I am using Tedana for denoising of 36min multi-echo runs acquired with a 7T Siemens Magnetom. I have applied Tedana for several runs, all in which ICA failed to converge after 10 steps of 500 iterations. Data is slice time corrected and motion corrected (in that order) using SPM. Motion correction has been applied based on the parameters of the first echo, as stated in the Tedana documentation.
My Tedana call looks like this:
tedana -d rasubj14_func_con_ET1.nii rasubj14_func_con_ET2.nii rasubj14_func_con_ET3.nii -e 10.6 26.08 41.56 --out-dir saline_subj14
/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/externals/joblib/init.py:15: DeprecationWarning: sklearn.externals.joblib is deprecated in 0.21 and will be removed in 0.23. Please import this functionality directly from joblib, which can be installed with: pip install joblib. If this warning is raised when loading pickled models, you may need to re-serialize those models with scikit-learn 0.21+.
warnings.warn(msg, category=DeprecationWarning)
INFO:tedana.workflows.tedana:Using output directory: /home/bram/saline_subj14
INFO:tedana.workflows.tedana:Loading input data: [‘rasubj14_func_con_ET1.nii’, ‘rasubj14_func_con_ET2.nii’, ‘rasubj14_func_con_ET3.nii’]
INFO:tedana.workflows.tedana:Computing EPI mask from first echo
INFO:tedana.workflows.tedana:Computing T2* map
INFO:tedana.combine:Optimally combining data with voxel-wise T2 estimates
INFO:tedana.decomposition.pca:Computing PCA of optimally combined multi-echo data
INFO:tedana.metrics.kundu_fit:Fitting TE- and S0-dependent models to components
INFO:tedana.decomposition.pca:Selected 1349 components with MLE dimensionality detection
WARNING:tedana.decomposition.ica:ICA attempt 1 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 43
WARNING:tedana.decomposition.ica:ICA attempt 2 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 44
WARNING:tedana.decomposition.ica:ICA attempt 3 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 45
WARNING:tedana.decomposition.ica:ICA attempt 4 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 46
WARNING:tedana.decomposition.ica:ICA attempt 5 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 47
WARNING:tedana.decomposition.ica:ICA attempt 6 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 48
