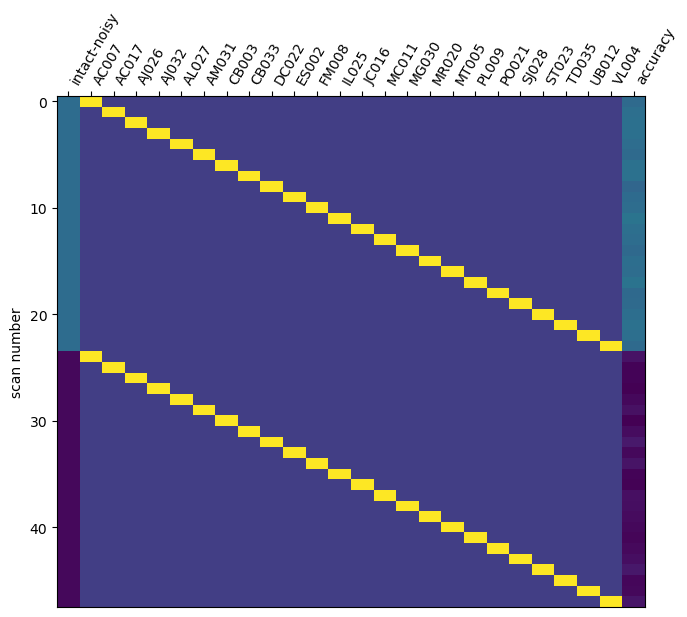
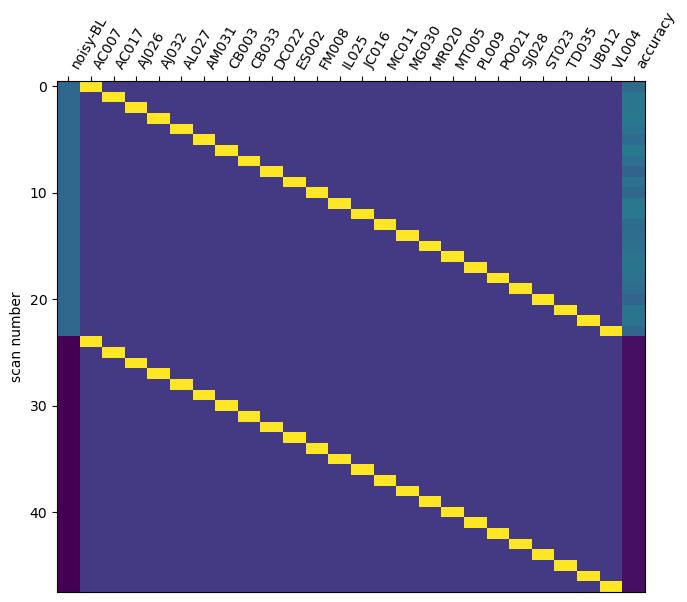
I am new to the paired group analysis that I just followed the example.
I would like to check
for the unpaired design I create the contrast AvsB at the first-level individually and then input the contrast AvsB of all subject for the second-level analysis;
on the other hand, for the paired design I create the condition A and the condition B at the first-level individually, and then input the condition A as 1 and the condition B as -1 for the contrast AvsB at the group-level, am I right?
I output the stat file at the first-level as the input of the second-level and output the z-score at the second-level to threshold_stats_img for the statistics of the t-value, does this sound reasonable?
Am I right to put the behavioral accuracy for the condition intact, and the (behavioral accuracy * -1) for the condition noisy to get the association between the activation t-value and behavioral accuracy?
and if I threshold_stats_img of the output z-score with two_sided=True, does the positive values mean the positive association between the behavioral accuracy for the condition intact, and the negative values mean the positive association between the behavioral accuracy for the condition noisy?
If the contrast is versus baseline as below, what should I put for the accuracy of the baseline condition? 0? -1? 0.5? -0.5? (chance-level = 0.5)
For the unpaired design you create A and B for each subject and simply include the A-B column (the first column in your matrix), i.e. you remove the subjects regressors.
