@mitchem890 Which IU resource are you running this on? I believe “mem” is ignored on carbonate. I have to set vmem instead. Without setting vmem, carbonate defaults it to 16gb.
@effigies I just disabled the plugin parameters (to keep things simple). Here is the commands that I am running now - and the error message.
[stderr log]
++ singularity run --cleanenv docker://poldracklab/fmriprep:1.2.6-1 --notrack --resource-monitor --skip_bids_validation --stop-on-first-crash --mem-mb 30000 --omp-nthreads 8 --output-space fsaverage5 fsnative T1w template --template-resampling-grid=2mm --force-bbr --force-syn --skull-strip-template=NKI --fs-license-file=/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/.license.txt --work-dir=/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/ --participant_label=sub-TTTEMPSUB /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripinput/ /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripout/ participant
e[33mWARNING: Warning reading tar header: Ignoring malformed pax extended attribute
e[0me[33mWARNING: Warning reading tar header: Ignoring malformed pax extended attribute
e[0me[91mERROR : Could not write to /N/soft/rhel7/singularity/2.6.1/var/singularity/mnt/final/etc/localtime: Too many levels of symbolic links
e[0m/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/site-packages/nilearn/datasets/neurovault.py:16: DeprecationWarning: Using or importing the ABCs from ‘collections’ instead of from ‘collections.abc’ is deprecated, and in 3.8 it will stop working
from collections import Container
/usr/local/miniconda/lib/python3.7/site-packages/skimage/init.py:80: ResourceWarning: unclosed file <_io.TextIOWrapper name=’/usr/local/miniconda/lib/python3.7/site-packages/pytest.py’ mode=‘r’ encoding=‘utf-8’>
imp.find_module(‘pytest’)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/site-packages/networkx/classes/reportviews.py:95: DeprecationWarning: Using or importing the ABCs from ‘collections’ instead of from ‘collections.abc’ is deprecated, and in 3.8 it will stop working
from collections import Mapping, Set, Iterable
/usr/local/miniconda/lib/python3.7/site-packages/bids/layout/bids_layout.py:121: ResourceWarning: unclosed file <_io.TextIOWrapper name=’/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripinput/dataset_description.json’ mode=‘r’ encoding=‘UTF-8’>
self.description = json.load(open(target, ‘r’))
/usr/local/miniconda/lib/python3.7/site-packages/grabbit/core.py:436: ResourceWarning: unclosed file <_io.TextIOWrapper name=’/usr/local/miniconda/lib/python3.7/site-packages/bids/layout/config/bids.json’ mode=‘r’ encoding=‘UTF-8’>
domain = json.load(open(domain, ‘r’))
/usr/local/miniconda/lib/python3.7/site-packages/bids/layout/bids_layout.py:208: ResourceWarning: unclosed file <_io.TextIOWrapper name=’/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripinput/sub-TTTEMPSUB/ses-SSSES/func/sub-TTTEMPSUB_ses-SSSES_task-rest_bold.json’ mode=‘r’ encoding=‘utf-8’>
encoding=‘utf-8’))
Captured warning (<class ‘ImportWarning’>): can’t resolve package from spec or package, falling back on name and path
Captured warning (<class ‘ImportWarning’>): can’t resolve package from spec or package, falling back on name and path
Captured warning (<class ‘ImportWarning’>): can’t resolve package from spec or package, falling back on name and path
Captured warning (<class ‘ImportWarning’>): can’t resolve package from spec or package, falling back on name and path
Captured warning (<class ‘DeprecationWarning’>): Using or importing the ABCs from ‘collections’ instead of from ‘collections.abc’ is deprecated, and in 3.8 it will stop working
Captured warning (<class ‘ResourceWarning’>): unclosed file <_io.TextIOWrapper name=’/usr/local/miniconda/lib/python3.7/site-packages/pytest.py’ mode=‘r’ encoding=‘utf-8’>
Captured warning (<class ‘ImportWarning’>): can’t resolve package from spec or package, falling back on name and path
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
/usr/local/miniconda/lib/python3.7/site-packages/nilearn/datasets/neurovault.py:16: DeprecationWarning: Using or importing the ABCs from ‘collections’ instead of from ‘collections.abc’ is deprecated, and in 3.8 it will stop working
from collections import Container
/usr/local/miniconda/lib/python3.7/site-packages/skimage/init.py:80: ResourceWarning: unclosed file <_io.TextIOWrapper name=’/usr/local/miniconda/lib/python3.7/site-packages/pytest.py’ mode=‘r’ encoding=‘utf-8’>
imp.find_module(‘pytest’)
/usr/local/miniconda/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can’t resolve package from spec or package, falling back on name and path
return f(*args, **kwds)
Captured warning (<class ‘PendingDeprecationWarning’>): the matrix subclass is not the recommended way to represent matrices or deal with linear algebra (see https://docs.scipy.org/doc/numpy/user/numpy-for-matlab-users.html). Please adjust your code to use regular ndarray.
