Hello everyone! Pardon my inexperience with programming, I’m sure this is a simple task.
I’m trying to pull unthresholded images from the term-based meta-analysis data published on neurosynth, but I’m having difficulties because it is deprecated. I have been slowly learning other options such as NiMARE, but it seems like there are a lot of different packages to learn.
I was wondering if anyone could point me in the direction of a package/repository that would allow me to either access these unthresholded images, or to generate new ones using the same process.
Again, apologies for the simplicity of the question, I haven’t found a good answer anywhere. Thanks.
I don’t believe the unthresholded maps are available in bulk anywhere, so I can see three possible solutions:
Go to each term’s page on Neurosynth and download the maps by hand.
Write a script to scrape the maps from the website. I wouldn’t recommend doing this, as the Neurosynth documentation explicitly warns that web scraping attempts will result in a permanent IP ban. See the Data section here for that warning.
Use NiMARE. I’ve drafted some code that should work, though it’ll take a while.
import nimare
# Download the Neurosynth data and convert to a NiMARE Dataset
nimare.extract.fetch_neurosynth("data/", unpack=True)
ns_dset = nimare.io.convert_neurosynth_to_dataset(
"data/database.txt",
"data/features.txt",
)
# Initialize a meta-analysis
meta = nimare.meta.cbma.mkda.MKDAChi2()
# Get the full list of Neurosynth labels
# You may want to find a way to reduce this list,
# since it will include a bunch of "terms" that are not useful, like "001"
terms = ns_dset.get_labels()
all_ids = ns_dset.ids
for term in terms:
# Remember to use a threshold of 0.001 to get associated studies,
# since NiMARE's default is 0.5.
term_ids = ns_dset.get_studies_by_label(term, label_threshold=0.001)
notterm_ids = sorted(list(set(all_ids) - set(term_ids)))
term_dset = ns_dset.slice(term_ids)
notterm_dset = ns_dset.slice(notterm_ids)
# Run the meta-analysis.
# No multiple comparisons correction since you want the unthreshold maps.
results = meta.fit(term_dset, notterm_dset)
# Save the maps to files
term_name = term.split("__")[1]
results.save_maps(out_dir="meta-analyses/", prefix=term_name)
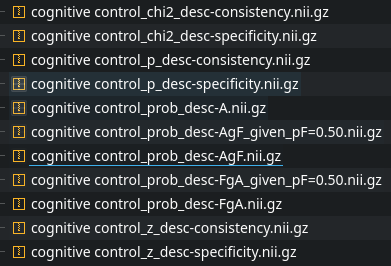
@tsalo : I followed your code for one single term. Now I would like to obtain only the unthresholded association map. I noticed that save_maps() outputs eleven maps but couldn’t find any documentation which one is which. Could you help here?
That’s unfortunate. The documentation must be lacking. I’m not sure what you mean by the unthresholded association map though. The “association test” from Neurosynth is equivalent to the “specificity test” in NiMARE, but it depends on what statistic/value you want in the map. “prob” is the posterior probability, “z” is the z-statistic, “p” is the p-value, and “chi2” is the chi-squared statistic.
BTW I think your question is distinct enough from the original post that it merits its own topic, but I don’t have the ability to break your post off into a new topic.
