tedana runs PCA + ICA. It’s a weird method.