Captured warning (<class ‘PendingDeprecationWarning’>): the matrix subclass is not the recommended way to represent matrices or deal with linear algebra (see https://docs.scipy.org/doc/numpy/user/numpy-for-matlab-users.html). Please adjust your code to use regular ndarray.
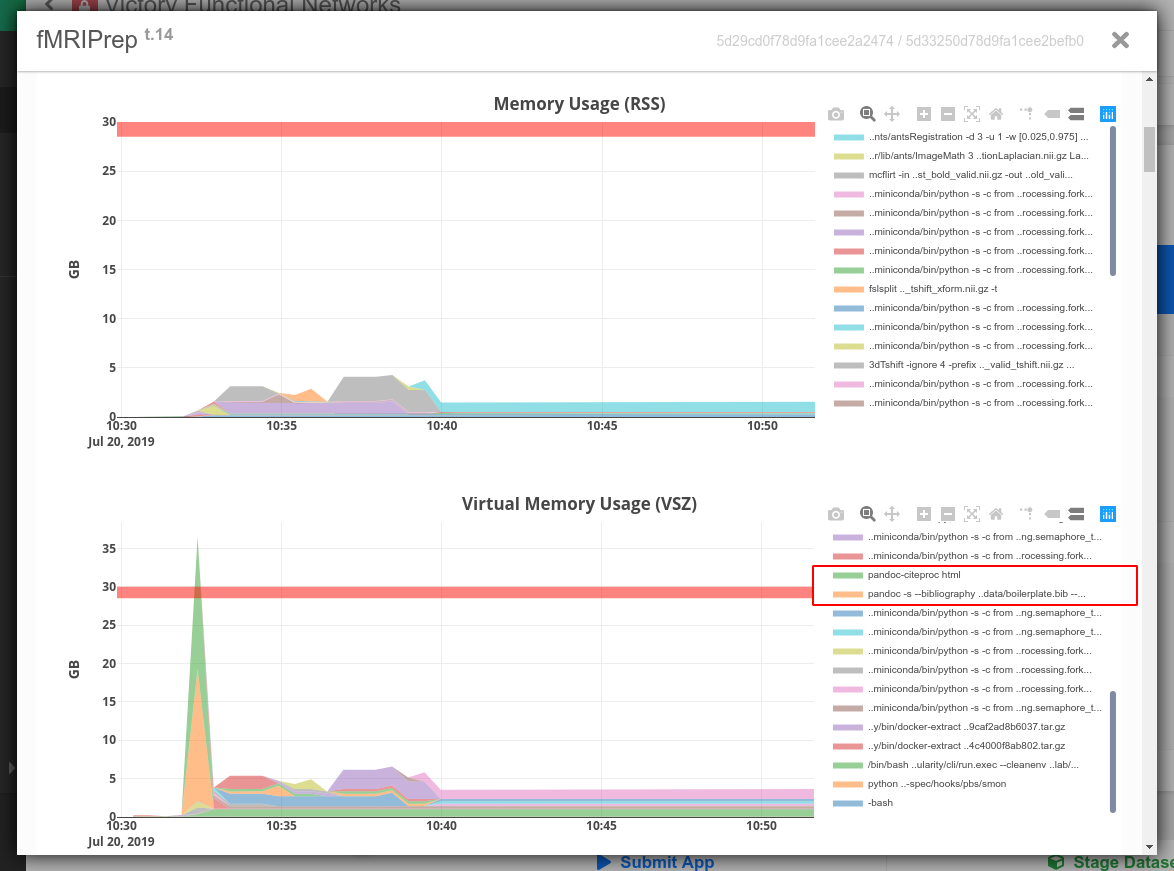
=>> PBS: job killed: vmem 32281870336 exceeded limit 32212254720
[stdout - last few lines]
…
190719-08:21:38,185 nipype.workflow INFO:
[Node] Finished “fmriprep_wf.single_subject_TTTEMPSUB_wf.func_preproc_ses_SSSES_task_rest_wf.bold_t1_trans_wf.bold_reference_wf.enhance_and_skullstrip_bold_wf.fixhdr_skullstrip2”.