Yes, I would be interested in obtaining the association map from Neurosynth (only that I need the unthresholded map). So basically following the user-flow from this .gif:
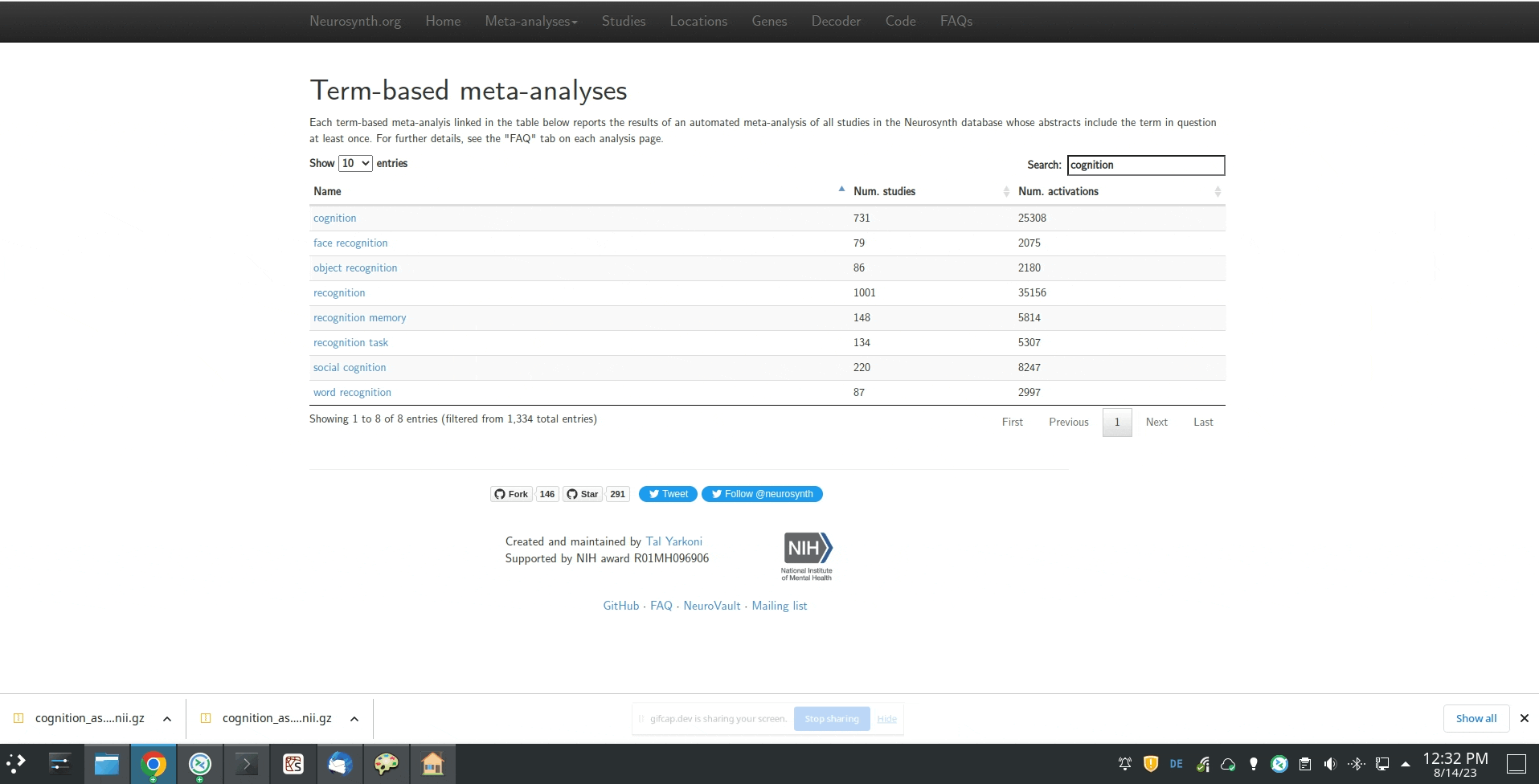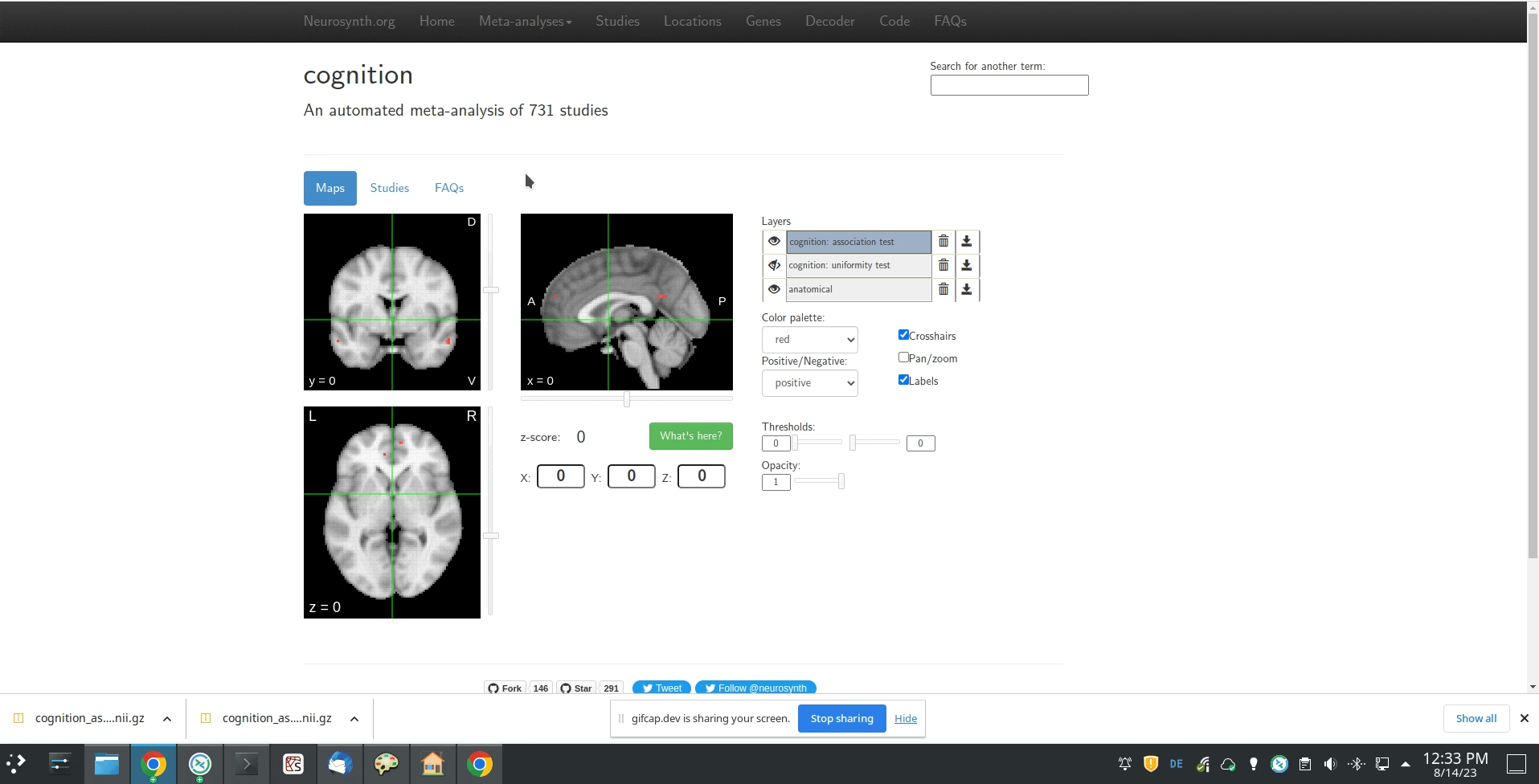