WARNING:tedana.decomposition.ica:ICA attempt 7 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 49
WARNING:tedana.decomposition.ica:ICA attempt 8 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 50
WARNING:tedana.decomposition.ica:ICA attempt 9 failed to converge after 500 iterations
WARNING:tedana.decomposition.ica:Random seed updated to 51
WARNING:tedana.decomposition.ica:ICA attempt 10 failed to converge after 500 iterations
INFO:tedana.workflows.tedana:Making second component selection guess from ICA results
INFO:tedana.metrics.kundu_fit:Fitting TE- and S0-dependent models to components
INFO:tedana.metrics.kundu_fit:Performing spatial clustering of components
INFO:tedana.selection.tedica:Performing ICA component selection with Kundu decision tree v2.5
INFO:tedana.io:Writing optimally combined time series: /home/bram/saline_subj14/ts_OC.nii
INFO:tedana.io:Variance explained by ICA decomposition: 100.00%
INFO:tedana.io:Writing high-Kappa time series: /home/bram/saline_subj14/hik_ts_OC.nii
INFO:tedana.io:Writing low-Kappa time series: /home/bram/saline_subj14/lowk_ts_OC.nii
INFO:tedana.io:Writing denoised time series: /home/bram/saline_subj14/dn_ts_OC.nii
INFO:tedana.io:Writing full ICA coefficient feature set: /home/bram/saline_subj14/betas_OC.nii
INFO:tedana.io:Writing denoised ICA coefficient feature set: /home/bram/saline_subj14/betas_hik_OC.nii
INFO:tedana.io:Writing Z-normalized spatial component maps: /home/bram/saline_subj14/feats_OC2.nii
INFO:tedana.workflows.tedana:Workflow completed
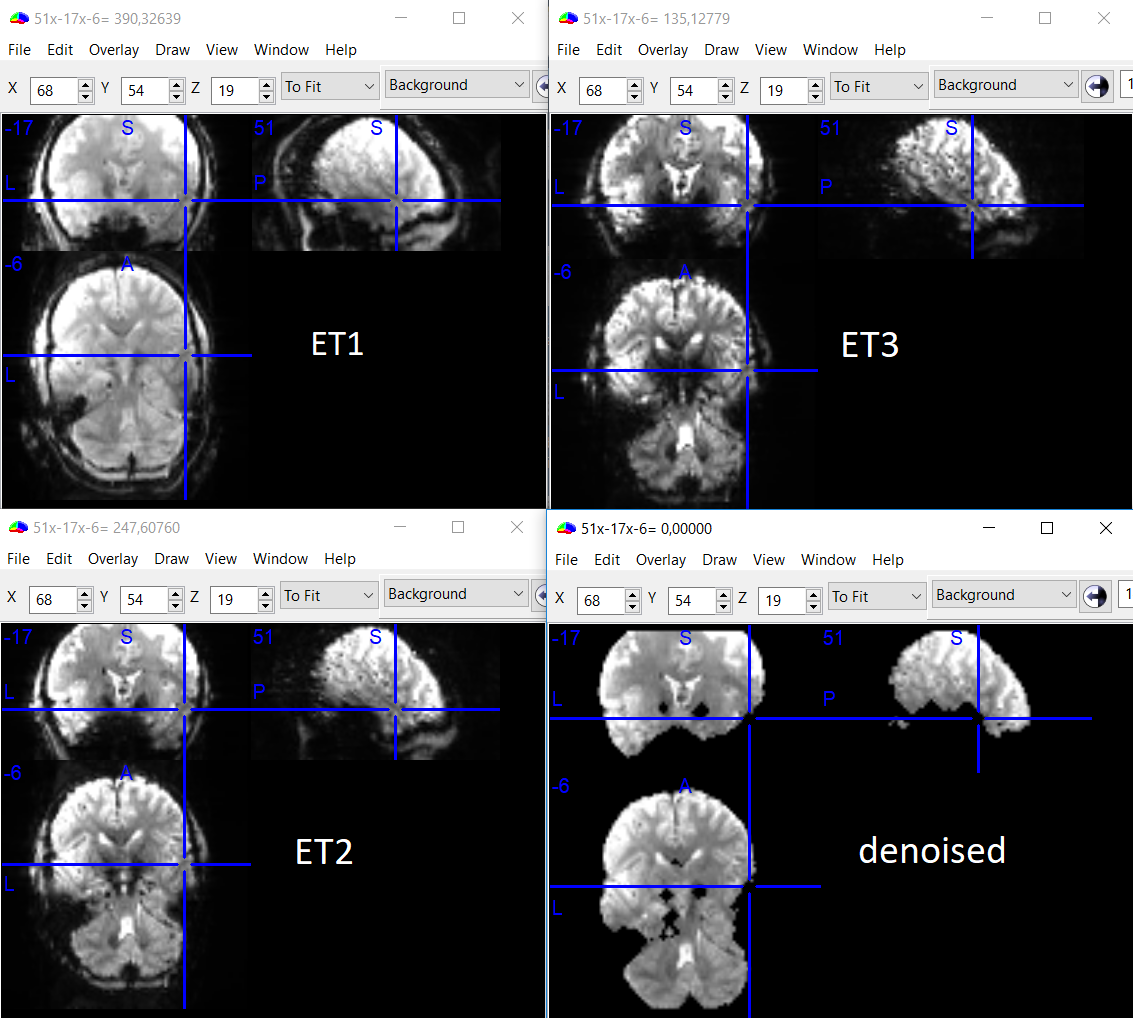
Looking at the dn_ts_OC.nii files, most appear to be OK, though some show signal loss at places where all three echoes do have signal (see attached).
Any ideas on what is going wrong, and how to solve this issue?
Issues with ICA convergence are linked to problems with the MLE dimensionality detection in the PCA step. This is a known bug ( https://github.com/ME-ICA/tedana/issues/356 ) which is a high priority to resolve at our first tedana hackathon in a couple of weeks. The kundu-stabilise option sometimes has issues, but it can get around the MLE problem. I hope there can be a better response in the not-to-distant future.
