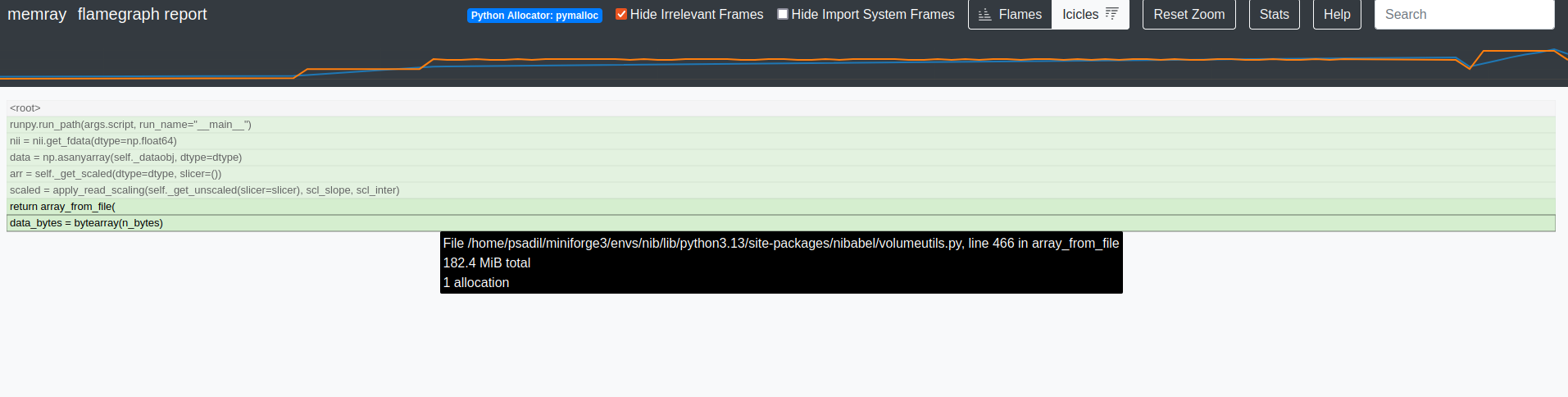
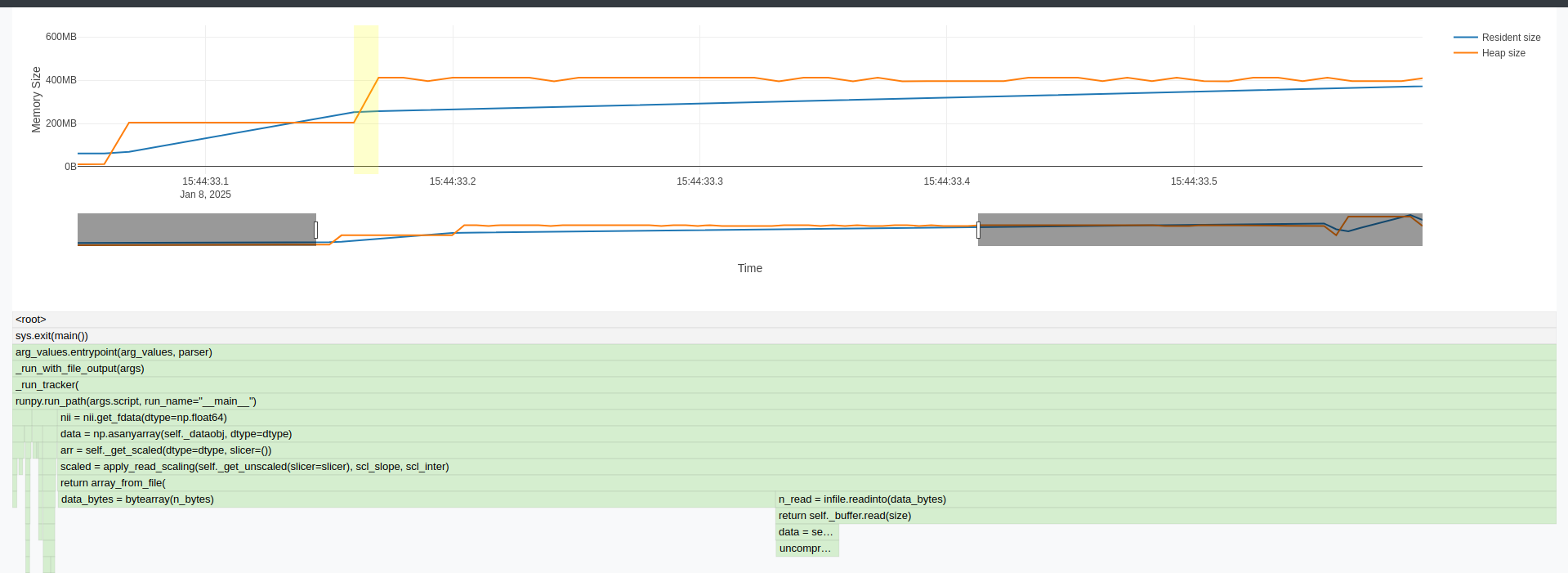
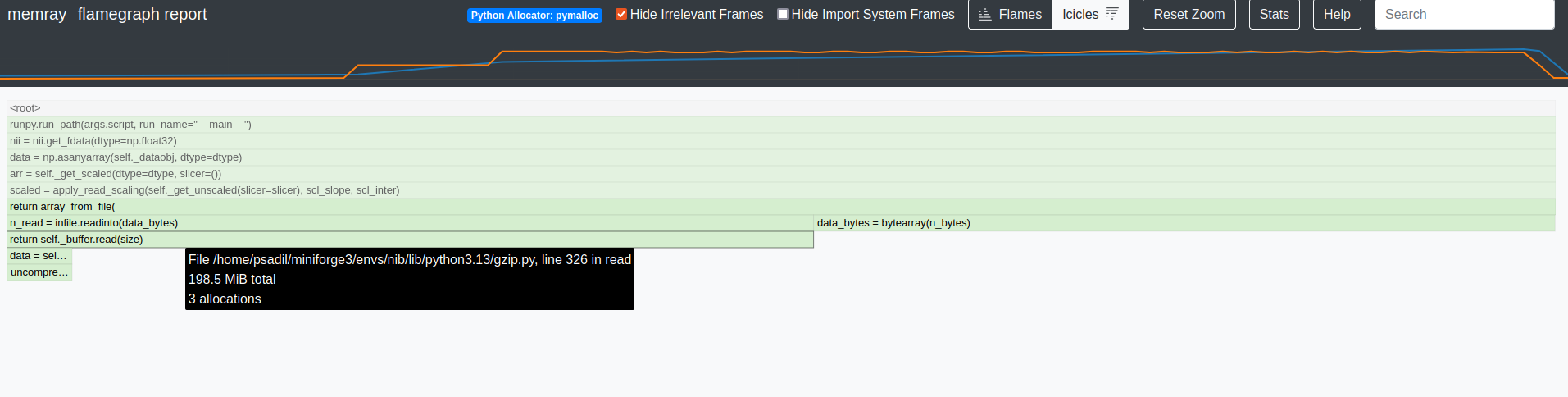
Summary of what happened:
While digging into another memory issue, I became confused by the memory allocated during get_fdata(). I’m trying to follow things with memray. According to their flamegraphs, about twice as much memory is allocated in the get_fdata(dtype=np.float32) as compared to get_fdata(dtype=np.float64) (yes, more when dtype is smaller–there are more allocations). In the float32 case, there’s an allocation during the buffer initialization: nibabel/nibabel/volumeutils.py at 7b5060e4bb105ed0c08c203db3dc5cf536d9c2aa · nipy/nibabel · GitHub and another just after while filling the buffer: nibabel/nibabel/volumeutils.py at 7b5060e4bb105ed0c08c203db3dc5cf536d9c2aa · nipy/nibabel · GitHub.
Why does the allocation pattern appear to change with dtype, and why does it look like there is an allocation for the data array twice?
