Hi all,
We are trying TDT (3.999F) for the first time and applying the template to a multiple regression VBM study, with three regressors of interest, and three of no interest.
We used the decoding template and linked it to an existing SPM.mat file and related betas for that regression.
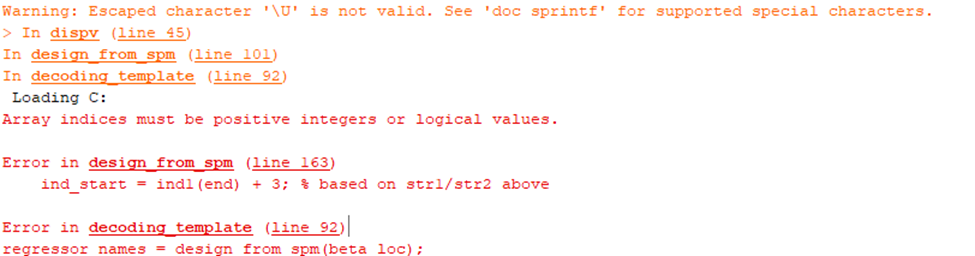
However, when we try running the script, we get the following errors:
It seems as if the template may not be so useful for this, since the script implicitly assumes that you have several runs per participant and that you are dealing with functional data. All regressors usually start with Sn(1), which is probably not the case here.
I would suggest using the no_betas or the between_subject template (they are almost identical really) and loading in the data by pointing to each of the files individually. This should probably do the job! (i.e. don’t use design_from_spm). It does require a little bit of coding to format the paths correctly or do this programatically, but I think it should be fairly straightforward!
Thank you for your quick reply! On the no_betas template, for my input files, would I still link all of my beta files from my SPM regression? For ex, if I have 7 beta files for my regression (1 mean, 6 no interest regressors, and 1 of interest), would I link all 7, or just the one I am interested in?
Also, I am a bit confused as to what to put for the “cfg.files.chunk =” since there’s only 1 run in this case.
You only include the betas of interest. I’m not entirely sure about the format of your data but you would want to be able to split your data into a minimum of 2 splits balanced in all respects and of equal size. I would ideally split data into smaller chunks that are balanced within each. Then you manually assign each chunk a number. During cross-validation, then all-but-one chunk are used for training and all others for validation.
Now, since you still want to run proper stats, you may need to divide the data up into a sufficient number of chunks, I would say probably 12 which provides enough combinations for permutation statistics for sensitive stats.
P.S. you could also repeatedly run this analysis with different chunks, given how fast it should be. But this would be a little bit more involved to set up.
Hi, thank you! I have a sample of 190 subjects (incl. both M and F). Since I have already run stats with SPM on the regressor of interest, is it recommended to take the betas from an ROI from SPM VBM results and try to divide into different chunks? I’m sorry for all of the questions, I know it’s not as easy to apply this to a VBM versus functional data!
Thank you!
I don’t know much about VBM but usually you have two regressors of interest that you compare with classification. If you have only one regressor of interest, then it seems that instead of classification you may actually want to run some sort of regression-based approach.
Is your independent variable that you care about binary or continuous? Eg if you want to classify gender it would be binary. If you would like to find information in the brain about age, it could be regression (continuous age) or classification (e.g. old vs. young)
If you use classification you need one regressor per condition per chunk. If you use regression it gets a bit more complicated, specifically when you are dealing with potential confounds.
In terms of splitting data, you could essentially split up your data into e.g. 19 splits of 10 participants each. Make sure they are approximately balanced wrt age and gender within each chunk.
Hi thank you for your response! The IV is continuous - it’s a numerical score of a questionnaire. I believe we need to use regression here instead of classification, and you’re right, there is a potential for confounds. When running my regression in SPM stats, I was able to control for age, gender, and total intracranial volume of my subjects, but I assume I won’t be able to do that here.
Yes, in that case things will be a bit more complicated and likely beyond what you can do with an out of the box toolbox.
Since you are using VBM and in order to not discourage you, I would suggest the following: Run your VBM analysis but this time set up in different blocks of regressors, i.e. separate regressors for subsets of participants that you chunk together (e.g. 19 such blocks). Then see if you can get the searchlight version or at least the core version of this toolbox to run:
If not, I would say you would probably have to revert to doing this manually. Controlling for confounds is just not trivial in this context. Check out this work: