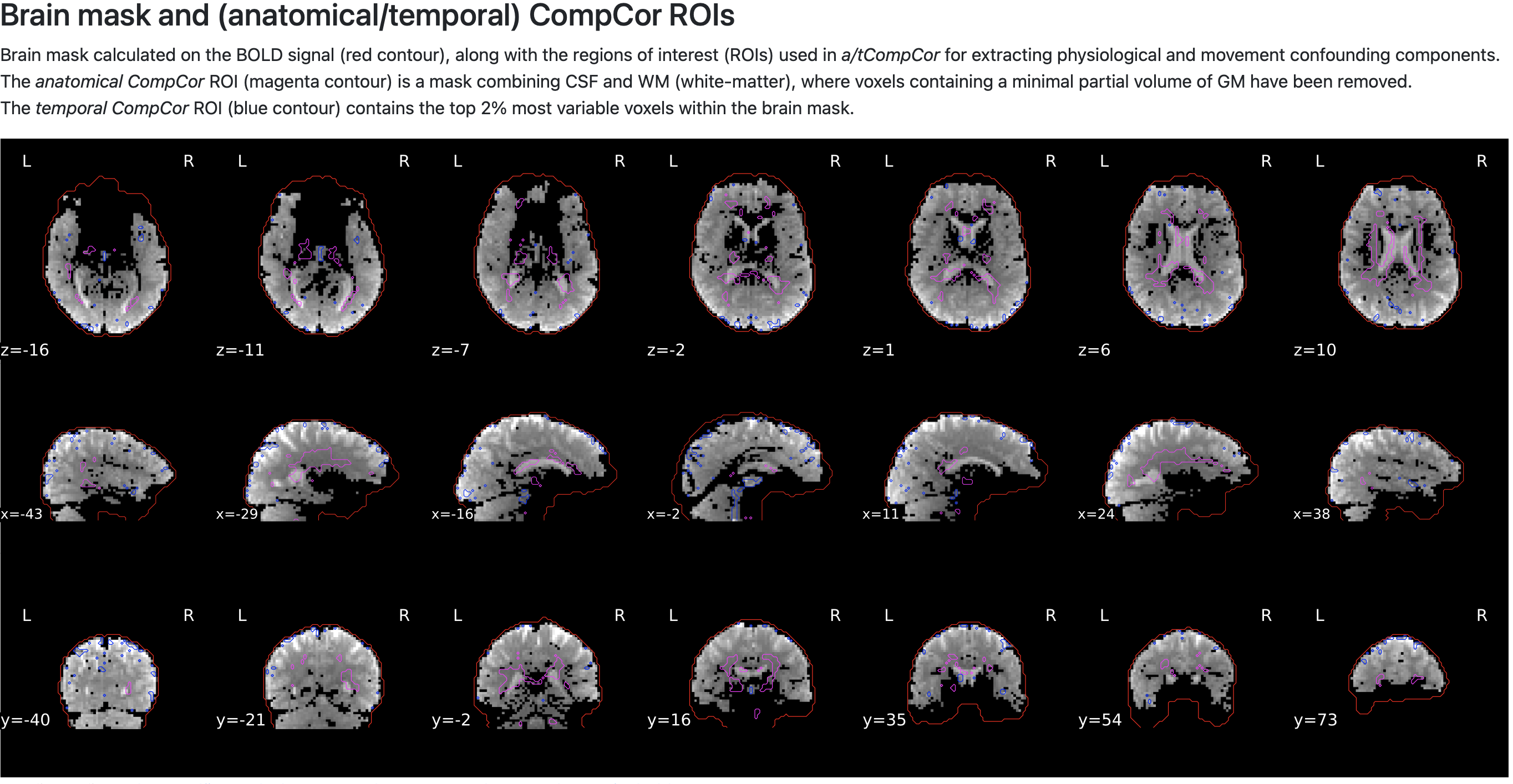
I am converting the data with HeuDiConv and then processing with fmriprep (example command below), and I’m concerned that some of the data are negative. These negative values lead to masking issues in FSL (shown below).
The individual echoes look fine, so I’m assuming the negative values are due to tedana (assuming that is how fmriprep is making the optimal combination image). I’m not sure if screwed something up with the acquisition, but in case it’s helpful for troubleshooting, the data can be found here:
Regarding the acquisition, I did notice that some examples had the reconstruction set to “Magn./Phase” (OSF | CMRR_MB-3_IP-2_ME-4_Rec-MagPhase_TR-1500.pdf), but I only had “Magn” for this test. I’m not sure where the phase images would enter into the analyses.
