Hi Wen-Jing,
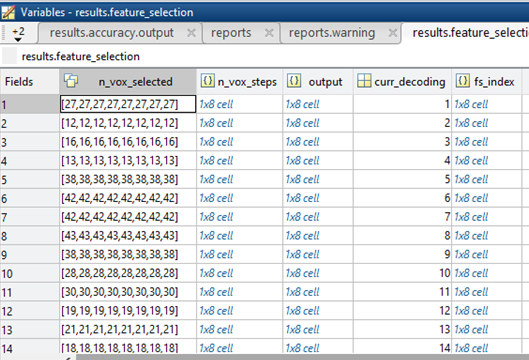
That looks unusual. Essentially it says you passed 81 ROIs instead of one, and since 100 voxels could not be selected in each iteration, it selected the maximum, i.e. 27 in the first, 12 in the second, etc. Since I don’t know your cfg settings, I can only guess. I think maybe instead of passing a binary ROI mask you passed a mask with many different numbers. This would be treated by TDT as separate ROIs (the ROI mask would essentially be a multimask).
Look at the screen output and warnings, TDT should inform you if it is 81 ROIs and if you can’t select as many voxels as you want. Perhaps plot the different steps using
cfg.plot_selected_voxels = 1;
Also, rethinking my suggestion, I think I would actually recommend using an external T-map or F-map instead, it will be more sensitive because it uses the residuals of the runs for calculating those values rather than the beta values alone. If you use the F-contrast against baseline, you could set
cfg.feature_selection.estimation = 'all';
If not, you should keep it at 'across'.
If you want to use the actual contrast that classification is based on itself (probably the most sensitive approach), you would have to create one external map for each cross-validation iteration. The first map would use all but the first run for the contrast, the second all but the second, etc. Then you can pass all eight.
cfg.decoding.method = 'classification';
cfg.feature_selection.method = 'filter';
cfg.feature_selection.filter = 'external';
cfg.feature_selection.external_fname = {...}; % file names for your contrast maps
Cheers,
Martin