Command used (and if a helper script was used, a link to the helper script or the command generated):
# data dowloaded with nilearn,
# but the import can hide the parts below
# from nilearn import datasets
# datasets.fetch_adhd(n_subjects=1)
import nibabel as nb
# from fetch_adhd
nii = nb.nifti1.Nifti1Image.load(
"/home/psadil/nilearn_data/adhd/data/0010042/0010042_rest_tshift_RPI_voreg_mni.nii.gz"
)
# np.float32 results in two allocations, but not np.float64
# nii = nii.get_fdata(dtype=np.float32)
nii = nii.get_fdata(dtype=np.float64)
Put the above in main.py and check with memray
memray run -o out.bin main.py
memray flamegraph out.bin
Version:
>>> import nibabel as nb
>>> nb.__version__
'5.3.2'
Environment (Docker, Singularity / Apptainer, custom installation):
mamba env
channels:
- conda-forge
dependencies:
- _libgcc_mutex=0.1=conda_forge
- _openmp_mutex=4.5=2_gnu
- anyio=4.8.0=pyhd8ed1ab_0
- argon2-cffi=23.1.0=pyhd8ed1ab_1
- argon2-cffi-bindings=21.2.0=py313h536fd9c_5
- arrow=1.3.0=pyhd8ed1ab_1
- asttokens=3.0.0=pyhd8ed1ab_1
- async-lru=2.0.4=pyhd8ed1ab_1
- attrs=24.3.0=pyh71513ae_0
- babel=2.16.0=pyhd8ed1ab_1
- beautifulsoup4=4.12.3=pyha770c72_1
- bleach=6.2.0=pyhd8ed1ab_3
- bleach-with-css=6.2.0=hd8ed1ab_3
- brotli-python=1.1.0=py313h46c70d0_2
- bzip2=1.0.8=h4bc722e_7
- c-ares=1.34.4=hb9d3cd8_0
- ca-certificates=2024.12.14=hbcca054_0
- cached-property=1.5.2=hd8ed1ab_1
- cached_property=1.5.2=pyha770c72_1
- certifi=2024.12.14=pyhd8ed1ab_0
- cffi=1.17.1=py313hfab6e84_0
- charset-normalizer=3.4.1=pyhd8ed1ab_0
- comm=0.2.2=pyhd8ed1ab_1
- debugpy=1.8.11=py313h46c70d0_0
- decorator=5.1.1=pyhd8ed1ab_1
- defusedxml=0.7.1=pyhd8ed1ab_0
- elfutils=0.192=h7f4e02f_1
- entrypoints=0.4=pyhd8ed1ab_1
- exceptiongroup=1.2.2=pyhd8ed1ab_1
- executing=2.1.0=pyhd8ed1ab_1
- fqdn=1.5.1=pyhd8ed1ab_1
- gettext=0.22.5=he02047a_3
- gettext-tools=0.22.5=he02047a_3
- gnutls=3.8.8=h2d3e045_0
- h11=0.14.0=pyhd8ed1ab_1
- h2=4.1.0=pyhd8ed1ab_1
- hpack=4.0.0=pyhd8ed1ab_1
- httpcore=1.0.7=pyh29332c3_1
- httpx=0.28.1=pyhd8ed1ab_0
- hyperframe=6.0.1=pyhd8ed1ab_1
- idna=3.10=pyhd8ed1ab_1
- importlib-metadata=8.5.0=pyha770c72_1
- importlib_resources=6.5.2=pyhd8ed1ab_0
- ipykernel=6.29.5=pyh3099207_0
- ipython=8.31.0=pyh707e725_0
- ipywidgets=8.1.5=pyhd8ed1ab_1
- isoduration=20.11.0=pyhd8ed1ab_1
- jedi=0.19.2=pyhd8ed1ab_1
- jinja2=3.1.5=pyhd8ed1ab_0
- joblib=1.4.2=pyhd8ed1ab_1
- json5=0.10.0=pyhd8ed1ab_1
- jsonpointer=3.0.0=py313h78bf25f_1
- jsonschema=4.23.0=pyhd8ed1ab_1
- jsonschema-specifications=2024.10.1=pyhd8ed1ab_1