I’m not an fmriprep user, so I can’t help with that part, but I have some thoughts from the tedana perspective. First, you are correct that, for tedana, you should not be giving it the phase volumes. Make sure you are only giving it the magnitude scans in the correct order. I’m stressing this because phase values can be negative. Tedana can potentially create a more agressive mask than fmriprep, but I don’t see how it would create negative values. If fmriprep does any type of magnitude scaling (i.e. dividing time series by their mean or changing time series to percent change from the mean) make sure that is NOT done before the tedana step. That will definitely cause problems.
As I said, tedana does its own masking. Unlike fmriprep, tedana wants to make sure there are good values in all echoes before calculating estimates of BOLD vs non-BOLD weighted responses. Until recently, if there was not good signal magnitudes for at least 3 echos in a voxel, the voxel was masked. Later echoes have more drop out and fewer good voxels in the regions visible in your images. We received complaints that this was resulting in overly aggressive masking so we adjusted the thresholding so that the optimal combination and eventually denoised data will include a voxel with at least one good echo, but the denoising algorithm would only run on voxels with at least three good echoes. See [ENH] Use different masking thresholds for denoising and classification by tsalo · Pull Request #736 · ME-ICA/tedana · GitHub for more details.
This change is in version 0.0.11 of tedana (release last September). If you are running tedana v 0.0.10, then switching to the newer version might solve this issue.
Let me know if you were not on v0.0.11 and changing to that solves this issue. If not, I may try to pull in some of the tedana+fmriprep users to help.
I am only collecting the magnitude images and using those for analyses. Should I also collect the phase images? I am not sure where/how those would enter into the analyses, but I saw that a few folks also reconstruct those images. For reference, I generally also collect a standard GRE fmap and use that to help with registration (though I didn’t collect that here).
There are theoretical uses for the phase data (e.g., phase regression, dynamic distortion correction, improved T2*/S0 estimation), but I don’t think there are any established tools that will work with complex-valued, multi-echo data around yet. We’ve had plans to implement a T2*/S0 estimation approach using complex-valued data for a while now, but we haven’t made much progress on it. The phase images are definitely not something you need to retain.
To build off of what Dan said, for optimal combination there’s really no way for negative values to appear unless fMRIPrep is doing some rescaling that slipped past those of us who have helped out with its multi-echo workflows. This is one thing we’ve always tried to keep an eye out for.
tedana optimally combines multi-echo data with a weighted average, so there is no way for it to produce values outside of the range of the original echo-wise values (unlike with an interpolation, for example). Therefore, as long as all of the echo-wise values going into the optimal combination are greater than zero, there should be no negative values in the combined data.
Is there any way you could share a few of the fMRIPrep derivatives? Things like the workflow log, the optcom data with the negative values, and possibly the echo-wise data extracted from the working directory per FAQ — tedana 26.0.0 documentation (assuming you still have the working directory on your machine)?
I’m not sure if it will completely solve this problem, but switching to version 0.0.11 will definitely result in a lot fewer masked voxels, and is a really good thing to try next. Specifically for your 4 echo data, I see that your last echo has a TE of 63ms. You’ll get a lot of drop out at that point. In v0.0.9, those voxels may have been masked even if earlier echoes had good signal. They should mostly remain in v0.0.11.
We’ve also added a lot of features and fixed several bugs since v0.0.9.
Thanks, Dan and Taylor! It sounds like the problem could go away once fmriprep starts using the latest version of tedana. As far as I can tell, the latest version of tedana is not in either of the 21.0.0 series release candidates right now (https://github.com/nipreps/fmriprep/releases). I’d be happy to post an issue there and link back to this thread since it is starting to look more like an issue with fmriprep.
@tsalo – Here’s a link to the fmriprep work directory (scratch):
And here’s a link to the fmriprep output directory:
Good to know about the phase images. We’re about to start a 5-year scanning project, so it sounds like I should collect them since they’re free and could be quite valuable later…
Hi @dvsmith, I’m pulling down your dataset and run it through the latest version - we are making important changes to the ME pipeline with the upcoming 21.0 series. It will also allow us to bump tedana to 0.0.11 more safely. Will let you all know tomorrow.
