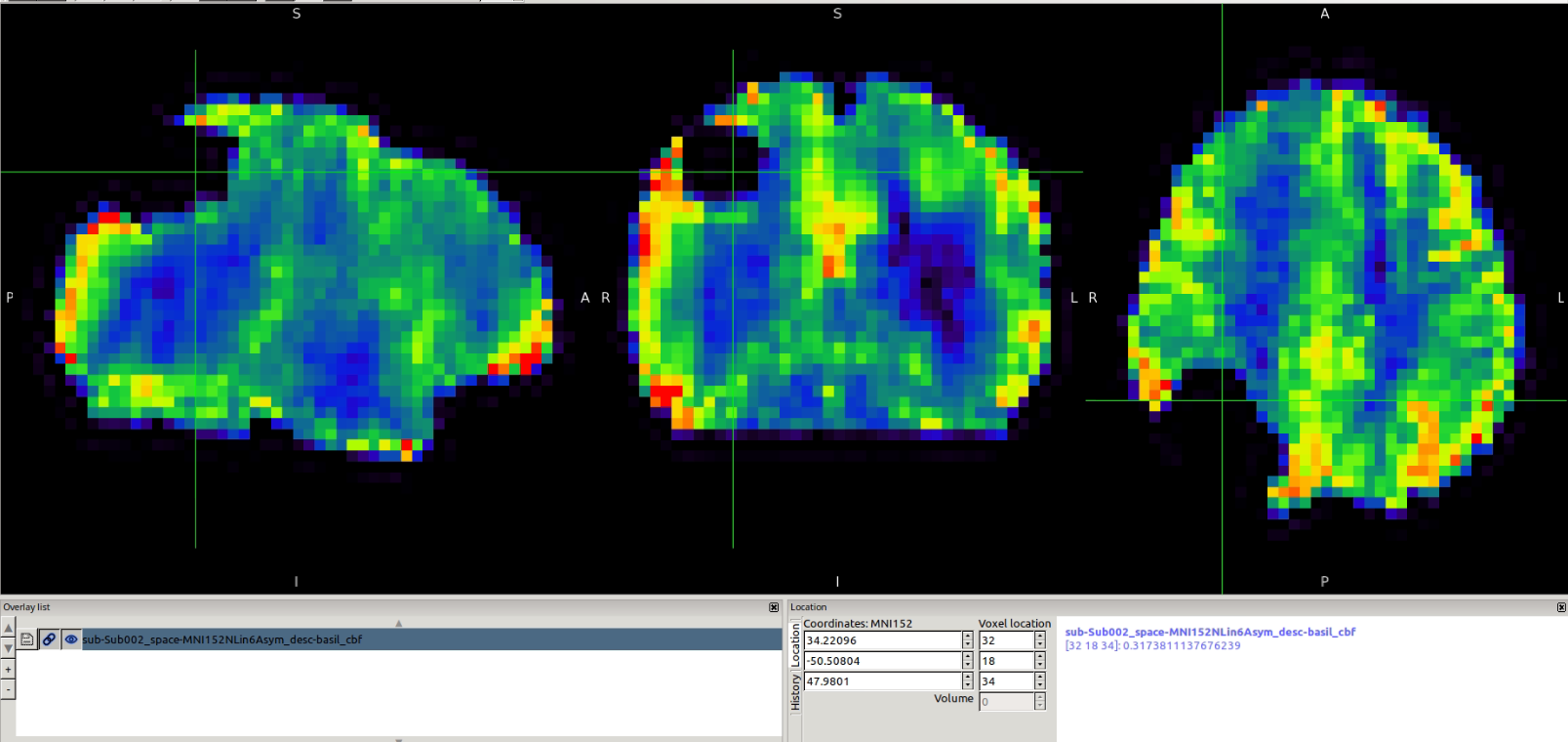
I’m running ASLPrep on my multi-delay pCASL data, but I’m encountering a problem with the CBF quantification (both with the standard model and with BASIL). In the resulting CBF maps, there are regions of the brain that appear to be “cut out,” resulting in patchy areas or “holes” in the quantification.
Additionally, when specifying: --output-spaces “MNI152NLin6Asym:res-1 MNI152NLin2009cAsym:res-1 MNI152NLin6Asym:res-native MNI152NLin2009cAsym:res-native” the results (CBF, ATT, ecc…) are actually only saved in native resolution (3.5x3.5x3.5 mm), not at 1 mm as also requested.
I’m not using distortion correction because the fieldmap-less approach (with T1w) gave me even larger missing regions. We also tried:
running without forcing --asl2anat-init t2w
using --asl2anat-dof 12
but the results did not improve (sometimes they were even worse).
The data are organized according to the BIDS standard, and the ASL mask itself (red contour in the image above) does not appear to have that gap — it only shows up in the CBF quantification.
Do you have any idea where the problems could come from, and how we could resolve the?
This is one of the most common issues users have with ASLPrep. I am currently investigating a possible cause, which is that N4 bias correction may be introducing odd patterns in data that are already normalized. Can you share the ImageType field from your ASL, M0, and sbref files’ JSONs?
I don’t know what might be causing the issue with the output spaces, but I’d recommend opening a separate topic for that.
thanks a lot for your reply!
For my ASL and M0 (same acquisition, I only separated M0 afterwards) the field is “ImageType”: [“ORIGINAL”, “PRIMARY”, “ASL”, “NONE”, “ND”, “MOSAIC”]
This field is not included in the JSON of my BIDS dataset, since I didn’t found it as required/recommended by the specification. Do you think it should be explicitly added in order for ASLPrep to handle the data properly?
There is no sbref for our pCASL acquisition, though.
I’m not sure if this could be related to the issue, but I re-ran the same command removing the native resolution outputs, keeping only:
If the problem is indeed N4 bias correction (although your data don’t seem to be prescan normalized, so maybe it’s not the problem), then the artifact seems to occur somewhat randomly, so it might just be a matter of good luck on your second run.
Any chance you could share this particular run directly with me so I can try to reproduce the error on my cluster? I would need everything ASLPrep is using (T1w, ASL, M0, any field maps). I am very busy with XCP-D right now but I think I can look at this issue (and a related one from another user) at the beginning of next week.
That sounds good, thank you for checking this out! I can share the data directly, sending you the full BIDS folder exactly as I pass it to ASLPrep.
Do you want me to include the bash script I use to run ASLPrep on my server, and/or some extra details about the ASL sequence? What’s the best way for me to share all this with you?
Anyway, some extra tests show that the T2w asl2anat-init works better. In fact, the .html report says that the bbregister refinement is always rejected. If I’m right, this means that the initial affine transform (done with the T2w) is more reliable in those cases. However, this doesn’t happen all the time, but it does happen for some subjects and some acqusition sites.
Thanks again, no worries, a follow-up next week (or at a time that works for you) works perfectly for me.
I have fixed the output space issue, and I think the problem with the masking should be largely resolved in 25.0.0 (released earlier today) with the new --disable-n4 parameter.
I will continue to work on improving the masking procedure by testing out SynthStrip and brainchop over the next couple of weeks, in case the new version doesn’t work well.