I have ran an language experiment with participants reading two class of words (A, B) in two languages (L1, L2). I would like to train the data in one language (A, B in L1) and then test on words in the other language (A,B in L2). I’m using a searchlight approach and beta images from SPM as files.
However, when I run the analysis, I get the following error message:
searchlight: 1/174294, time to go: 03:46:35, time running: 00:00:00, finish: 2018/09/05 15:22:44
Error using libsvm_test (line 50)
libsvm’s svmpredict returned empty predictions - please check your design, whether the model was passed properly, or whether you are using the correct version of svmpredict.
Error in decoding (line 548)
decoding_out(i_step) = cfg.decoding.fhandle_test(labels_test,data_test,cfg,model); %#ok
Does anybody have an idea of what I’m doing wrong?
Many thanks
Simone
I’m not sure what could be wrong, but somewhat libsvm predictions are empty. Likely, something in the data is already off (e.g. all numbers are the same). Since it’s difficult to know what your data look like, I would recommend looking at the design matrix and checking if it looks normal (probably it does). Good old debugging will likely get you there. Go to the console and type
edit libsvm_test.m
then navigate to line 40 and set a break point (by clicking on the little horizontal line next to the line number). Then re-run the code. The first time around is a basic check, so you can type dbcont in the command line. The second time around, inspect the relevant variables (data_test, labels_test, model). If model is empty, the problem already occurs for libsvm_train, then just redo there.
Another thing you could do is change the classifier to see if the problem persists. My guess is it would but it might be worth a try.
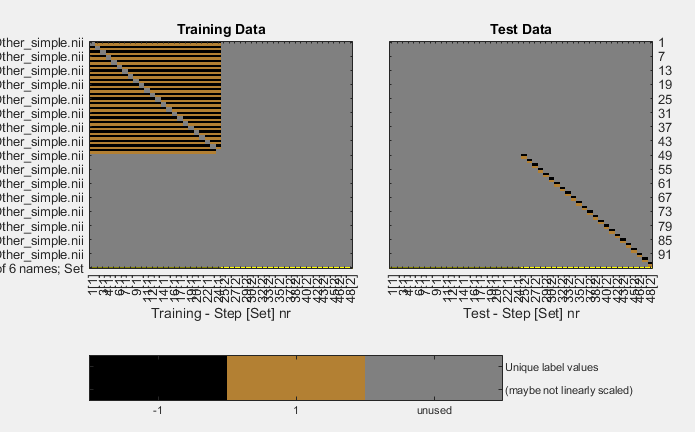
My study was a between group design with each participant has two conditions. I want to use one group to train a classifier and test on the other group (using leave-one-subject-out) and the other way around seperately so I set the cfg.files.twoway = 0.
The thing is, dispite I got the exact decoding design plot I was looking for, I ran into the same error message as above. Since it also happened when I conducted twoway classifcation and I was able to solve it by modifying the parameters in the make_design_xclass_cv, I dont think it is caused by the libsvm_test itself.
I don’t know if it is the setting that went wrong? Here is the details of my studies and data:
I have 48 subjects, 24 for each groug. For each subject, there are 2 images corresponding to 2 conditions. In the data folder, the first 48 images belongs to group 1 and the other group 2.
Here is the scripts I used to set the make_design_xclass_cv
Also a small question, I am a little confused about cfg.files.set and wondering what is the difference between set and xclass? The amount of input numbers in my experience can only be set to match the amount of file, in my case 96. But I did notice the comments on the top of make_design_xclass_cv used much less values.
Any guidance or advice are more than welcome. Look forward to your reply!