Thanks very very much for the reporting and for the data!
It indeed looks like the preprocessed echoes have negative values in the background, mostly. The only processing that happened here is slice-timing correction (with AFNI) and head motion correction (estimated with FSL, interpolated with ANTs). I’d say the latter is the source of these values.
We should probably threshold after that, before writing out the echoes. cc @effigies
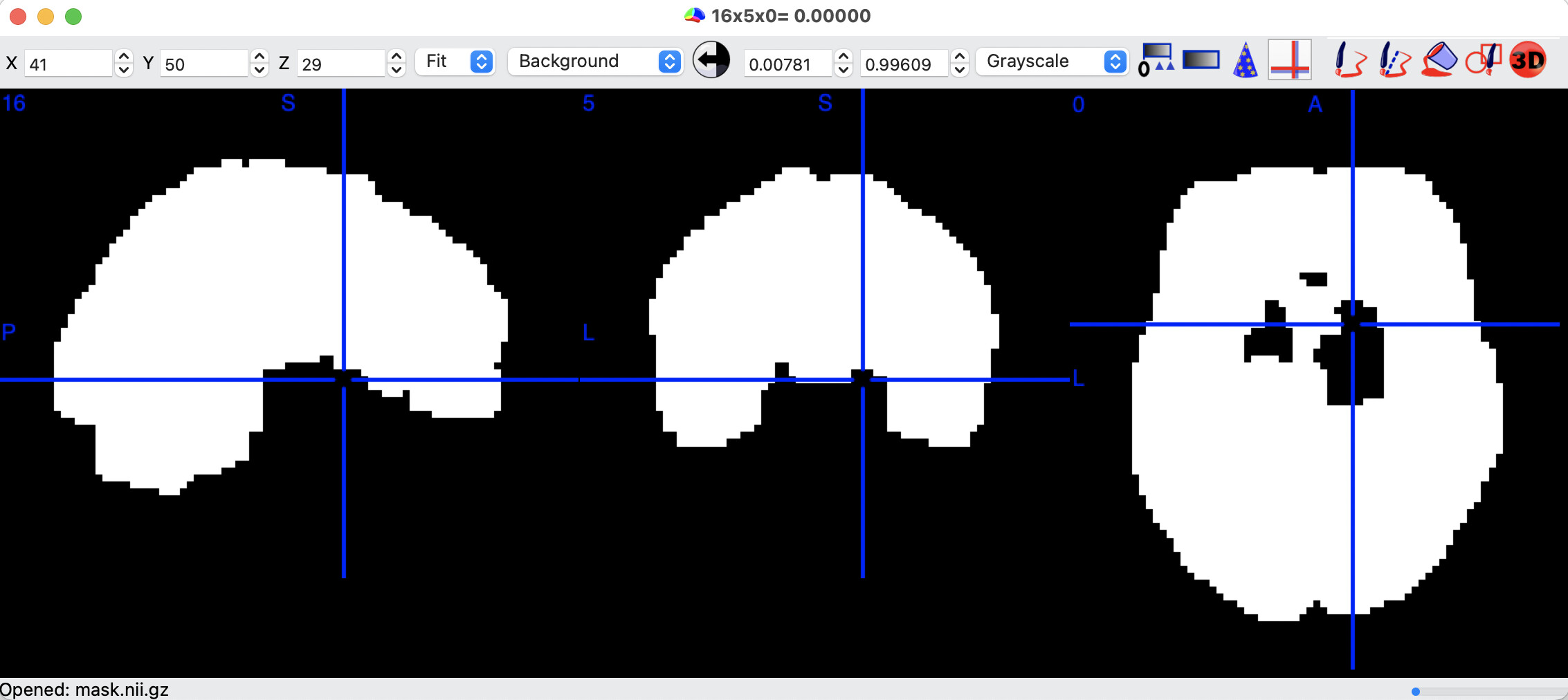
Thanks for checking it out! I think there are also quite a few negative voxels in the striatum, which is a region I definitely want to get in this project! If it’s helpful, I only noticed the negative values in the ME data, so perhaps tedana is also playing a role in the problem. Please let me know if I can help test any beta solutions!
We collected some new multi-echo data and the problem replicates with 20.2.6. I just tried the latest release candidate, but I may have an encountered a bug, which I just posted as an issue on the fmriprep GitHub page (https://github.com/nipreps/fmriprep/issues/2644).
