I am new to multi-echo fMRI data. Thank you so much for your time in advance.
I tried fmriprep 20.2.1 which is the version recommended by Tedana, because its working directory saved the “bold_bold_trans_wf” folder and we could use the script named collect_fmriprep.py to extract “vol0000_xform-00000_merged.nii.gz”. But I noticed that there is a “WARNING: Version 20.2.1 of fMRIPrep (current) has been FLAGGED. reason: Functional outputs in standard space can be wrong depending on the original data’s orientation headers”. So I changed to fmriprep version 21.0.1. And I added the parameters of “–me-output-echos” and “–ignore slicetiming”, but the generated working directory didn’t include “bold_bold_trans_wf” anymore. (I am not sure it’s due to the change of version or parameter setting.) So I am wondering where to find the preprocessed data and send them to Tedana. Is it “fmriprep/derivatives/sub-01/sub-01_task-name_echo-1_desc-preproc_bold.nii.gz”?
My second question is when is a good time to use susceptibility distortion correction(SDC). From the introduction of Tedana, “Any step that will alter the relationship of signal magnitudes between echoes should occur after denoising and combining of the echoes.” So I guess it suggested we apply SDC after combining different echos, meaning that we need to do SDC on the outputs of Tedana. But the default setting of fmriprep with parameter “–me-output-echos” seems to include SDC already (including slicing timing, head motion and susceptibility distortion corrections). So I am a little confused about the step of SDC.
And are the combined-echo data from Tedana in native space? What steps are needed for preprocessing?
Is there a whole recommended pipeline for multi-echo fMRI preprocessing?
Sorry for so many questions. I truly appreciate it if you could answer any of them.
--me-output-echos basically does what the collection script we shared does, but incorporated into the actual workflow. The outputs are still semi-preprocessed echo-wise data, after slice timing correction, motion correction, and distortion correction.
Exactly. There’s no need to worry about the working directory with version 21+.
While tedana does recommend doing distortion correction after denoising, it does so with strong caveats. Together, the tedana and fMRIPrep teams decided that trying to separate distortion correction out of the whole procedure would be too much work for both developers and users (given that there would be an additional transform to account for after running tedana on the preprocessed echoes), and the benefits would be small, if not insignificant.
The space of the data coming out of tedana depends on the space of the data going into tedana. fMRIPrep’s preprocessed echoes will be in native space, so if you use those in tedana then the output will also be in native space.
Essentially, you can run tedana on the preprocessed echoes and then apply the native-to-T1w and T1w-to-standard transforms also outputted by fMRIPrep to get your denoised data into standard space.
I’ve opened a pull request to incorporate this information into tedana’s documentation. The PR includes a command for applying the relevant transforms to get denoised data to standard space, and it might be useful for you.
Most of tedana’s recommendations are fairly generic and not empirically validated, so we can’t say that there is a “best” preprocessing pipeline. We have done a lot of work to try to make tedana work well with both fMRIPrep and AFNI, though, so we recommend either.