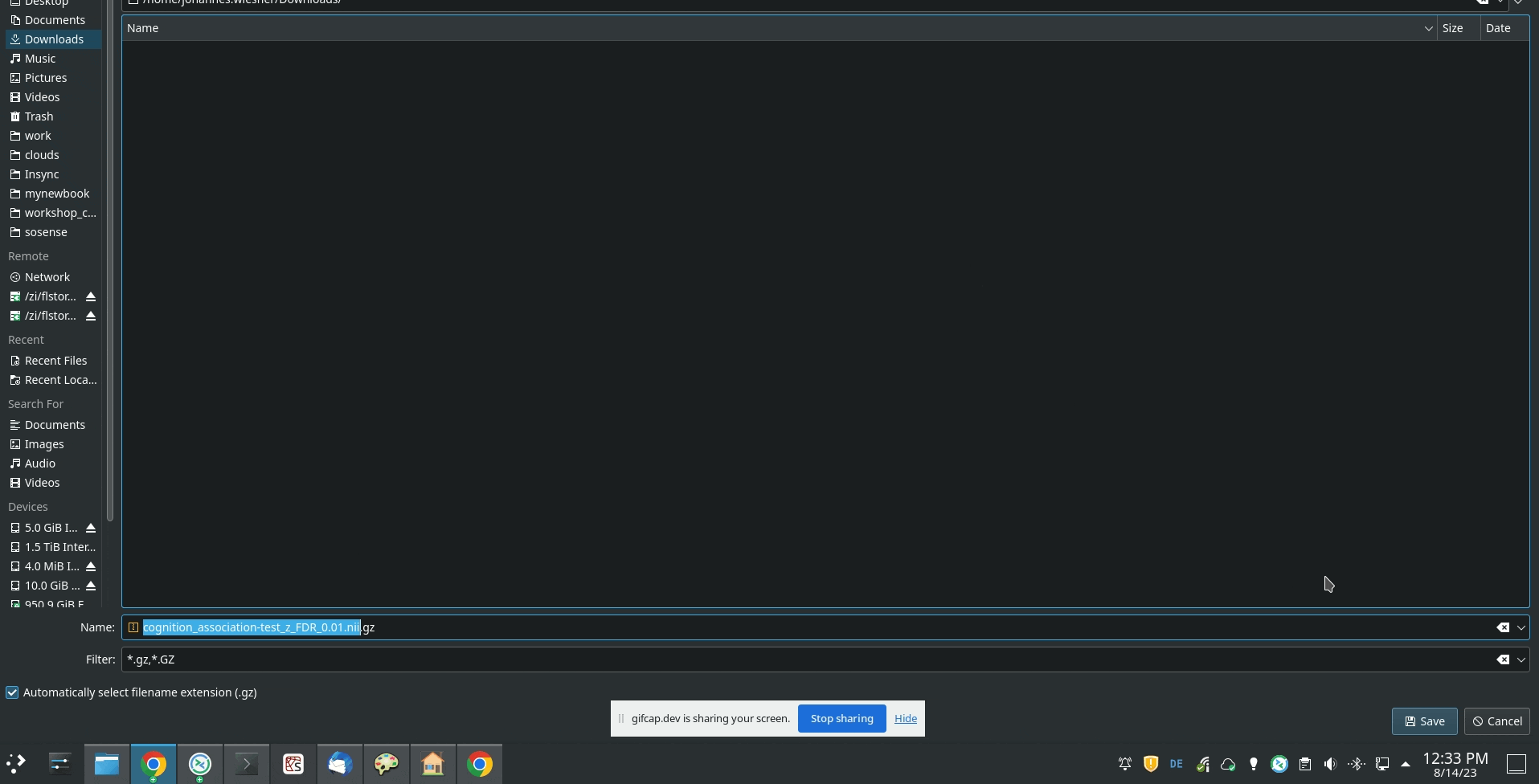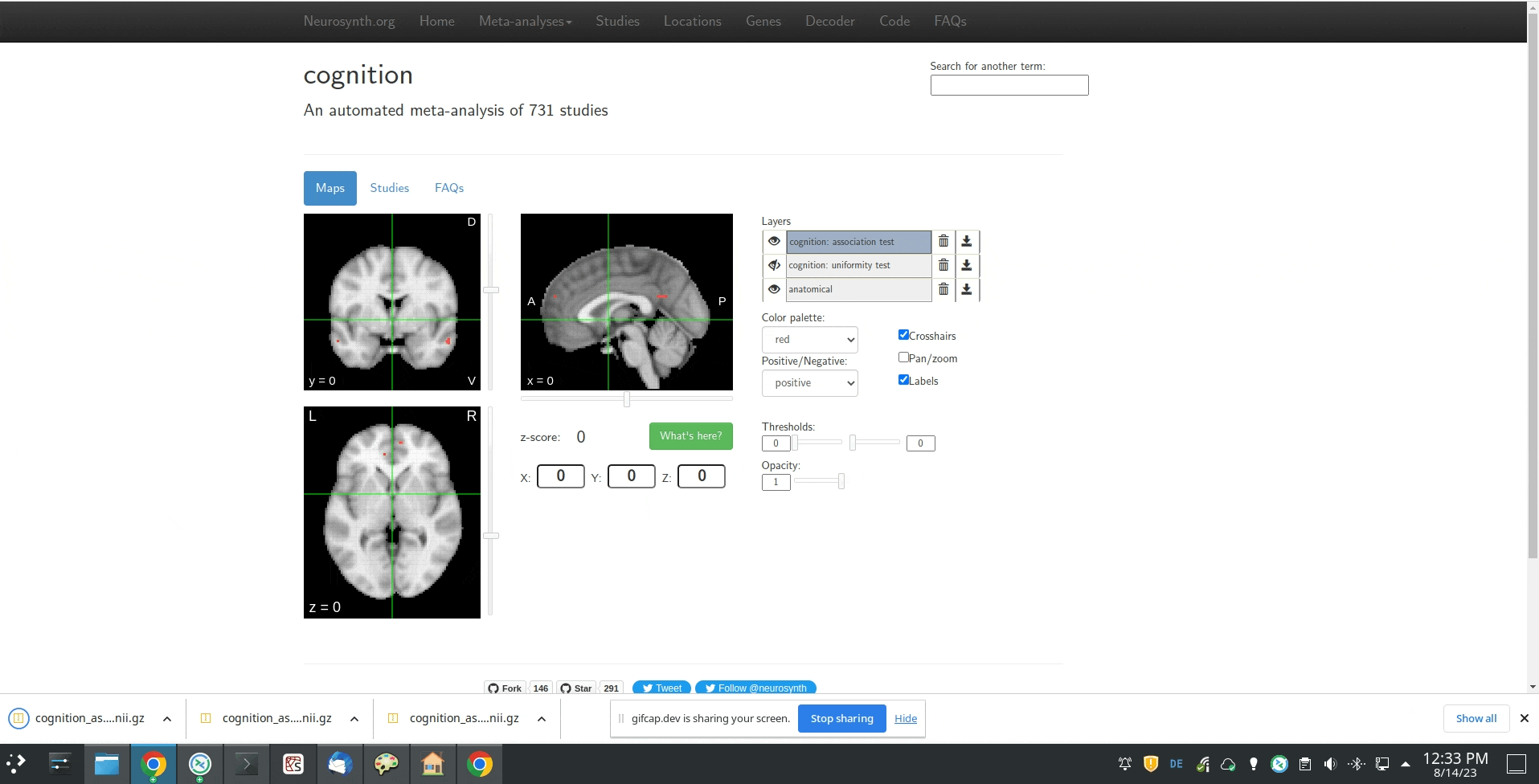
I already thought that the “specificity” test will be the one that I need, and I guess the z-map will correspond to the image that you would get when using the GUI from neurosynth. Will probably open another slightly different issue on this concerning meta-analytic association maps today Thanks for the help!
Yes, it looks like the z map is the one you want, but, based on the filename, it also looks like Neurosynth ran an FDR correction step with an alpha value of 0.01 as well. You should be able to do this in NiMARE with FDRCorrector, using the method='indep' and alpha=0.01.
I’m not sure you need to skip the FDR correction. The corrector will modify the z values, but it shouldn’t threshold them. That said, it’s entirely up to you.