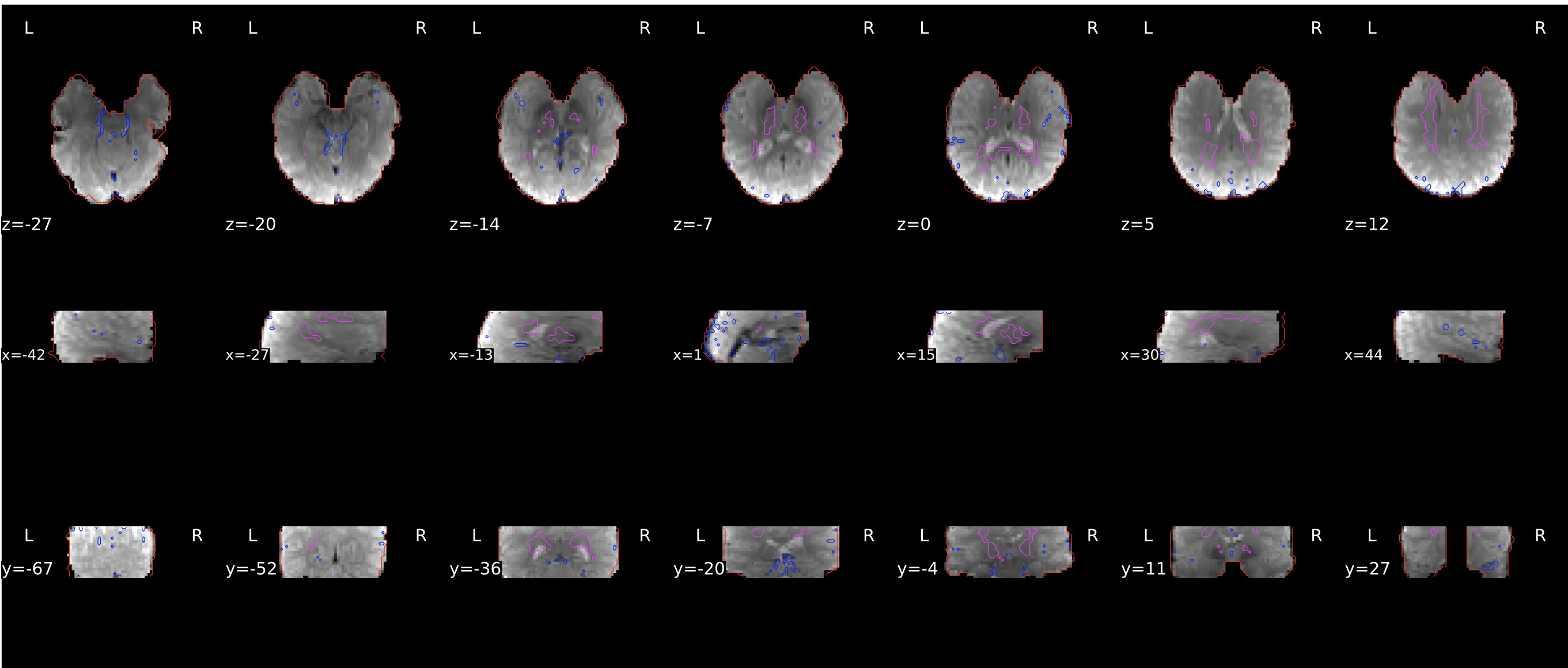
I just re-ran with the the latest version of fmriprep (21.0.0) it looks like the negative voxels are no longer a problem, but the masking may still be a little aggressive on one of the scans. See attached and note that this scan did not have whole brain coverage. It looks like the frontal lobe gets masked out.
I think the fix for this is going to be to let users pass in pre-determined BOLD masks. We’re working on something similar for nibabies, so hopefully we’ll have that early next year.
Sounds good, thanks! This one acquisition has limited slice coverage and it seems to be the only one with this specific (and new) masking issue.
