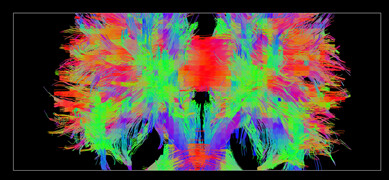
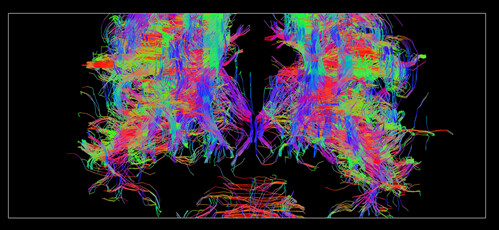
Yes, actually the second image is not expected to give that much fibers as I had taken the second eigen vector from DTI analysis. I was trying to compare to see if anything new fiber tracts are getting generated or the same old one using the second eigen vector. This analysis can help me to give a picture about fiber reconstruction using eigen vectors.
Regarding validation I read from the ISMRM 2015 website there were tractogram scripts which can tell about how many of them are valid. Sometimes, the fibers from the fiber reconstruction gives some fiber tracts which are not actually connected.
I am trying to use these two images and then try fusion of these two images to see if the fiber count is getting increased.
Well, the second (and third for that matter) eigenvector are simply perpendicular to the principal eigenvector which is usually used for tractography. In general probablistic tracking uses all the eigenvectors in that it takes the whole shape of the tensor into consideration when tracking, whereas deterministic tracking only uses the principal direction. I see no reason to track with the second eigenvector exclusively.
Yes I do agree with you. Suppose say I have the fiber reconstruction using DTI and the other using CSD. How can we compare the stats between the two fibers (like for instance in CSD how many more fibers have been generated).
I presume when you say “using DTI” you are referring to a deterministic approach where as CSD is typically employed in probabilistic tracking. These are hard to compare against each other due to the different concepts underlying their tracking (see the earlier answer). Also, often for tracking you manually define (especially in probabilistic tracking) the number of streamlines to produce, so such a comparison may also not make sense in that respect.
A better idea may be to only look at specific fiber tracts. Then you can use something like the dice score (https://doi.org/10.1186/s12880-015-0068-x) to evaluate segmentation performance.
I’m not sure if this issue has been resolved yet, but I think it might be worthwhile to clarify some of the underlying (or overarching?) questions here.
I think there’s some ambiguity as to what sort of analysis is entailed by “compare the stats between the two fibers” or “common fibers generated by the two methods”. In a certain sense, given the manner in which streamlines are generated, its highly unlikely that any two are “common” (e.g. equal, such that each node of the streamline is located in exactly the same spot) between any two tractograms.
Also, I think there may be some ambiguity arising from the use of the term “fibers” here. In some cases people use this term interchangeably with streamlines, whereas in other cases people use the term to indicate a collection of streamlines (or axons) corresponding to a coherent white matter structure. I think Steven’s proposed approach for assessing segmentation performance is quite viable, but it may be somewhat removed from your original goal of “validate these results”, as its viewing tractogram quality through the (somewhat distorted) lens of a particular segmentation implementation.
Part of this boils down to how you’re defining “validate”. Judging by the description that Ashwin provides relative to ISMRM, I think the primary goal is some notion of “biological plausibility”, right? In such a case there’s some fairly straightforward heuristics that you could use to assess this notion. For example, given what we know about streamlines they should probably terminate in plausible areas and follow reasonable paths (I discuss these heuristics a bit more in depth here). I think this may get at the notion of “connected” you’re using with “fiber tracts which are not actually connected”, but I could be wrong.
Anywho, apologies for dredging this up again if has already been resolved, and let me know if there’s anything else I can do to help,
 .
.