I"m pretty new to fMRI preprocessing so I’m trying to learn along the way as best I can. Any information anyone might have would be very helpful. Thanks again!
Summary of what happened:
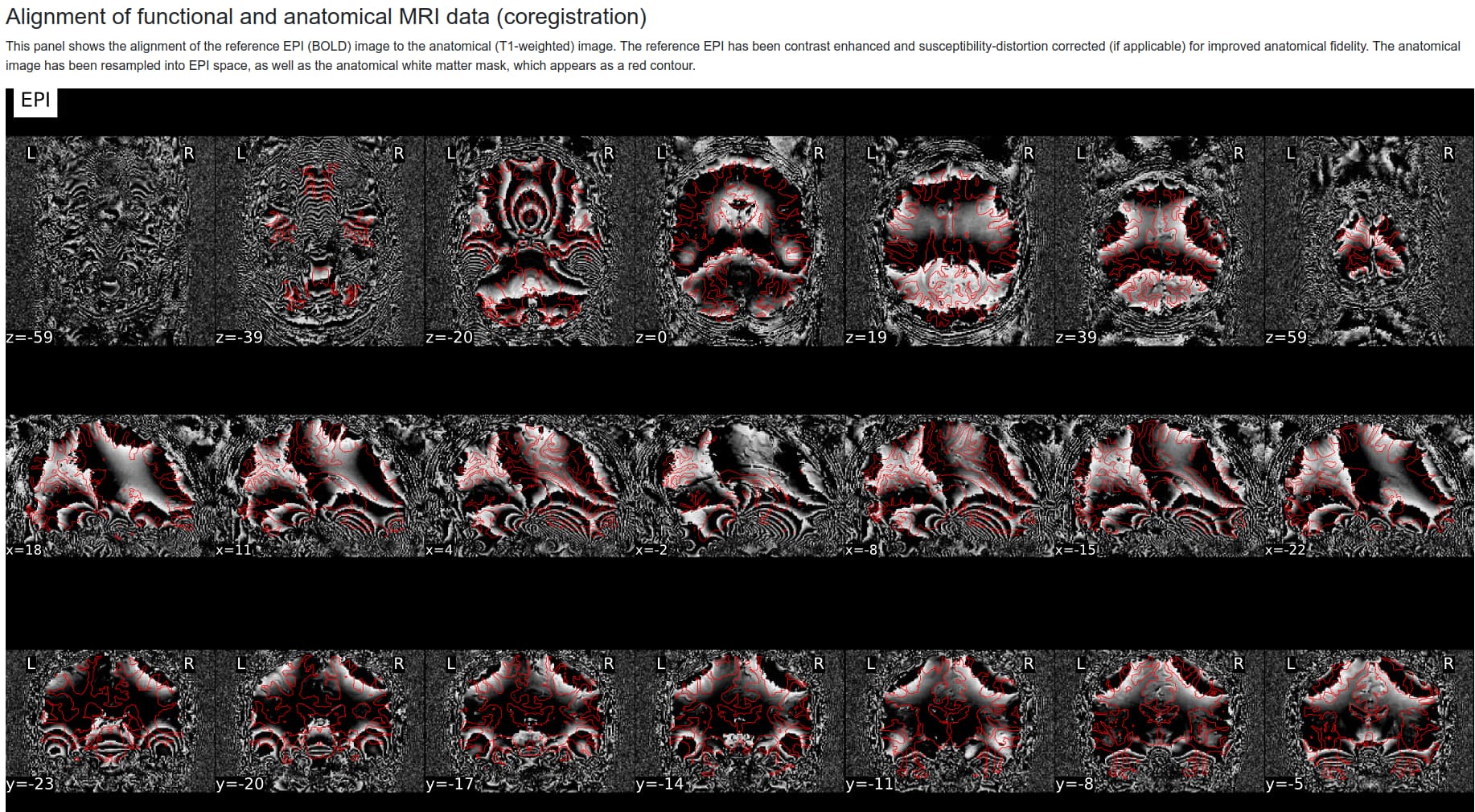
I am getting very strange looking images for roughly half of my functional scans when I examine the .html output files provided by fMRIPrep as seen in the screenshot region below. Many of the runs have come out looking find, many have not.
Command used (and if a helper script was used, a link to the helper script or the command generated):
Those look like phase data. What does your input dataset look like? Did you include part-mag and part-phase to distinguish the magnitude and phase BOLD data?
I don’t seem to have a magnitude file, is it the default?
For example, looking in the .json files, would the one marked with “ImageType”: [“ORIGINAL”, “PRIMARY”, “M”, “ND”, “MOSAIC”] be magnitude and “ImageType”: [“ORIGINAL”, “PRIMARY”, “P”, “ND”, “MOSAIC”, “PHASE”] be phase?
Do I need to put these tags in the file names as part-phase and part-mag before putting them through fMRIPrep? Is there anything I should be adding to the input script?
I don’t seem to have a magnitude file, is it the default?
In BIDS, not having a part entity defaults to “mag”, so if you didn’t have phase data you could just not include the part entity. Basically yes, magnitude is treated as the default in BIDS (at least for BOLD data).
That’s exactly correct.
It looks like this is a BIDS curation problem. You definitely need to add the part entity to these filenames (which will involve changes to metadata as well). The magnitude and phase parts come from the same run, so you want other entities (e.g., run, acq) to be the same across the two files from the same run.
If you really need to process these data ASAP without renaming files or reconverting the data from DICOMs, then you could probably either remove the phase files from the dataset or work around them with the --bids-filter-file you pass into fMRIPrep.
On a related note, since most folks who run complex-valued multi-echo fMRI seem to also want to use NORDIC, did you acquire noise scans at the end of your fMRI runs? If so, you’ll need to split those noise scans out into separate files with the noRF suffix. fMRIPrep won’t work well on those volumes otherwise.
As a side question, I’m not familiar with NORDIC but it’s something I will look into now. How do I know if there are noise scans at the end of the runs? Are these identified somehow such that I could change suffixes?
The easiest way to check would be to look at your protocol PDF (assuming your data come from a Siemens scanner). With the CMRR MB-EPI sequence, you can find the value of the “EPI noise scans” field under the “Sequence - Special” card. If it’s > 0, then you have noise scans at the end of the scan.
Otherwise, you can look at the files with an image viewer (e.g., fsleyes). If you go to the last volume in the series, it should look basically like white noise instead of a brain if it’s a noise scan. Just move back from that last scan until it looks like a brain again, and that should tell you how many noise scans you have.