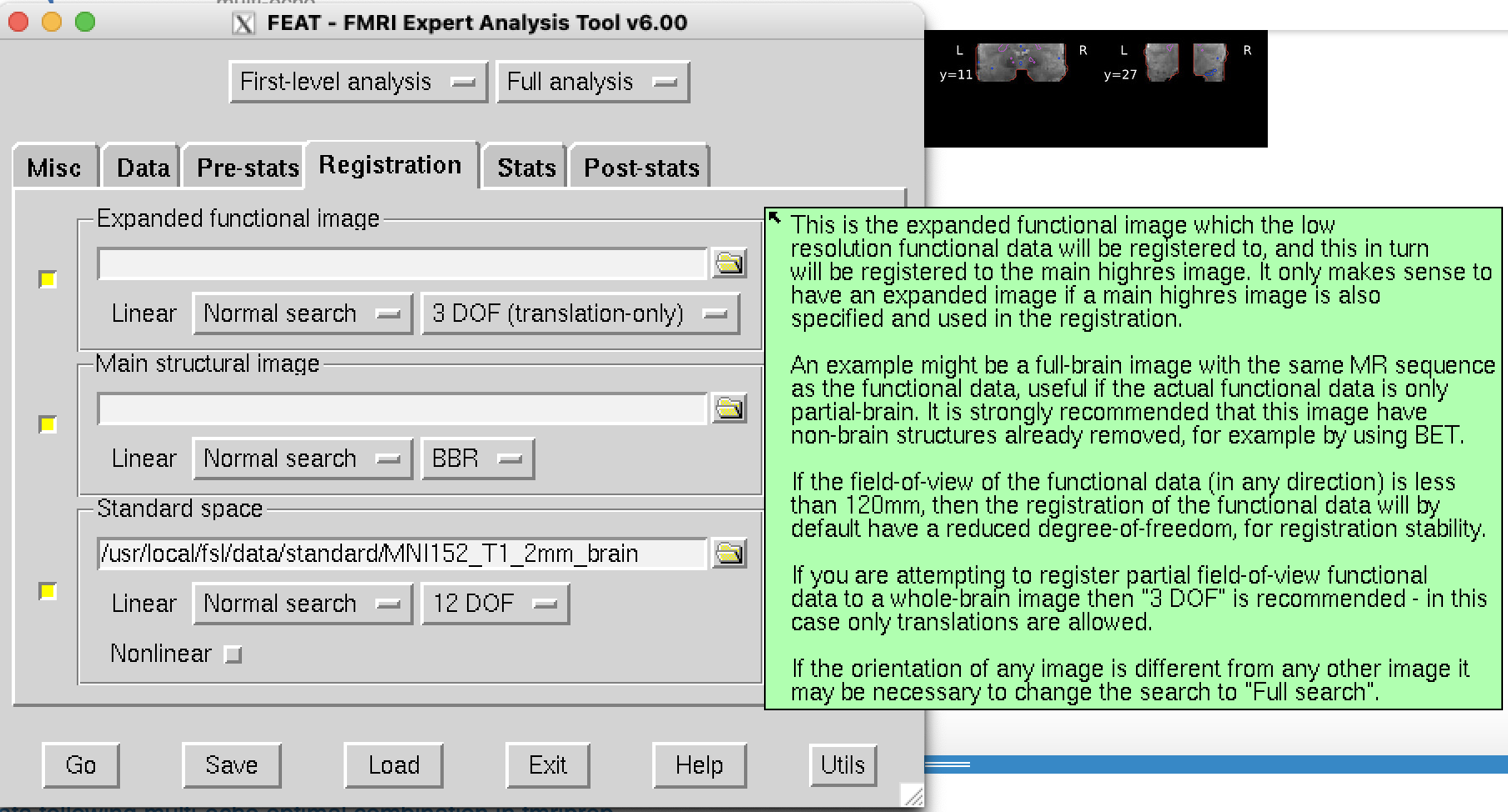
I don’t want to get off topic here, but I wonder if the registration algorithms in FMRIPrep would benefit from the addition of an “expanded functional image” when processing a partial-brain image like I have here. I know that is a strategy in FSL (see attached).
I do like this idea. Ideally this would be unambiguously represented in the dataset itself, so do we know what this would this look like in BIDS? Would it just be an sbref with a larger FoV? Or if it would be normal to make it acq-expanded_sbref.nii.gz, we could ask users to pass --expanded-functional acq:expanded (or something).
Great! We’d have to loop in some additional experts of BIDS, but I would be happy with solving this by having an sbref with a larger FOV. Whether single-band or multi-band, there could be some situations in which it is a partial brain acquisition.