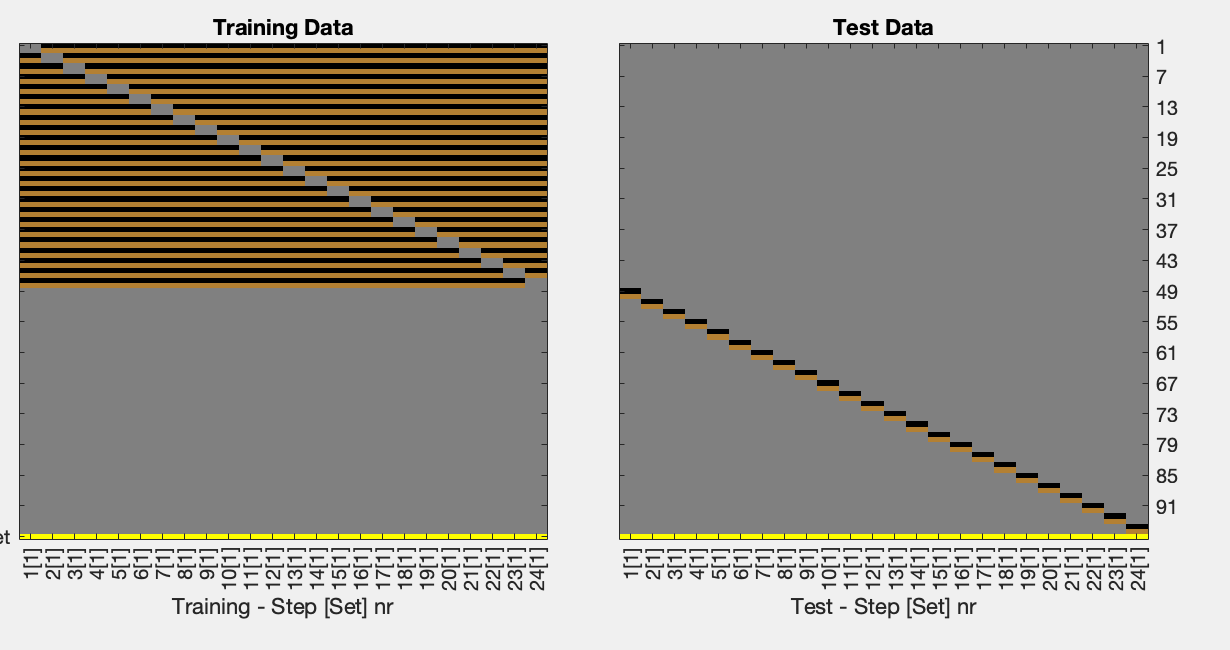
I think you might need to slightly adapt your code. This kind of design has empty test data in the first 48 iterations and empty training data in the last 48 iterations. Each column is an iteration of training and testing.
You will see that I made two changes: i removed cfg.files.set and I have slightly adapted cfg.files.chunk. The chunk variable just says which data you want to keep together. If you want to leave out only one participant, in cross classification you have to assume it is paired to another participant (else it isn’t cross classification in the proper sense). At least if you want to leave one participant out. For that reason, we now have 24 participants or “participant pairs” rather than 48.
The set variable is only needed if you want to run multiple decoding analyses in one. For each set, you get results reported separately. This can serve to speed up analyses, but it’s something more advanced.
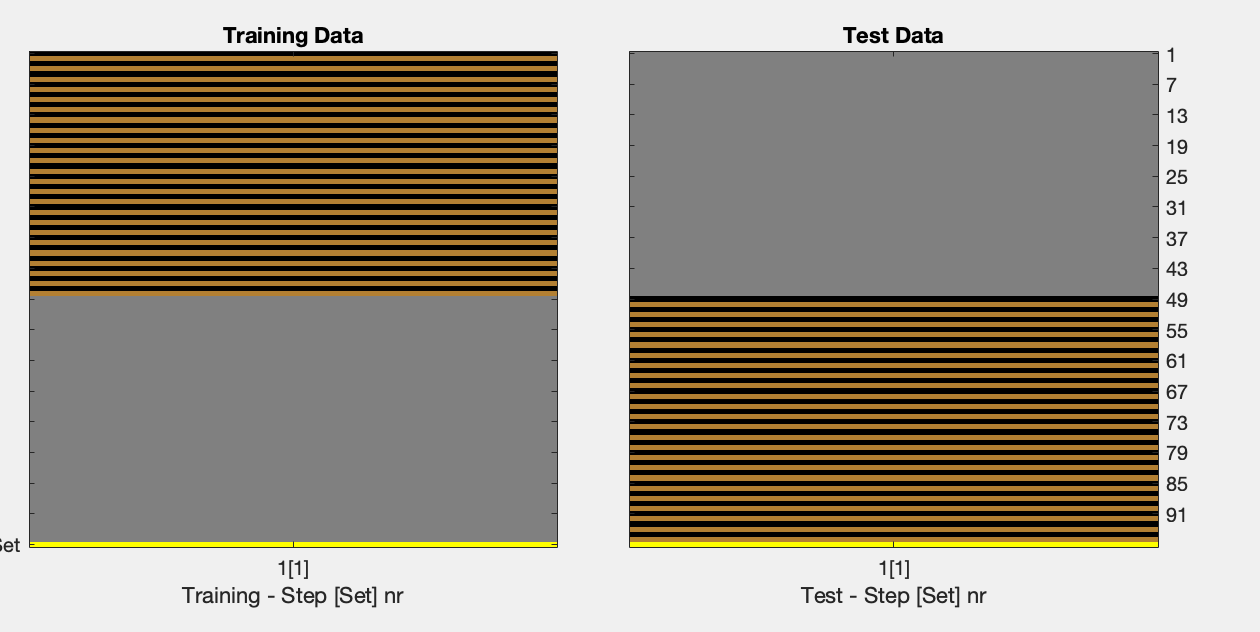
Thank you for your quick reply! I really appreciate your suggestion. I tried the settings you mentioned, but unfortunately, it still didn’t work. The weird thing is, once cfg.files.twoway = 0 is changed into 1, the script works perfectly fine.
