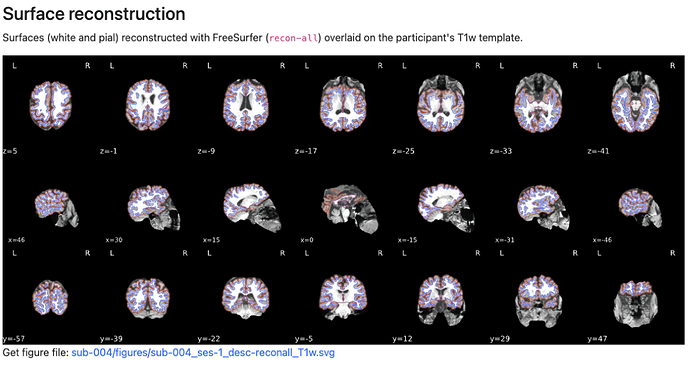
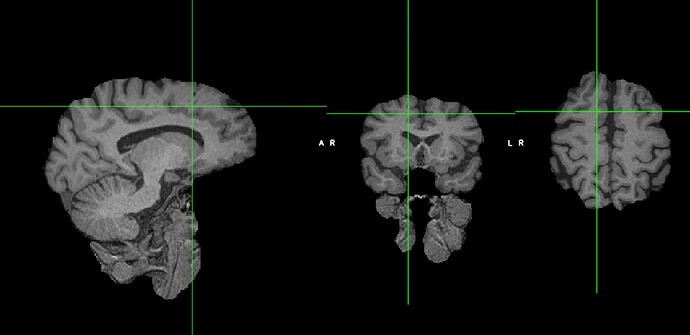
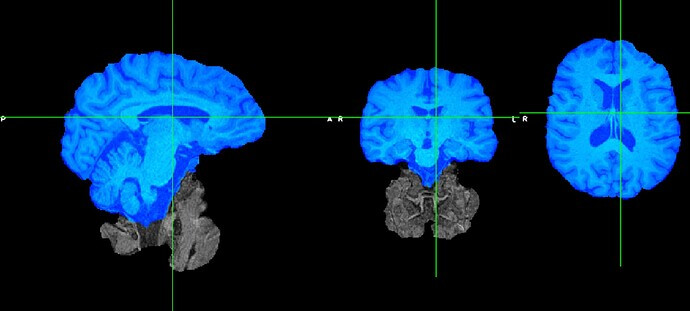
(so it looks like the fmriprep reconstructed image)
And then I run another brain extraction on that 1st round of BET extraction and it’s cleaned up (below I took a screenshot of the 2nd extracted brain in blue overlaying the first extracted brain).
So, I think I would like to use this second pre-skullstripped T1 image but I’m not sure where/which folder to put this image into so that fmriprep knows to use it. Any insight/suggestions would be helpful! Let me know if I can provide clarifying information.
Thank you!
edit: Oh, if it’s important, this is a brain that has lesions so I’ve included the lesion_roi.nii.gz image in their Nifti/anat folder along with their T1w, T2w, and FLAIR images.
I’ve used 21.0.1 to run all other subjects so I’m wary and would like to avoid using the latest version on just one subject, but would welcome thoughts on this too if it’s the only solution.
I have reformatted your post to include the Software Support post template. In future posts, please use this template. There is some information that is missing from your post, such as BIDS validation and your code. Knowing this may help us debug.
You can put these images in your anat folder (perhaps using the rec-XX label to indicate already skull stripped) and use the fmriprep option to skip skull stripping if you are happy with it (--skull-strip-t1w skip). Just make sure you use something like a BIDS filter file to tell fmriprep to only use the skull stripped images.
Thank you, Steven!
Apologies for missing the template info. The data was formatted according to a validatable standard. I’m not sure where to find the output of the validator though to include here.
I am new to this so I also apologize for the following questions -
Could you link me to the documentation on what the rec-XX label should be? I’ve tried looking and am not able to find it yet. Similarly, with BIDS filter file, I’m reading through the documentation (FAQ - Frequently Asked Questions — fmriprep version documentation) and to confirm, I should add the --bids-filter-file flag in my command? Would you be able to give an example of what the input should look like?