Hello, everyone!
I’m trying to run probtrackx2 gpu which supports CUDA version 7.5, 8.0, 9.0~9.2, 10.0~10.2 (reference is https://spmic-uon.github.io/conilab/software/probtrackx), but my CUDA version is 11.6.
So I installed a docker image that is nvidia/CUDA-Ubuntu-18.04-runfile and ran probtrackx2 gpu.
Docker command that I used is
sudo docker run --gpus all -itd -m 500G --name CUDA10.2 -v /local_raid1/03_user/sunghyoung/01_project/03_Fdt/:/data nvidia/cuda:10.2-runtime-ubuntu18.04 bash
and probtrackx2 command is
/usr/local/fsl/bin/probtrackx2_gpu \
> --network \
> -x /data/test_5000samples_gpu/masks.txt \
> -l -f \
> --onewaycondition \
> --pd \
> -c 0.2 -S 2000 \
> --steplength=0.5 \
> -P 5000 \
> --fibthresh=0.01 \
> --distthresh=0.0 \
> --sampvox=0.5 \
> --xfm=/data/roi2diff.mat \
> --forcedir --opd \
> -s /data/100408.bedpostX/merged \
> -m /data/100408.bedpostX/nodif_brain_mask \
> --dir=/data/test_5000samples_gpu
However, log said
...................Allocated GPU 0...................
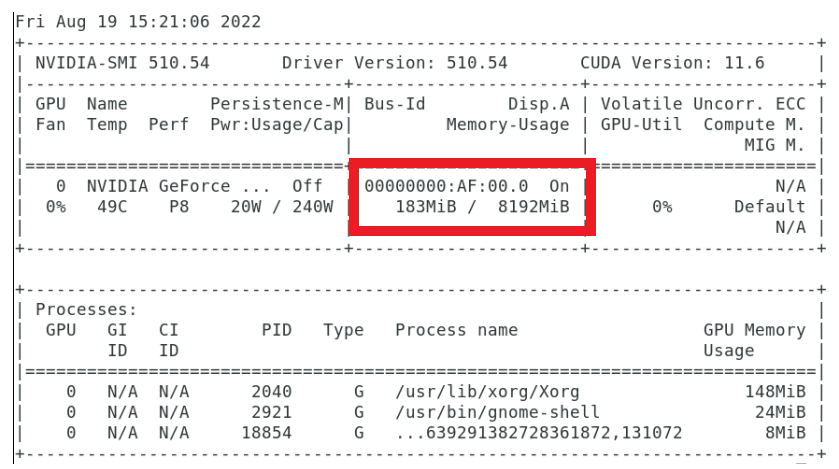
Device memory available (MB): 7645 ---- Total device memory(MB): 7981
Memory required for allocating data (MB): 13467
Not enough Memory available on device. Exiting ...
terminate called without an active exception
Aborted (core dumped)
But my memory is much more than 13467 MB.
top - 05:20:32 up 97 days, 3:23, 0 users, load average: 0.43, 0.42, 0.60
Tasks: 2 total, 1 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.6 us, 0.1 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 52797584+total, 40118704 free, 12870964 used, 47498617+buff/cache
KiB Swap: 31999996 total, 30378492 free, 1621504 used. 51103539+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
643 root 20 0 36632 3188 2744 R 0.3 0.0 0:00.01 top
1 root 20 0 18520 3548 3084 S 0.0 0.0 0:00.09 bash
Any response can be helpful!
Thank you.