You raised a very important point. My initial goal was to train and test on the first group of subjects using leave-one-subject-out cross-validation, and then test the model on the other group to see if the classifier could generate to the other and vice versa. In that case, the left subject would be in the same group as the other test subjects.
But I have to admit it I’m very new to mvpa and tdt. Although the toolbox is very handy and easy to set (thank you all so much for the work!), I haven’t been able to find the exact cfg parameters I should change, which is why I went with my current design. Do you have any recommendations on how I could approach this?
which as a design should work (in contrast to the one we had previously). Did you clear your variables before running this? (e.g. clear cfg)
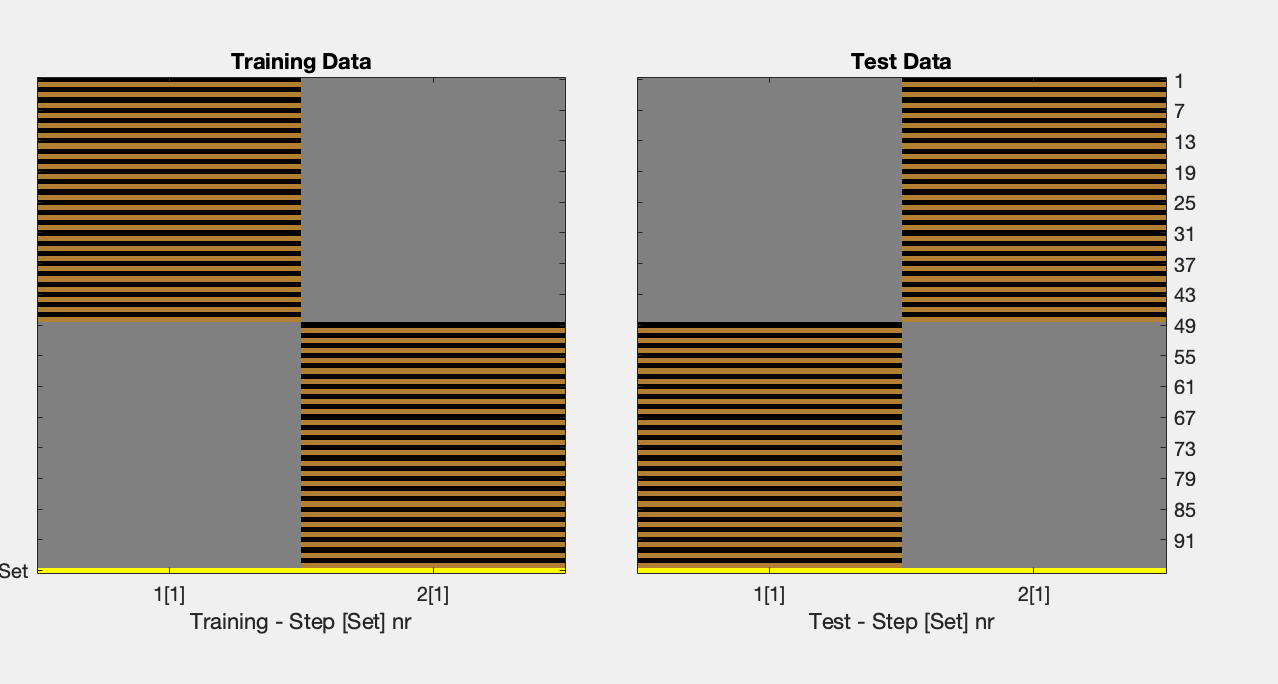
I would consider running make_design_xclass without the cv part. I think this might make more sense in your case. The resulting matrix would look like this:
Yesterday when I ran the codes you modified, I could obtain the correct design but still got the error message that “libsvm’s svmpredict returned empty predictions”. Somehow the script worked today, luckily.
I am now working on the without-cv design you suggested and I’m truly grateful for your advice.