Yes
No this does not look good: your accuracy regressor is pretty much colinear with the noisy-BL one, meaning that you will have a hard time detecting an effect with either regressor.
Positive/negative activations can only be intrepreted as realtive effect (more activation in A than in B or the converse). You cannot interpret them as an absolute effect.
4 I don’t understand what you want to model/test with the accuracy…
Best,
Bertrand
Thank you very much for the suggestions.
I was following the example generic design in second-level models, in which the one sample test for the association between contrasted activation and behavioral reading time (fluency) by the input design matrix with columns=[“fluency”, “intercept”] and .compute_contrast(“fluency”).
For my data, I want to see if there is association between contrasted activation and behavioral eidentification performance (accuracy), with a paired two sample design.
I am not clear with myself what is the difference between the results from contrasts “intact vs noisy” and from “intact vs baseline” and “noisy vs baseline” separately.
From what I understand, if I threshold_stats_img of the output z-score with two_sided=True, I can therefore plot the positive value and negative values.
I think I understand better now that the positive values I got from the contrast “intact vs noisy” is, positive association between the intact condition activation and behavioral accuracy relative to noisy condition, and the negative values indicate the positive association between the noisy condition activation and behavioral accuracy relative to intact condition, am I right? or a paired two sample test is not right here?
if I started from something simpler, for example, the noisy vs baseline contrast, I am not sure what to put in the colum “accuracy” for the baseline(BL) part. -1 or behavioral chance value (-0.5)? I put -0.5 for all the subject in the design matrix above (“noisy-BL”), and that’s why it looks much colinear, or I should not use a paired two sample test here?
here is my script:
### contrast_files are the first-level contrast map; contrast_pair are the interested contrasts,
### e.g., to compute the paired contrast "noisy-BL" here contrast_id1='noisy' and contrast_id2 ='BL'
for contrast_pair in contrasts.keys():
contrast_id1, contrast_id2 = contrast_pair.split('-')
if contrast_id1 in contrast_files and contrast_id2 in contrast_files:
second_level_input = contrast_files[contrast_id1] + contrast_files[contrast_id2]
condition_effect = np.hstack(([1] * n_subjects, [-1] * n_subjects))
subject_effect = np.vstack((np.eye(n_subjects), np.eye(n_subjects)))
## for the contrast "noisy-BL" here, I put -0.5 as the baseline(BL) for the column "accuracy"
accuracy_effect = np.hstack((combined_df[contrast_id1].values, [-0.5] * n_subjects))
design_matrix = pd.DataFrame(
np.hstack((condition_effect[:, np.newaxis], subject_effect, accuracy_effect[:, np.newaxis])),
columns=[f'{contrast_id1}-{contrast_id2}'] + subjects + ['accuracy']
)
second_level_model = SecondLevelModel(n_jobs=-1).fit(
second_level_input, design_matrix=design_matrix
)
zmap = second_level_model.compute_contrast("accuracy", output_type='z_score')
If I can do a paired two sample test for this generic design, does the positive values from the thresh_stats_img(zmap) indicate the positive association of the noisy condition activation and accuracy relative to baseline, and the negative values indicate the negative association of the noisy condition activation and accuracy relative to baseline?
My understanding is that you should have an accuracy regressor + a regressor for the interaction (i.e. product) of accuracy with the noisy-BL (or intact vs noisy, it’s up to you). The effect you’re interested in is this interaction term, I guess.
I you do that, the description you propose is OK.
Best,
Bertrand
Thank you very much for your suggestion.
To update my script sbove, for the contrast versus BL (e.g., noisy-BL here), I later on used
### combined_df is the behavioral df
accuracy_effect = np.hstack(([1] * combined_df[contrast_id1].values, [-1] * combined_df[contrast_id1].values))
The Nilearn example presents one-sample test while I tried to combine this generic design with paired two-sample t-test. So yes, I think that using 1 and -1 product for any contrast (either condition vs condition or condition vs baseline) would make sense.