- jsonschema-with-format-nongpl=4.23.0=hd8ed1ab_1
- jupyter=1.1.1=pyhd8ed1ab_1
- jupyter-lsp=2.2.5=pyhd8ed1ab_1
- jupyter_client=8.6.3=pyhd8ed1ab_1
- jupyter_console=6.6.3=pyhd8ed1ab_1
- jupyter_core=5.7.2=pyh31011fe_1
- jupyter_events=0.11.0=pyhd8ed1ab_0
- jupyter_server=2.15.0=pyhd8ed1ab_0
- jupyter_server_terminals=0.5.3=pyhd8ed1ab_1
- jupyterlab=4.3.4=pyhd8ed1ab_0
- jupyterlab_pygments=0.3.0=pyhd8ed1ab_2
- jupyterlab_server=2.27.3=pyhd8ed1ab_1
- jupyterlab_widgets=3.0.13=pyhd8ed1ab_1
- keyutils=1.6.1=h166bdaf_0
- krb5=1.21.3=h659f571_0
- ld_impl_linux-64=2.43=h712a8e2_2
- libarchive=3.7.7=hadbb8c3_0
- libasprintf=0.22.5=he8f35ee_3
- libasprintf-devel=0.22.5=he8f35ee_3
- libblas=3.9.0=26_linux64_openblas
- libcblas=3.9.0=26_linux64_openblas
- libcurl=8.11.1=h332b0f4_0
- libedit=3.1.20240808=pl5321h7949ede_0
- libev=4.33=hd590300_2
- libexpat=2.6.4=h5888daf_0
- libffi=3.4.2=h7f98852_5
- libgcc=14.2.0=h77fa898_1
- libgcc-ng=14.2.0=h69a702a_1
- libgettextpo=0.22.5=he02047a_3
- libgettextpo-devel=0.22.5=he02047a_3
- libgfortran=14.2.0=h69a702a_1
- libgfortran5=14.2.0=hd5240d6_1
- libgomp=14.2.0=h77fa898_1
- libiconv=1.17=hd590300_2
- libidn2=2.3.7=hd590300_0
- liblapack=3.9.0=26_linux64_openblas
- liblzma=5.6.3=hb9d3cd8_1
- liblzma-devel=5.6.3=hb9d3cd8_1
- libmicrohttpd=1.0.1=hbc5bc17_1
- libmpdec=4.0.0=h4bc722e_0
- libnghttp2=1.64.0=h161d5f1_0
- libopenblas=0.3.28=pthreads_h94d23a6_1
- libsodium=1.0.20=h4ab18f5_0
- libsqlite=3.47.2=hee588c1_0
- libssh2=1.11.1=hf672d98_0
- libstdcxx=14.2.0=hc0a3c3a_1
- libstdcxx-ng=14.2.0=h4852527_1
- libtasn1=4.19.0=h166bdaf_0
- libunistring=0.9.10=h7f98852_0
- libunwind=1.6.2=h9c3ff4c_0
- libuuid=2.38.1=h0b41bf4_0
- libxml2=2.13.5=h0d44e9d_1
- libxslt=1.1.39=h76b75d6_0
- libzlib=1.3.1=hb9d3cd8_2
- linkify-it-py=2.0.3=pyhd8ed1ab_1
- lxml=5.3.0=py313h6eb7059_2
- lz4-c=1.9.4=hcb278e6_0
- lzo=2.10=hd590300_1001
- markdown-it-py=3.0.0=pyhd8ed1ab_1
- markupsafe=3.0.2=py313h8060acc_1
- matplotlib-inline=0.1.7=pyhd8ed1ab_1
- mdit-py-plugins=0.4.2=pyhd8ed1ab_1
- mdurl=0.1.2=pyhd8ed1ab_1
- memray=1.15.0=py313h272dd17_0
- mistune=3.1.0=pyhd8ed1ab_0
- nbclient=0.10.2=pyhd8ed1ab_0
- nbconvert-core=7.16.5=pyhd8ed1ab_1
- nbformat=5.10.4=pyhd8ed1ab_1
- ncurses=6.5=he02047a_1
- nest-asyncio=1.6.0=pyhd8ed1ab_1
- nettle=3.9.1=h7ab15ed_0
- nibabel=5.3.2=pyha770c72_1
- nilearn=0.11.1=pyhd8ed1ab_0
- notebook=7.3.2=pyhd8ed1ab_0
- notebook-shim=0.2.4=pyhd8ed1ab_1
- numpy=2.2.1=py313hb30382a_0
- openssl=3.4.0=h7b32b05_1
- overrides=7.7.0=pyhd8ed1ab_1
- p11-kit=0.24.1=hc5aa10d_0
- packaging=24.2=pyhd8ed1ab_2