Ah I see. I tried the kundu-stabilize option but this throwns an error unfortunately:
/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/tedana/metrics/kundu_fit.py:160: RuntimeWarning: divide by zero encountered in true_divide
F_S0 = (alpha - SSE_S0) * (n_echos - 1) / (SSE_S0)
INFO:tedana.selection.tedpca:Performing PCA component selection with Kundu decision tree
INFO:tedana.selection.tedpca:Selected 0 components with Kappa threshold: 16.81, Rho threshold: 21.96
/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/scipy/stats/stats.py:2279: RuntimeWarning: divide by zero encountered in true_divide
np.expand_dims(sstd, axis=axis))
/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/scipy/stats/stats.py:2279: RuntimeWarning: invalid value encountered in true_divide
np.expand_dims(sstd, axis=axis))
Traceback (most recent call last):
File “/home/bram/miniconda3/envs/TEDANA/bin/tedana”, line 10, in
sys.exit(_main())
File “/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/tedana/workflows/tedana.py”, line 501, in main
tedana_workflow(**vars(options))
File “/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/tedana/workflows/tedana.py”, line 407, in tedana_workflow
maxit, maxrestart)
File “/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/tedana/decomposition/ica.py”, line 60, in tedica
ica.fit(data)
File "/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/decomposition/fastica.py", line 551, in fit
self.fit(X, compute_sources=False)
File "/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/decomposition/fastica.py", line 503, in fit
compute_sources=compute_sources, return_n_iter=True)
File "/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/decomposition/fastica.py", line 272, in fastica
ensure_min_samples=2).T
File “/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/utils/validation.py”, line 542, in check_array
allow_nan=force_all_finite == ‘allow-nan’)
File “/home/bram/miniconda3/envs/TEDANA/lib/python3.7/site-packages/sklearn/utils/validation.py”, line 56, in _assert_all_finite
raise ValueError(msg_err.format(type_err, X.dtype))
ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
It looks like the kundu-stabilize decision tree was too aggressive. Try using --tedpca kundu (a less aggressive version of the same PCA decision tree). It would also be helpful for the developers (including me) to see the PCA component table, if you could share that. We might be able to track down the specific steps in the decision tree that led to rejecting all components. The file is called comp_table_pca.txt.
I started tedana with the kundu option a few hours ago (still running), this time it selected 852 components (runs are 1350 volumes in total). I have attached both component tables (Kundu stabilize and Kundu), hope this helps!
Okay, so the good news is that the Kundu-stabilize decision tree failed because of a bug in the release you’re using, and not because of your data. The reason all of the components were rejected is that the cumulative variance explained is always above 0.95% (instead of 95%, as it should have been). This bug was found here and has been fixed in our master branch.
We have not made a release yet, though, so in order to use the Kundu-stabilize decision tree you’ll need to use the current, unreleased version of tedana. We are planning to cut a release in the next week or so, if you’d rather wait to install with pip.
EDIT: By manually editing the Kundu-stabilize decision tree you provided, I can estimate that the corrected version would retain ~340 components, which will probably be much better for the TEDICA that’s performed after.
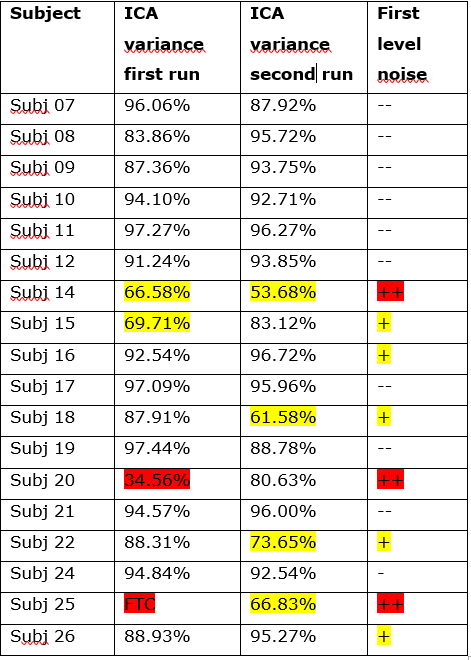
We have finally processed all of our data with the kundu-stabilize option. Most of the data turns out nice. We do see that the amount of variance explained by ICA can vary a lot (see attached). Importantly, in cases of lower explained variance, results at first level analysis appear to be more noisy.
I was wondering what could explain these differences. Is it solely related to the data itself, or are there ways to account for it/make ICA more efficient?
Edit: I am not sure whether the lower explained variance matters a lot, as results at group level do not appear noisy at all. I would just like to make sure that I am not missing something important here as to why ICA is performing less then optimal in some cases.