190719-08:21:40,103 nipype.workflow INFO:
[Node] Setting-up “fmriprep_wf.single_subject_TTTEMPSUB_wf.func_preproc_ses_SSSES_task_rest_wf.bold_t1_trans_wf.bold_reference_wf.enhance_and_skullstrip_bold_wf.combine_masks” in “/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/combine_masks”.
190719-08:21:40,124 nipype.workflow INFO:
[Node] Running “combine_masks” (“nipype.interfaces.fsl.maths.BinaryMaths”), a CommandLine Interface with command:
fslmaths /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/skullstrip_first_pass/ref_image_corrected_brain_mask.nii.gz -mul /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/fixhdr_skullstrip2/uni_xform_mask_xform.nii.gz /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/combine_masks/ref_image_corrected_brain_mask_maths.nii.gz
190719-08:21:40,459 nipype.workflow INFO:
[Node] Finished “fmriprep_wf.single_subject_TTTEMPSUB_wf.func_preproc_ses_SSSES_task_rest_wf.bold_t1_trans_wf.bold_reference_wf.enhance_and_skullstrip_bold_wf.combine_masks”.
190719-08:21:42,103 nipype.workflow INFO:
[Node] Setting-up “fmriprep_wf.single_subject_TTTEMPSUB_wf.func_preproc_ses_SSSES_task_rest_wf.bold_t1_trans_wf.bold_reference_wf.enhance_and_skullstrip_bold_wf.apply_mask” in “/N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/apply_mask”.
190719-08:21:42,121 nipype.workflow INFO:
[Node] Running “apply_mask” (“nipype.interfaces.fsl.maths.ApplyMask”), a CommandLine Interface with command:
fslmaths /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/fixhdr_unifize/uni_xform.nii.gz -mas /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/combine_masks/ref_image_corrected_brain_mask_maths.nii.gz /N/dc2/scratch/brlife/carbonate-workflows/5d29cd0f78d9fa1cee2a2474/5d31341178d9fa1cee2b9eeb/fmripworkdir/fmriprep_wf/single_subject_TTTEMPSUB_wf/func_preproc_ses_SSSES_task_rest_wf/bold_t1_trans_wf/bold_reference_wf/enhance_and_skullstrip_bold_wf/apply_mask/uni_xform_masked.nii.gz
190719-08:21:42,376 nipype.workflow INFO:
[Node] Finished “fmriprep_wf.single_subject_TTTEMPSUB_wf.func_preproc_ses_SSSES_task_rest_wf.bold_t1_trans_wf.bold_reference_wf.enhance_and_skullstrip_bold_wf.apply_mask”
As you can see, fmriprep seems to be (at least temporarily) exceeding the --mem-mb. Strangely, if I just rerun the job, the job sometimes succeeds. I believe this is because the batch scheduler isn’t quick enough to discover that the fmriprep is exceeding the requested memory size, and/or fmriprep only exceeds max memory size - occasionally… I am not sure which is which, but either way, fmriprep shouldn’t exceed the max memory. Have you run a detailed memory footprint analysis with fmriprep?