- pandas=2.2.3=py313ha87cce1_1
- pandocfilters=1.5.0=pyhd8ed1ab_0
- parso=0.8.4=pyhd8ed1ab_1
- pexpect=4.9.0=pyhd8ed1ab_1
- pickleshare=0.7.5=pyhd8ed1ab_1004
- pip=24.3.1=pyh145f28c_2
- pkgutil-resolve-name=1.3.10=pyhd8ed1ab_2
- platformdirs=4.3.6=pyhd8ed1ab_1
- prometheus_client=0.21.1=pyhd8ed1ab_0
- prompt-toolkit=3.0.48=pyha770c72_1
- prompt_toolkit=3.0.48=hd8ed1ab_1
- psutil=6.1.1=py313h536fd9c_0
- ptyprocess=0.7.0=pyhd8ed1ab_1
- pure_eval=0.2.3=pyhd8ed1ab_1
- pycparser=2.22=pyh29332c3_1
- pygments=2.19.1=pyhd8ed1ab_0
- pysocks=1.7.1=pyha55dd90_7
- python=3.13.1=ha99a958_103_cp313
- python-dateutil=2.9.0.post0=pyhff2d567_1
- python-fastjsonschema=2.21.1=pyhd8ed1ab_0
- python-json-logger=2.0.7=pyhd8ed1ab_0
- python-tzdata=2024.2=pyhd8ed1ab_1
- python_abi=3.13=5_cp313
- pytz=2024.1=pyhd8ed1ab_0
- pyyaml=6.0.2=py313h536fd9c_1
- pyzmq=26.2.0=py313h8e95178_3
- readline=8.2=h8228510_1
- referencing=0.35.1=pyhd8ed1ab_1
- requests=2.32.3=pyhd8ed1ab_1
- rfc3339-validator=0.1.4=pyhd8ed1ab_1
- rfc3986-validator=0.1.1=pyh9f0ad1d_0
- rich=13.9.4=pyhd8ed1ab_1
- rpds-py=0.22.3=py313h920b4c0_0
- scikit-learn=1.6.0=py313h8ef605b_0
- scipy=1.15.0=py313hc93385a_0
- send2trash=1.8.3=pyh0d859eb_1
- setuptools=75.6.0=pyhff2d567_1
- six=1.17.0=pyhd8ed1ab_0
- sniffio=1.3.1=pyhd8ed1ab_1
- soupsieve=2.5=pyhd8ed1ab_1
- stack_data=0.6.3=pyhd8ed1ab_1
- terminado=0.18.1=pyh0d859eb_0
- textual=1.0.0=pyhd8ed1ab_0
- threadpoolctl=3.5.0=pyhc1e730c_0
- tinycss2=1.4.0=pyhd8ed1ab_0
- tk=8.6.13=noxft_h4845f30_101
- tomli=2.2.1=pyhd8ed1ab_1
- tornado=6.4.2=py313h536fd9c_0
- traitlets=5.14.3=pyhd8ed1ab_1
- types-python-dateutil=2.9.0.20241206=pyhd8ed1ab_0
- typing-extensions=4.12.2=hd8ed1ab_1
- typing_extensions=4.12.2=pyha770c72_1
- typing_utils=0.1.0=pyhd8ed1ab_1
- tzdata=2024b=hc8b5060_0
- uc-micro-py=1.0.3=pyhd8ed1ab_1
- uri-template=1.3.0=pyhd8ed1ab_1
- urllib3=2.3.0=pyhd8ed1ab_0
- wcwidth=0.2.13=pyhd8ed1ab_1
- webcolors=24.11.1=pyhd8ed1ab_0
- webencodings=0.5.1=pyhd8ed1ab_3
- websocket-client=1.8.0=pyhd8ed1ab_1
- widgetsnbextension=4.0.13=pyhd8ed1ab_1
- xz=5.6.3=hbcc6ac9_1
- xz-gpl-tools=5.6.3=hbcc6ac9_1
- xz-tools=5.6.3=hb9d3cd8_1
- yaml=0.2.5=h7f98852_2
- zeromq=4.3.5=h3b0a872_7
- zipp=3.21.0=pyhd8ed1ab_1
- zstandard=0.23.0=py313h80202fe_1
- zstd=1.5.6=ha6fb4c9_0
Data formatted according to a validatable standard? Please provide the output of the validator:
na
Relevant log outputs (up to 20 lines):
na
Screenshots / relevant information:
Note: that sample image has dtype float32 with shape (61, 73, 61, 176)
np.float32
np.float64