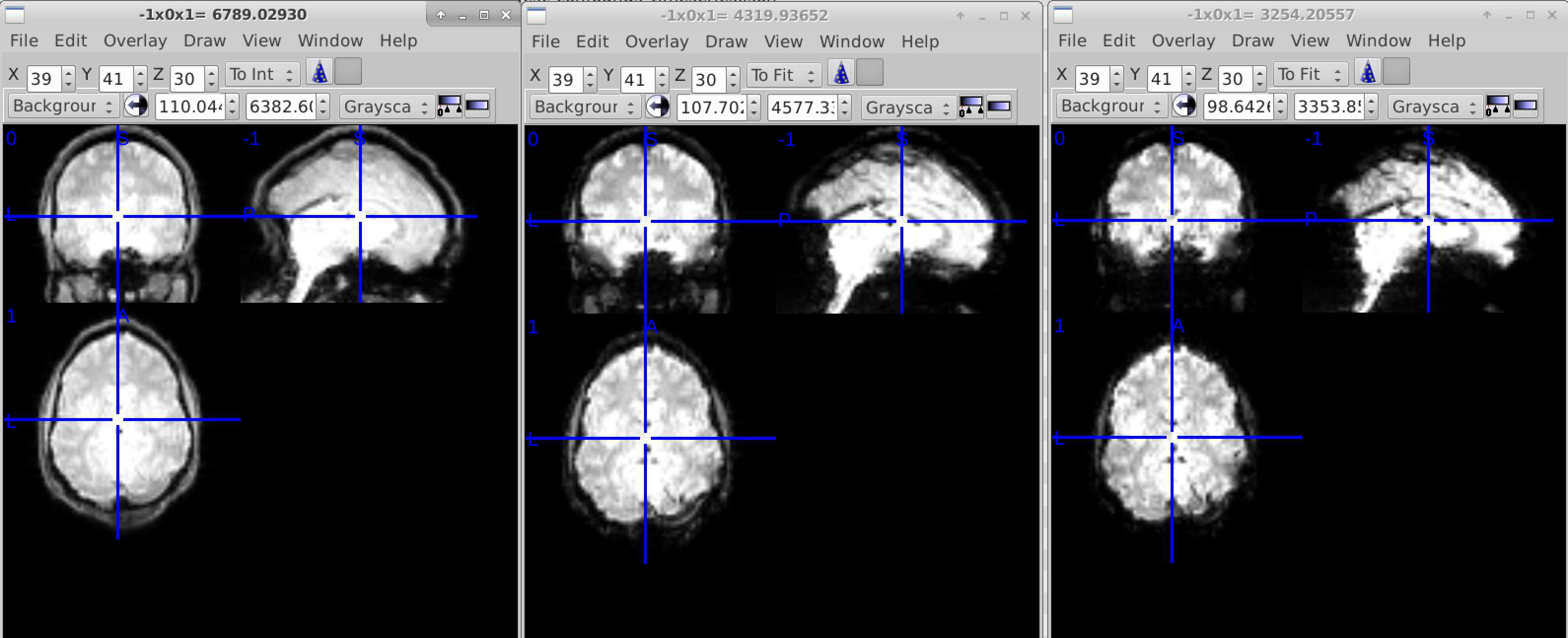
That’s perfect. But I found the results of the three echos are obviously different (I attached a screenshot here.) (with parameters “–me-output-echos” and “–ignore slicetiming, fieldmaps”.)
The first image is “fmriprep/derivatives/sub-01/sub-01_task-name_echo-1_desc-preproc_bold.nii.gz”, the second and third are echo-2 and echo-3. It looks like there are still some brain skulls, especially in the first echo. Is this a normal situation or not?
Do you mean I can feed the combined-echo data from Tedana into fmriprep to perform native-to-T1w and T1w-to-standard transforms? How to do this? I found parameter “–bold2t1w-init” only. And is there a problem with the BIDS format validation?
May I apply susceptibility distortion correction on the combined-echo data as well? And how if it’s yes?
Thank you again for your attention and patience! (And sorry for so many questions.)
I believe that the skull signal is just dropping out as echo time increases. If you look at this example with raw multi-echo data, you’ll see a similar pattern across echoes.
I don’t think there’s a way to submit the preprocessed data to fMRIPrep, but you can use something like ANTS’s antsApplyTransforms command-line tool to do it directly to the files (rather than as part of a BIDS app like fMRIPrep). There are a few questions on this site about using antsApplyTransforms with fMRIPrep data, and there is example code in that PR I linked to in my last post.
Distortion correction has already been applied by fMRIPrep.
Thank you again for your instant reply. That makes good sense to me and helps me a lot.
I have one tiny question is if fmriprep applies motion correction as the following rule(from the document of Tedana)? I guess it must be, just for 100% sure. (I just can’t find so detailed introduction of fmriprep.)
“Estimate motion correction parameters from one echo and apply those parameters to all echoes. When preparing ME-EPI data for multi-echo denoising with a tool like tedana, it is important not to do anything that mean shifts the data or otherwise separately scales the voxelwise values at each echo.”